






文件是文件系统对数据的分割单元。文件系统用目录来组织文件,赋予文件以上下分级的结构。在硬盘上实现这一分级结构的关键,Linux使用inode来虚拟普通文件和目录文件对象。
在Linux文件管理中,我们知道,一个文件除了自身的数据之外,还有一个附属信息,即文件的元数据(metadata)。这个元数据用于记录文件的许多信息,比如文件大小,拥有人,所属的组,修改日期等等。元数据并不包含在文件的数据中,而是由操作系统维护的。事实上,这个所谓的元数据就包含在inode中。我们可以用$ls -l filename来查看这些元数据(ls命令常用参数)。inode所占据的区域与数据块的区域不同。每个inode有一个唯一的整数编号(inode number)表示。
inode是“文件”从抽象到具体的关键。inode储存有一些指针,这些指针指向存储设备中的一些数据块,文件的内容就储存在这些数据块中。当Linux想要打开一个文件时,只需要找到文件对应的inode,然后沿着指针,将所有的数据块收集起来,就可以在内存中组成一个文件的数据了。
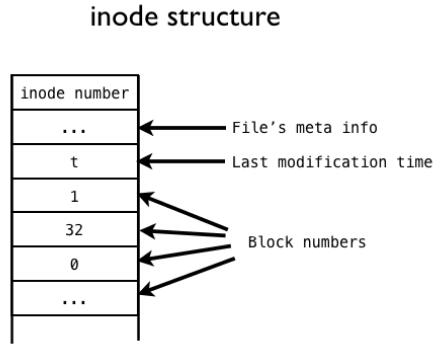
inode结构示意图
inode并不是组织文件的唯一方式。最简单的组织文件的方法,是把文件依次顺序的放入存储设备,DVD就采取了类似的方式。但如果有删除操作,删除造成的空余空间夹杂在正常文件之间,很难利用和管理。
复杂的方式可以使用链表,每个数据块都有一个指针,指向属于同一文件的下一个数据块。这样的好处是可以利用零散的空余空间,坏处是对文件的操作必须按照线性方式进行。如果想随机存取,那么必须遍历链表,直到目标位置。由于这一遍历不是在内存进行,所以速度很慢。
FAT系统是将上面链表的指针取出,放入到内存的一个数组中。这样,FAT可以根据内存的索引,迅速的找到一个文件。这样做的主要问题是,索引数组的大小与数据块的总数相同。因此,存储设备很大的话,这个索引数组会比较大。
inode既可以充分利用空间,在内存占据空间不与存储设备相关,解决了上面的问题。但inode也有自己的问题。每个inode能够存储的数据块指针总数是固定的。如果一个文件需要的数据块超过这一总数,inode需要额外的空间来存储多出来的指针。
在Linux中,文件和目录都有对应的inode,查找某个文件,就是从更节点开始查找文件inode的过程。Linux下stat命令,可以用来查看文件和目录的metadata,这些信息都存储在inode节点中。
xinlin@ubuntu:~$ stat Videos/
File: Videos/
Size: 4096 Blocks: 8 IO Block: 4096 directory
Device: 801h/2049d Inode: 2097637 Links: 2
Access: (0755/drwxr-xr-x) Uid: ( 1000/ xinlin) Gid: ( 1000/ xinlin)
Access: 2019-06-20 11:23:47.851110608 +0800
Modify: 2019-06-11 15:52:45.572340130 +0800
Change: 2019-06-11 15:52:45.572340130 +0800
Birth: -
xinlin@ubuntu:~$ stat .vimrc
File: .vimrc
Size: 379 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 2111083 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ xinlin) Gid: ( 1000/ xinlin)
Access: 2019-07-01 15:24:55.426598391 +0800
Modify: 2019-07-01 15:24:55.426598391 +0800
Change: 2019-07-01 15:27:50.721527016 +0800
Birth: -
以上就是关于Linux文件系统中的inode这个概念的简单介绍。















 2744
2744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









