







简介:内容为基础的图像检索(CBIR)技术是计算机视觉和图像处理的核心技术之一,特别适用于未标注或少标注的大规模图像数据库。MATLAB提供了一个高效环境来构建CBIR系统原型,集成了图像特征提取、降维、聚类和相似性度量等工具。本项目详细介绍了使用MATLAB实现CBIR系统的各个阶段,包括特征提取、编码表示、相似性度量、索引检索和结果评估,并重点关注形状索引技术,利用多种形状描述子以提高检索精度。文档中包含实践细节和性能评估,为图像检索领域的研究人员和学生提供了深入学习和实践的机会。 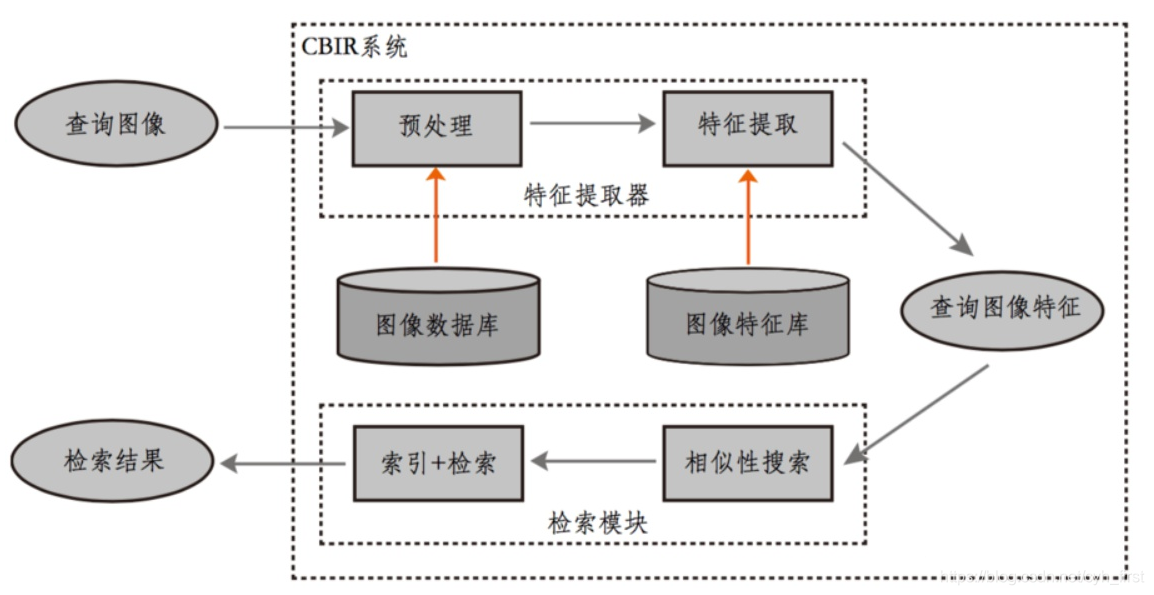
1. CBIR的基本概念及应用
1.1 CBIR的定义与重要性
内容检索(Content-Based Image Retrieval,CBIR),也称为基于内容的图像检索,是计算机视觉与图像处理领域的关键技术之一。它允许用户通过图像的内容而非传统的文本标签来检索图片,这一特性在海量图像数据处理中显得尤为重要。CBIR技术通过从图像中提取视觉特征,如颜色、纹理、形状等,并利用这些特征作为索引来实现高效的图像检索。
1.2 CBIR的基本工作原理
CBIR系统的工作原理可以简化为几个主要步骤。首先是对图像的预处理,包括颜色空间转换、尺寸归一化等,以便于后续处理。其次是特征提取,将图像的内容转换为一系列可量化的特征描述符,如直方图、Gabor滤波器响应等。然后是特征匹配,通过计算查询图像与数据库中图像的特征相似度,找出最匹配的结果。最后,通过相关反馈机制不断优化检索结果,提升用户体验。
1.3 CBIR的应用场景
CBIR技术在各个领域都有广泛的应用。在医疗影像分析中,CBIR可以帮助医生快速检索相似病例图像,辅助诊断;在安防监控领域,CBIR可以用于人脸识别、行为分析;在电子商务中,用户可以通过上传图片找到相似的商品;而在社交媒体平台,CBIR可以用于相似图片的自动标记等。随着机器学习和人工智能技术的发展,CBIR的应用将更加深入和广泛。
2. MATLAB在CBIR系统构建中的运用
2.1 MATLAB简介及其在图像处理中的优势
2.1.1 MATLAB软件概述
MATLAB是一种高性能的数值计算环境和第四代编程语言,由MathWorks公司开发。它广泛应用于工程计算、数据分析、算法开发和图形可视化等领域。MATLAB的一个显著特点是它拥有强大的矩阵处理能力和丰富的内置函数库,这使得它在图像处理和计算机视觉的研究和应用中独树一帜。
2.1.2 MATLAB在图像处理领域的应用特点
在图像处理领域,MATLAB提供了广泛的图像处理工具箱,这些工具箱集成了许多用于图像分析、增强、滤波、变换、分割、特征提取和形态学操作等的函数。MATLAB的图像处理工具箱支持多种图像格式,并允许用户直接从MATLAB环境中访问和操作图像数据。此外,MATLAB允许快速原型开发和算法验证,并可以通过MATLAB Coder将其转换为C/C++代码,以用于生产环境。
2.2 MATLAB在CBIR系统中的开发步骤
2.2.1 系统设计与规划
在设计CBIR系统时,首先需要明确系统的目标和需求。这包括确定图像数据集的类型、大小、特征及如何组织数据,以及评估系统的性能指标。CBIR系统的构建需要经过以下几个主要阶段:需求分析、系统设计、算法实现、系统测试和部署。
2.2.2 MATLAB环境搭建与工具箱介绍
在MATLAB环境中搭建CBIR系统的第一步是安装并配置MATLAB软件和相关工具箱。常用的工具箱包括Image Processing Toolbox、Statistics and Machine Learning Toolbox、Computer Vision Toolbox等。这些工具箱包含了大量预定义函数,可以简化图像处理和机器学习算法的开发过程。
2.2.3 图像预处理与特征提取
图像预处理是CBIR系统中不可或缺的一步,其目的是为了提高图像质量,减少噪声,突出图像特征等。预处理包括灰度转换、滤波、直方图均衡化等。在预处理之后,系统将进行特征提取,这是CBIR系统的核心环节。特征提取过程会从图像中提取关键信息,如颜色、纹理、形状等,以便进行后续的比较和检索。
代码块示例
MATLAB代码块用于实现图像的灰度转换和直方图均衡化:
% 读取图像
originalImage = imread('example.jpg');
% 转换为灰度图像
grayImage = rgb2gray(originalImage);
% 直方图均衡化增强图像对比度
equalizedImage = histeq(grayImage);
% 显示原始图像和处理后的图像
subplot(1, 2, 1);
imshow(originalImage);
title('Original Image');
subplot(1, 2, 2);
imshow(equalizedImage);
title('Equalized Image');
参数说明与逻辑分析
上述代码首先使用 imread 函数读取图像文件,并将其存储在变量 originalImage 中。然后, rgb2gray 函数将彩色图像转换为灰度图像,并存储在变量 grayImage 中。接下来, histeq 函数用于对灰度图像进行直方图均衡化处理,从而增强图像的对比度,结果存储在 equalizedImage 变量中。最后, subplot 和 imshow 函数用于在同一窗口内显示原始图像和经过处理的图像,以便进行视觉比较。
以上步骤展示了如何在MATLAB环境中进行基本的图像处理操作。CBIR系统构建中的图像预处理和特征提取是更复杂的过程,需要结合具体需求,选择合适的图像处理和特征提取方法。在下一节中,我们将深入探讨具体的图像特征提取技术。
3. 图像特征提取技术
在本章中,我们将深入了解CBIR系统中核心环节之一:图像特征提取技术。特征提取是将图像转换为可以进行有效比较的数值向量的过程。这些数值向量能够捕捉图像的内在属性,如色彩、纹理、形状和结构,使得计算机可以理解图像内容的语义。本章将详细介绍色彩、纹理、形状和结构这四大类特征提取技术。
3.1 色彩特征的提取
色彩是图像最基本的特征之一,色彩特征的提取主要是用来描述图像的颜色分布情况。
3.1.1 颜色直方图与颜色矩
颜色直方图是一个统计图表,用于显示不同颜色在图像中出现的频率。它是图像内容最直接的表达形式。颜色直方图不考虑像素的位置信息,仅记录每个颜色的像素数。
% MATLAB代码示例:使用颜色直方图来表示图像
I = imread('example.jpg'); % 读取图像文件
I = rgb2gray(I); % 转换为灰度图像
figure, imshow(I); % 显示图像
[counts, x] = imhist(I); % 计算并显示直方图
bar(x,counts); % 直方图可视化
在上述代码中,首先使用 imread 函数读取图像,然后使用 rgb2gray 转换为灰度图像,以便于处理。 imhist 函数计算图像直方图并显示。
颜色矩是另一种简单的颜色特征提取方法,它通过计算图像颜色的统计矩(如均值、标准差、偏斜度和峰度)来描述图像的颜色分布。颜色矩不需要考虑颜色分布的具体形状,因此计算速度快。
% MATLAB代码示例:计算图像的颜色矩
I = imread('example.jpg'); % 读取图像文件
I = rgb2gray(I); % 转换为灰度图像
meanColor = mean(I(:)); % 计算平均值
stdColor = std(I(:)); % 计算标准差
skewnessColor = skewness(I(:)); % 计算偏斜度
kurtosisColor = kurtosis(I(:)); % 计算峰度
3.1.2 颜色空间转换与色彩描述
除了颜色直方图和颜色矩,颜色空间转换也是常用的色彩特征提取方法之一。常见的颜色空间包括HSV、YCbCr等。在这些颜色空间中,颜色分量之间具有更好的独立性,有利于后续的颜色特征提取。
% MATLAB代码示例:将RGB图像转换为HSV颜色空间
I = imread('example.jpg'); % 读取图像文件
I_hsv = rgb2hsv(I); % 转换为HSV颜色空间
figure, imshow(I_hsv); % 显示转换后的图像
转换到HSV颜色空间后,可以基于H分量(色调)和S分量(饱和度)来提取颜色特征。
3.2 纹理特征的提取
纹理特征的提取用于描述图像中纹理的视觉特征,如粗细、对比度、方向性等。
3.2.1 纹理分析理论基础
在纹理特征提取中,灰度共生矩阵(GLCM)是一种常用的方法。GLCM通过分析图像中像素灰度之间的关系来表达纹理特征。
% MATLAB代码示例:计算灰度共生矩阵(GLCM)
I = imread('example.jpg'); % 读取图像文件
I = im2gray(I); % 转换为灰度图像
glcm = graycomatrix(I, 'Offset', [1 0]); % 计算GLCM
figure, imagesc(glcm); % 显示GLCM图像
3.2.2 纹理特征描述子实例
基于GLCM,我们可以计算一系列纹理特征描述子,如能量、对比度、同质性、熵等。
% MATLAB代码示例:计算GLCM纹理特征描述子
glcm = graycomatrix(I, 'Offset', [1 0]); % 计算GLCM
stats = graycoprops(glcm, {'contrast', 'homogeneity', 'energy', 'correlation'}); % 计算纹理特征描述子
3.3 形状特征的提取
形状特征是描述图像中物体形状的关键特征,常用于目标识别和图像分割。
3.3.1 形状描述子与特征选择
形状描述子通过量化图像中物体的形状特性来表征形状,常见的形状描述子包括轮廓基描述子、区域描述子等。
% MATLAB代码示例:提取图像轮廓并使用轮廓基描述子
I = imread('example.jpg'); % 读取图像文件
BW = imbinarize(I); % 二值化处理
[B,L] = bwboundaries(BW,'noholes'); % 提取轮廓
figure, imshow(label2rgb(L,@jet,[.5 .5 .5])) % 显示轮廓
3.3.2 形状特征提取方法
形状特征提取方法包括边缘检测、霍夫变换、几何矩等。这些方法能够帮助我们获取图像中物体的形状信息。
% MATLAB代码示例:使用霍夫变换检测图像中的直线
I = imread('example.jpg'); % 读取图像文件
BW = edge(I, 'canny'); % 使用Canny算子进行边缘检测
[H, theta, rho] = hough(BW); % 霍夫变换检测直线
figure, imshow(I, cmap='gray'); hold on; % 显示图像
plot(theta, rho, 'LineWidth', 2, 'Color', 'green'); % 显示检测结果
hold off;
3.4 结构特征的提取
结构特征描述了图像中物体的几何和拓扑结构,是高层次的图像表示。
3.4.1 图像分割与区域描述
图像分割是将图像分割成多个有意义的区域,如基于边缘的分割、基于阈值的分割、区域生长等。分割后的区域可以用来描述图像的结构特征。
% MATLAB代码示例:使用区域生长进行图像分割
I = imread('example.jpg'); % 读取图像文件
BW = imsegfmm(I, seeds, mask); % 区域生长函数
figure, imshow(label2rgb(BW, @jet, [.5 .5 .5])) % 显示分割结果
3.4.2 结构特征的高级描述方法
除了基于分割的方法,还可以使用形态学特征描述、语义模型等高级结构特征提取方法。
% MATLAB代码示例:使用形态学特征描述
I = imread('example.jpg'); % 读取图像文件
se = strel('disk', 3); % 创建结构元素
I_dilated = imdilate(I, se); % 膨胀运算
figure, imshow(I_dilated); % 显示膨胀后的图像
通过上述方法,我们可以提取出图像的结构特征,为高级图像分析和处理提供基础。
通过本章节的介绍,我们逐步了解了CBIR系统中图像特征提取技术的各个方面。在下一章节中,我们将深入探讨特征编码与表示方法,以进一步将提取出的特征转换为便于计算机处理和检索的形式。
4. 特征编码与表示方法
4.1 Bag of Words模型(BoW)
4.1.1 BoW模型的基本原理
Bag of Words(BoW)模型是CBIR系统中的一种常用特征编码技术,来源于文本处理领域中的“词袋”概念。BoW模型的核心思想是忽略文本(或图像)中单词(或视觉词)的顺序,只考虑其出现频率。在图像处理中,可以将图像的视觉词汇视为单词,通过统计这些词汇的频率来表征图像内容。
BoW模型的处理流程通常包括以下步骤:
- 特征提取 :首先从图像中提取关键点或区域特征(如SIFT特征)。
- 聚类 :使用K-means等聚类算法对提取的特征进行聚类,形成词汇表。
- 量化 :将图像中的特征向量化,即用词汇表中的词汇来表示每个特征。
- 构建直方图 :最后,统计每个视觉词汇在图像中的出现频率,形成一个直方图,作为图像的特征描述。
4.1.2 BoW在CBIR中的应用实例
假设我们已经拥有一个包含多个图像的数据库,我们希望实现一个基于BoW的图像检索系统。这里以SIFT特征和K-means聚类为例,展示如何应用BoW模型:
-
SIFT特征提取 :遍历数据库中的每张图片,使用SIFT算法提取关键点和对应的描述子。
python import cv2 import numpy as np def extract_sift_features(image_path): image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE) sift = cv2.SIFT_create() keypoints, descriptors = sift.detectAndCompute(image, None) return keypoints, descriptors # 示例使用 keypoints, descriptors = extract_sift_features("path_to_image.jpg") -
聚类 :应用K-means算法将所有图像的描述子聚类,创建视觉词汇表。
python from sklearn.cluster import KMeans def create_visual_codebook(descriptors, num_clusters=100): kmeans = KMeans(n_clusters=num_clusters, random_state=0).fit(descriptors) vocabulary = kmeans.cluster_centers_ return vocabulary vocabulary = create_visual_codebook(descriptors)
- 量化 :用词汇表量化每张图片的特征。
python def quantize_descriptors(descriptors, vocabulary): vocabulary_size = vocabulary.shape[0] quantized_descriptors = np.zeros((len(descriptors), vocabulary_size)) for i, descriptor in enumerate(descriptors): distances = np.linalg.norm(vocabulary - descriptor, axis=1) min_index = np.argmin(distances) quantized_descriptors[i][min_index] = 1 return quantized_descriptors quantized_descriptors = quantize_descriptors(descriptors, vocabulary)
- 构建直方图 :最后,为每张图片构建一个特征直方图。
python def build_histogram(quantized_descriptors): histogram = np.sum(quantized_descriptors, axis=0) histogram /= np.linalg.norm(histogram) return histogram histogram = build_histogram(quantized_descriptors)
通过上述步骤,每张图片都被转换为了一个特征直方图,可以用来进行图像之间的相似性度量和检索。
5. 相似性度量与索引检索技术
5.1 相似性度量技术
5.1.1 欧氏距离与曼哈顿距离
在处理图像搜索问题时,相似性度量是CBIR系统的核心,其决定了检索结果的相关性和准确性。欧氏距离和曼哈顿距离是两种最常用的度量方式,广泛应用于各种图像检索算法中。
欧氏距离 是最直观的距离度量方法,表示在多维空间中两点之间的直线距离。在二维空间中,两点的欧氏距离为两点之间的直线段长度,公式为:
[ d(p, q) = \sqrt{(p_1 - q_1)^2 + (p_2 - q_2)^2} ]
其中,( p ) 和 ( q ) 分别为多维空间中的两点,( p_1, p_2, q_1, q_2 ) 分别为这两点的坐标值。
曼哈顿距离 在图像处理中也有重要应用,表示在标准坐标系的网格上,从一个点到另一个点的路径长度,这个长度是各坐标差的绝对值之和。在二维空间中,两点间的曼哈顿距离计算公式为:
[ d(p, q) = |p_1 - q_1| + |p_2 - q_2| ]
这两种距离度量方法各有优势,通常取决于应用场景。例如,欧氏距离因其直观性而在图像的几何形状相似性度量中使用较多,而曼哈顿距离因其对坐标轴的平移不变性,在处理图像的局部特征时也表现出其独特性。
5.1.2 余弦相似度与Jaccard相似度
除了欧氏距离和曼哈顿距离外, 余弦相似度 在处理高维空间中的特征向量时特别有用,如文本处理和图像检索。余弦相似度衡量的是两个向量间的夹角大小,其值介于-1和1之间,当值为1时表示方向完全相同,为-1时表示方向完全相反。在图像处理中,常用其来衡量图像特征向量的相似性。
余弦相似度的计算公式为:
[ \text{similarity} = \cos(\theta) = \frac{A \cdot B}{\|A\|\|B\|} = \frac{\sum\limits_{i=1}^{n} A_i \times B_i}{\sqrt{\sum\limits_{i=1}^{n} A_i^2} \times \sqrt{\sum\limits_{i=1}^{n} B_i^2}} ]
其中,( A ) 和 ( B ) 表示两个向量,( A_i ) 和 ( B_i ) 表示向量中的元素,( \theta ) 表示两向量之间的夹角。
Jaccard相似度 是衡量样本集合相似度的一种度量方法,特别适用于布尔型数据。在图像检索中,Jaccard相似度可以用来衡量两个集合的相似度,即交集大小与并集大小的比例。Jaccard相似度的公式为:
[ J(A, B) = \frac{|A \cap B|}{|A \cup B|} ]
其中,( A ) 和 ( B ) 表示两个集合。Jaccard相似度的值介于0到1之间,1表示完全相同,0表示完全不同。
在实际应用中,选择哪种相似性度量方法取决于数据的特性以及具体的应用场景。例如,在图像检索中,余弦相似度往往能够更好地处理向量化的特征数据,而Jaccard相似度则可能更适合处理图像中的局部区域特征。
5.2 索引与检索技术
5.2.1 倒排索引与K-d树
在CBIR系统中,为了提高检索效率和处理大规模图像库的能力,索引技术变得尤为重要。其中,倒排索引和K-d树是两种主要的索引结构,广泛应用于图像检索系统中。
倒排索引 是一种索引方法,主要用于快速检索具有某些属性的记录,其结构与书后的索引类似,索引项是属性值,记录索引项指向的是包含该属性值的所有记录。在图像检索中,倒排索引可以用来快速定位包含特定特征的图像。
实现倒排索引的关键在于特征提取和索引构建,这通常包括以下步骤:
- 特征提取:提取每张图像的特征。
- 特征向量化:将特征转化为可以进行数学计算的形式。
- 索引构建:建立从特征到图像的映射关系。
倒排索引在处理大规模数据库时能够快速返回查询结果,但它也有局限性,如不支持范围查询。
K-d树 (K-dimensional tree)是一种用于组织点在K维空间中的数据结构,允许有效的范围和近邻搜索。K-d树通过递归地将数据分割成K个维度来建立树形结构,这样可以快速地对点进行搜索。
K-d树构建过程通常包括以下步骤:
- 选择一个维度,并按这个维度的值将数据集分成两部分,创建树的一个节点。
- 递归地对每一部分进行分割,直到满足某些停止条件(如节点包含的点数量小于某个阈值)。
在图像检索中,使用K-d树可以快速定位与查询图像相似的图像。然而,它在处理不平衡数据集时可能会降低性能,因此在使用前需要评估数据的分布。
5.2.2 聚类与FLANN快速近似最近邻搜索
为了进一步提高检索速度,聚类算法和FLANN(Fast Library for Approximate Nearest Neighbors)是两种常用的检索技术。聚类能够将相似的图像分到同一个群组中,减少检索时的范围,而FLANN提供了一种快速的近似最近邻搜索方法。
聚类算法 是一种无监督学习算法,用于将数据集中的数据点根据相似性分为多个簇。在图像检索中,聚类可以用于分组相似的图像,从而在检索时仅对相关的簇进行搜索。
FLANN 是一种基于聚类的快速近似最近邻搜索库,它可以处理海量数据集的快速搜索问题。FLANN通过快速选择合适的算法和参数,为不同的数据和查询提供高效的近似最近邻搜索。
使用FLANN的优势在于其对高维数据有较好的搜索性能,这在图像特征向量的检索中尤其重要。FLANN通过预处理数据并建立相应的索引结构,能够在极短的时间内返回近似的最近邻点,从而极大地提高了检索效率。
在实际应用中,这些技术经常结合使用。例如,可以先使用聚类算法对图像数据库进行预处理,将图像划分为多个簇,然后在每个簇内使用FLANN进行快速搜索,这样可以同时保证检索的速度和准确性。
在下一节中,我们将深入探讨如何将这些相似性度量和索引检索技术应用于具体的图像检索系统,并展示如何通过这些技术实现高效和准确的图像检索。
6. CBIR系统性能评估与形状索引应用
在上一章节中,我们探讨了特征编码与表示方法,以及相似性度量与索引检索技术,这些都为构建一个功能完善的CBIR系统奠定了基础。本章将详细介绍CBIR系统性能评估指标和形状索引的应用,进一步提升系统检索的精确度和效率。
6.1 CBIR系统性能评估指标
要确保CBIR系统的有效性,必须对其进行严格的性能评估。评估指标包括精确率、召回率和F1分数,它们是度量检索系统性能的关键指标。
6.1.1 精确率、召回率与F1分数
精确率(Precision)是指检索返回的相关图像数量与所有返回图像数量的比例。召回率(Recall)则是检索返回的相关图像数量与数据库中所有相关图像数量的比例。F1分数是精确率和召回率的调和平均值,用以平衡两者之间的权衡。
在实际应用中,评估一个CBIR系统时,我们通常会通过测试集给出一系列查询图像,然后计算每一项指标。具体计算公式如下:
- 精确率(Precision)= 相关图像检索数 / 检索总数
- 召回率(Recall)= 相关图像检索数 / 数据库中相关图像总数
- F1分数 = 2 * (精确率 * 召回率) / (精确率 + 召回率)
通过这些指标,我们可以量化评估CBIR系统的检索性能,并进行优化。
6.1.2 ROC曲线与AUC值
接收者操作特征曲线(ROC)和ROC曲线下面积(AUC)是评估二分类系统性能的另一种有效方法。ROC曲线通过展示不同阈值下的真正例率(召回率)和假正例率,为我们提供了一个系统的整体表现视图。
AUC值是ROC曲线下的面积,它的取值范围从0到1。AUC值越高,代表系统性能越好。当AUC值接近1时,表示系统有很高的准确性;接近0.5时,表示系统的性能和随机猜测没有区别。
6.2 形状索引的重要性及主要描述子
形状索引是CBIR系统中用来描述图像形状特征的一组数值。通过形状索引,可以快速地从大型图像数据库中检索出与查询图像相似形状的图像。形状索引在图像检索中的重要性不言而喻,因为它能够帮助我们更精确地定位目标图像。
6.2.1 Hu矩与Zernike矩的介绍
Hu矩是由美国工程师M.K.Hu在1962年提出的形状描述符。它基于图像的几何不变性,能够提供形状的大小、位置和旋转信息。Hu矩是通过计算图像的中心矩得到,具有平移、旋转和尺度不变性,这使得Hu矩在图像检索中非常有用。
Zernike矩是另一种常用的形状描述子,由荷兰物理学家Frits Zernike提出。Zernike矩是在单位圆盘上定义的,具有更好的几何不变性,特别适合描述具有复杂形状的图像。Zernike矩计算复杂度较高,但提供比Hu矩更丰富的形状特征。
6.2.2 形状索引在CBIR中的作用与影响
形状索引在CBIR系统中的作用是显著的,特别是在图像检索中,它能够有效地捕捉到图像的形状特征。通过对形状索引的计算和匹配,系统能够快速地从数据库中检索出形状相似的图像,极大地提高了检索效率。
形状索引的引入影响着系统的设计,开发者可以根据需求选择合适的形状描述子,优化算法和数据库结构,从而实现更为精确的图像检索。
6.3 形状索引的实现方法与应用
形状索引的构建对于提高CBIR系统的检索效果至关重要。在本小节中,我们将探讨形状索引的构建方法,并通过实际案例分析其在图像检索中的应用。
6.3.1 形状索引的构建方法
形状索引的构建通常需要经过以下几个步骤:
- 图像预处理:包括图像的二值化、去噪、边缘检测等。
- 特征点提取:使用诸如边缘检测算法(如Sobel算子、Canny边缘检测等)来获取图像边缘上的特征点。
- 形状描述子计算:根据选择的形状描述子算法(如Hu矩、Zernike矩等),计算图像的形状描述子。
- 索引构建:将计算得到的形状描述子与图像的其他特征和元数据一起存储在数据库中,作为检索的索引。
6.3.2 形状索引在实际图像检索中的案例分析
为了更好地理解形状索引在实际图像检索中的应用,我们考虑一个具体案例。假设有一个大型的艺术作品数据库,用户希望根据画作中的特定形状来检索图像。
- 问题定义 :构建一个形状索引系统,让用户能通过上传的草图来检索数据库中相似形状的艺术作品。
- 数据准备 :数据库包含成千上万的图像和它们的形状索引(例如使用Hu矩或Zernike矩计算得到)。
- 用户交互 :用户上传一张草图,并通过形状索引计算得到其描述子。
- 检索与反馈 :系统根据上传的草图描述子,计算与数据库中存储的形状描述子之间的相似度,返回最相似的图像结果给用户。
通过这个案例,我们可以看到形状索引在实际应用中的巨大潜力,它为图像检索提供了一种强大的工具,使检索过程更加直观和高效。
形状索引不仅在艺术作品检索中有应用,在医学图像分析、工业质量检测等领域也有广泛应用。通过优化形状索引的构建和检索方法,CBIR系统可以提供更准确和快速的图像检索服务。
简介:内容为基础的图像检索(CBIR)技术是计算机视觉和图像处理的核心技术之一,特别适用于未标注或少标注的大规模图像数据库。MATLAB提供了一个高效环境来构建CBIR系统原型,集成了图像特征提取、降维、聚类和相似性度量等工具。本项目详细介绍了使用MATLAB实现CBIR系统的各个阶段,包括特征提取、编码表示、相似性度量、索引检索和结果评估,并重点关注形状索引技术,利用多种形状描述子以提高检索精度。文档中包含实践细节和性能评估,为图像检索领域的研究人员和学生提供了深入学习和实践的机会。















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









