







目录
概述
文件是存储在硬盘上的,硬盘的最小存储单位叫做扇区sector,每个扇区存储512字节。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个块block。这种由多个扇区组成的块,是文件存取的最小单位。这是针对于文件系统而言的,而对于磁盘来说,其实没有块这样的概念,只是文件系统为了提高读取速率而延申的一个概念;即磁盘的基本单位是扇,而文件系统的基本单位是块。 块的大小,最常见的是4KB,即连续八个sector组成一个block。
而操作系统和内存进行交流的时候,延申出了页的概念,这是针对于内存来说的。
即:操作系统与内存交流是以页为基本单位,文件系统与磁盘交流是以块为基本单位,而磁盘自身读写是以扇区为基本单位。
文件数据存储在块中,那么还必须找到一个地方存储文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种存储文件元信息的区域就叫做inode,中文译名为索引节点,也叫i节点。因此,一个文件必须占用一个inode,且至少占用一个block。
也即是说:
- 元信息->inode
- 数据->block
1. inode
文件=文件属性+文件内容;文件属性和文件内容是分开存储的,想要关联起来就要通过某种特定方式,这种方式就是inode编号。
inode是一个结构体,但是里面存有inode 编号和其他文件信息。
1.1 inode大小
inode也会消耗硬盘空间,所以格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区,存放inode所包含的信息。
每个inode的大小,一般是128字节或256字节。通常情况下不需要关注单个inode的大小,而是需要重点关注inode总数。inode总数在格式化的时候就确定了。
1.2 inode结构
下图是Linux系统特有的EXT系列的文件系统:
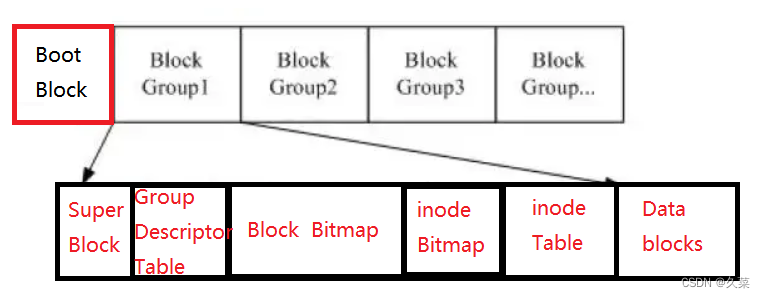
上图中inode Table负责存储文件属性,Data blocks负责存储文件内容。 这个inode Table就是我们所说的inode。
可以用黑色方框格来表示其中的inode Table结构,红色框来表示Data blocks结构。一个黑框是一个inode Table,一个红框是一个Data blocks。
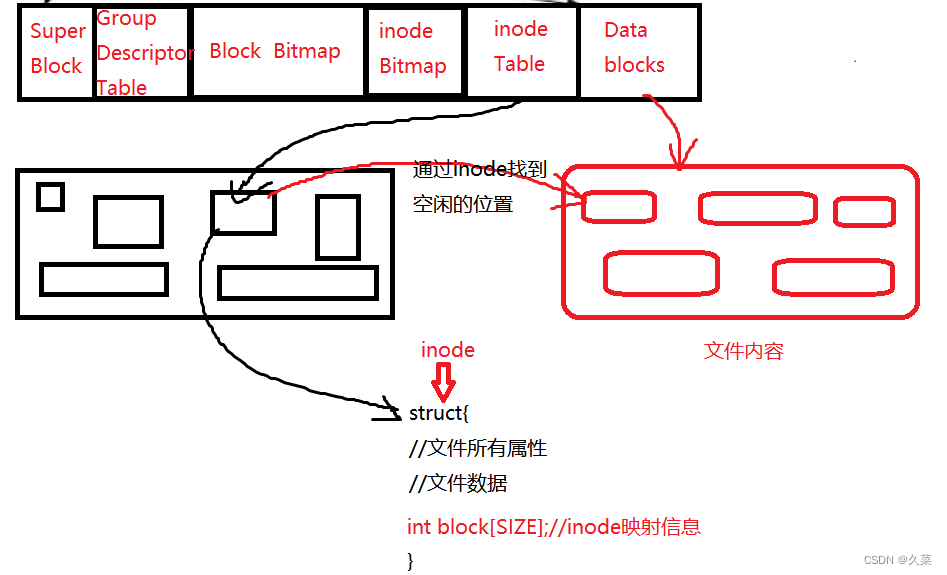
当某个文件被创建时,系统会自动寻找合适的位置存放其inode,所以要通过一些方式:
上述有两个数据块叫做位图,位图是通过比特位来表示数据块是否可用的一种数据结构。
2. 位图
寻找未被使用的数据块,使用的是位图的方式(举例):

- inode Bitmap
寻找的是inode Table中的数据块:
位置含义:inode编号;
内容含义:特定inode是否被占用;也就是说,每种二进制数对应一个数据块。
- Block Bitmap
寻找的是Data Block里的数据块:
位置含义:块编号;
内容含义:特定块是否被占用;和inode Bitmap一个道理。
有了这个方法,想要找到数据块就可以通过遍历比特位找到为0的位置,表示无人使用,然后反馈给inode结构体,将该位置信息填入到结构体里的int block[SIZE],以此得到映射关系,就可以找到空闲的数据块。
也就是说,一个文件块组里面只要有后四个结构(inode位图,inode数据块,内容位图,内容数据块),就可以实现文件的创建,而前两个结构是描述这个组的属性的,例如大小、数据块使用多少。
3. inode对应关系
3.1 文件操作
inode包含很多的文件元信息,但不包含文件名,例如:字节数、属主UserID、属组GroupID、读写执行权限、时间戳等。而文件名存放在目录当中,但Linux系统内部不使用文件名,而是使用inode号码识别文件。 对于系统来说文件名只是inode号码便于识别的别称。
也就是说,每个inode都有一个对应的数据块,用来存储文件属性。并且找文件的过程并不是通过文件名。
创建文件一定是在一个特定目录下,而目录也是文件,它也有数据块,它的数据块里面放的是文件对应的inode编号。 也就是文件名和inode的映射关系。
那么知道了目录的data blocks存储的是文件名与inode的映射关系,就可以进一步理解在一个目录下查找文件、创建文件的过程
- 打开/查看文件
//lesson目录下
cat test.c
详细过程:
1.系统找到test.c这个文件名对应的inode号码;
2.通过inode号码,获取inode信息;
3.根据inode信息,找到文件数据所在的block,并读出数据。
总结:当Linux系统要查找某个文件时,它会先搜索inode table找到这个文件的属性及数据存放地点,然后再查找数据存放的Block进而将数据取出。
期间系统还会根据inode信息,看用户是否具有访问的权限,有就指向对应的数据block,没有就返回权限拒绝。
- 创建文件
//lesson目录下
touch test.c;
这个操作其实就是:修改位图+填充inode信息。
- 遍历inode bitmap位图结构,找到空闲数据块;
- 把test.c的inode填入inode数据块里,由于是空文件所以不需要data block。
而需要写入内容时:根据其inode找到它对应的空间,发现为空,就通过遍历data bitmap位图结构找到空闲位置,开辟4KB空间(默认),然后把该空间的id写到block数组中,然后就把文件内容写到data block对应的数据块里了。
- 删除文件
并不需要清空数据块内容,只需要修改两个位图,由1->0即可“删除该文件”,这也就将该位置定义为可覆盖的文件数据;这也就是为什么平时删除文件是可以恢复的。
3.2 如何理解目录创建
前面说过,文件名存放在目录的data block中,目录也是文件,所以文件有的那套inode目录也有。
而其data block内容是:当前目录下,文件名对应文件的inode指针,通过它可以找到当前目录的文件的inode。
这也就印证了那句话:文件名在系统层面没有意义,是给用户使用的;而Linux中真正标识一个文件是通过inode编号。

所以在目录下创建文件其实就是在目录的数据块里添加文件的inode编号和文件名,但是找到文件数据还是通过inode。
4. 软、硬链接
软链接文件是一个独立的文件有自己的inode节点,文件中保存了源文件路径,通过数据中保存的源文件路径访问源文件
硬链接是文件的一个目录项,与源文件共用同一个inode节点,直接通过自己的inode节点访问源文件(其实本质上来说与源文件没区别)
查看inode数量(第一列)
ls -ali;//+文件名可单独查看该文件
去除链接(不建议用rm)
unlink+新文件名
硬链接是通过inode引用另外一个文件,软链接是通过名字引用另外一个文件。
4.1 硬链接
通过文件系统的inode引用产生的新的文件名,而不是产生新的文件,称为硬链接。其实就是创建文件名和inode的映射关系。
一般情况下,每个inode号码对应一个文件名,但是Linux允许多个文件名指向同一个inode号码。意味着可以使用不同的文件名访问相同的内容。
创建test.c的硬链接:
//硬链接不带-s
ln test.c abc.c;
ls -ali查看硬链接:
790395 -rw-rw-r-- 2 zcb zcb 1826 Dec 9 15:19 abc.c
790395 -rw-rw-r-- 2 zcb zcb 1826 Dec 9 15:19 test.c
790395是inode编号,而数字2代表的是硬链接数(默认是1,意味有几个文件名指向该文件,该变量存放在inode结构体中,采用的是引用计数)。
可见两个文件的inode编号一样,说明这两个文件根本就不是独立的文件,是inode编号和文件名的的映射,是一模一样的别名。
硬链接被删除,则inode中的链接数-1,并不会直接删除文件数据,而是等链接数为0的时候才会实际删除对应文件的inode,将所占用数据块置为空闲
4.2 软链接
软链接就像我们在windows中的快捷方式。 为什么这么说呢?平时我们的电脑下载好软件时,假如没有自动添加在桌面,那我们就要去文件夹里面找,那这时就显得很麻烦,我们就会创建快捷方式到桌面。这个过程就相当于软链接,它们是类似的。
既然是快捷方式,那它是完全依赖于原来的文件的。如果原来的文件被删除了,那么这个新添加的文件也就无法使用了。
//软链接带-s
ln -s test.c mytest.c;
//链接成功
mytest.c->test.c
4.2.1 关于删除软链接
- 对于文件来说,直接删除软链接并不会删除源文件;但是删除源文件后,软链接对应的文件会失效。
- 对于目录而言,直接删除软链接目录(不带“/”)不会删除源文件,但是若删除目录时多添加了“/”,那么会只保留两个空目录(源文件目录和软链接目录中文件都没了)。
- 服务器上,对data文件夹建立软链接link_data后,如果想删除软链接,则执行 rm -rf link_data,不要加"/"
4.3 它们之间的区别
- 软链接是一个独立的文件,有自己的inode,硬链接没有独立的inode
- 软链接相当于快捷方式;
- 硬链接本质没有创建文件,只是建立了一个文件名和已有的inode的映射关系,并写入当前目录,相当于取了个别名。
- 软连接可以跨文件系统进行连接,硬链接不可以。这是因为不同分区有可能有不同文件系统,就算系统相同,也会导致节点号有歧义冲突,因此硬链接不能跨分区建立
- 那么硬链接的作用?
方便目录之间进行跳转:.和当前目录相同,…和上级目录相同。
- 为什么默认目录的硬链接是2?
因为目录创建时默认有.和…代表当前目录和上级目录、
5. 动静态库
5.1 最后修改时间
查看文件的最后修改时间:
stat+文件名

Access是文件最近被访问的时间;在较新的Linux内核中,该时间不会立即被更新,而是有一定时间间隔。
Modify是最近一次修改文件内容的时间
Change是最近一次修改文件属性的时间
当我们修改文件内容的时候,可能会更改文件属性,所以它们可能会同时改变。
makefile第二次无法make重新编译的原因,就是由于新生成的可执行程序的时间比源文件更新,所以就无法继续make。如果你对源文件进行修改,时间也就更新了,也就可以make了。
5.2 库
5.2.1 指令
对可执行文件test:
ldd test
可查看可执行程序依赖的动态库内容:

llibc.so.6这个库就是我们所指向的C标准库,在Linux中,库也是文件。
继续查看链接库:
ls /lib64/libc.so.6 -l

查看静态库:
file+可执行文件
静态链接前提是makefile要在g++添加static
一般服务器可能没有内置语言的静态库,而只有动态库,可yum自行安装。
sudo yum install glibc-static
5.2.2 命名
库文件的命名:lib.xxx.so 或者 lib.xxx.a-…
库的真实名字:去掉lib前缀,去掉.a-、.so(包含后缀),剩下的就是库名称
ls /lib64/libc-2.17.so -l

如果是动态库,库文件就是以.so结尾的
如果是静态库,库文件就是以.a结尾的
这里的动静态库其实都是磁盘文件
5.3 动态库
动态库(.so):程序在运行的时候才去链接动态库的代码,多个程序共享使用库的代码。
5.4 静态库
静态库(.a):程序在编译链接的时候把库的代码链接到可执行文件中。程序运行的时候将不再需要静态库
5.5 关于加载速度
动态库也叫运行时库,是运行时加载的库,将库中数据加载到内存中后,每个使用了动态库的程序都要根据加载的起始位置计算内部函数以及变量地址,因此动态链接动态库加载及运行速度相较静态链接是较为不如的,但是它也有好处,就是多个程序在内存中只需要加载一份动态库就可以共享使用。加载动态库的程序运行速度相对较慢,因为动态库运行时加载,映射到虚拟地址空间后需要重新根据映射起始地址计算函数/变量地址
静态链接,链接静态库,每个程序将自己在库中用到的指令代码单独写入自己可执行程序中,程序运行时无依赖,加载运行速度快,但是程序运行后有可能会有冗余代码在内存中
5.6 关于优缺点
动态链接链接的是动态库,而动态库中包含了大量的常用的功能接口指令代码这种链接方式,是用于解决静态库存在的浪费内存和磁盘空间,以及模块更新困难等问题。
动态链接生成可执行程序,可执行程序中会记录自己依赖的库列表以及库中的函数地址信息,等到运行程序的时候,由操作系统将库加载到内存中(多个程序可以共享,不需要加载多份相同实例),然后根据库加载后的地址在对每个程序内部用到的库函数的地址进行偏移计算。
基于这么一种思想,动态链接具有以下优缺点:
优点:
- 更加节省内存并减少页面交换;
- 库文件与程序文件独立,只要输出接口不变,更换库文件不会对程序文件造成任何影响,因而极大地提高了可维护性和可扩展性;
- 不同编程语言编写的程序只要按照函数调用约定就可以调用同一个库函数;
- 适用于大规模的软件开发,使开发过程独立、耦合度小,便于不同开发者和开发组织之间进行开发和测试。
缺点:
- 运行时依赖,否则找不到库文件就会运行失败
- 运行加载速度相较静态库慢一些
- 需要对库版本之间的兼容性做出更多处理
















 188
188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











