






在讲解sparkStreaming优化方法之前先看几个sparkStreaming的监控指标:
1. 批处理时间与批次生成时间
2. 任务积压情况
3. 任务GC时间
4. 任务序列化时间
5. 上游消息TPS, 是否存在消费延迟
6. 下游推送结果数据,对下游系统(mysql/redis)的QPS、IO监控
对于sparkStreaming 任务首先的调优方式可按照一般spark任务的两种基本调优方式 : 资源与任务的并行度的调节, 这两种方式可基本满足并且也是最主要的调优方式。资源优化包括: cpu 与内存 的分配, 尽量分配多的cpu可提高任务的物理并行度、尽可能多的内存提高RDD缓存量、减少shuffle IO时间、减少GC时间等提升任务性能; 通过spark.executor.cores/spark.driver.cores设置executor/dirver的cpu个数,通过spark.driver.memory/spark.executor.memory设置driver/executor的内存大小;任务的并行度设置为cpu个数的2-3倍, 任务的并行度代表一个stage的逻辑并行度,需要与其物理并行度进行区分, 我们都清楚增加任务的并行度可以减少每一个task处理的数据量,对数据倾斜起到一定的优化作用,那么为何逻辑的并行度数量要高于物理并行度数量,由于一个stage的每一个task所处理的数据量大小不一,那么其完成时间也是不一,假设存在task1、task2两个任务,task1的数据量是task2的两倍, 会造成task1晚于task2的执行完成,期间会造成执行task2的cpu 空闲资源浪费, 假设存在task1、task2、task3三个任务,在task2执行完成之后可继续执行task3, 那么既减少每一个task的数据量又充分利用了资源,至于为何是2-3倍,这是一个经验值,可根据任务的实际情况进行调节,通过spark.default.parallelism 设置任务并行度。
批处理时间(process time)、 批次时间(batch interval time) 、任务积压情况可通过以下streaming的监控得出:
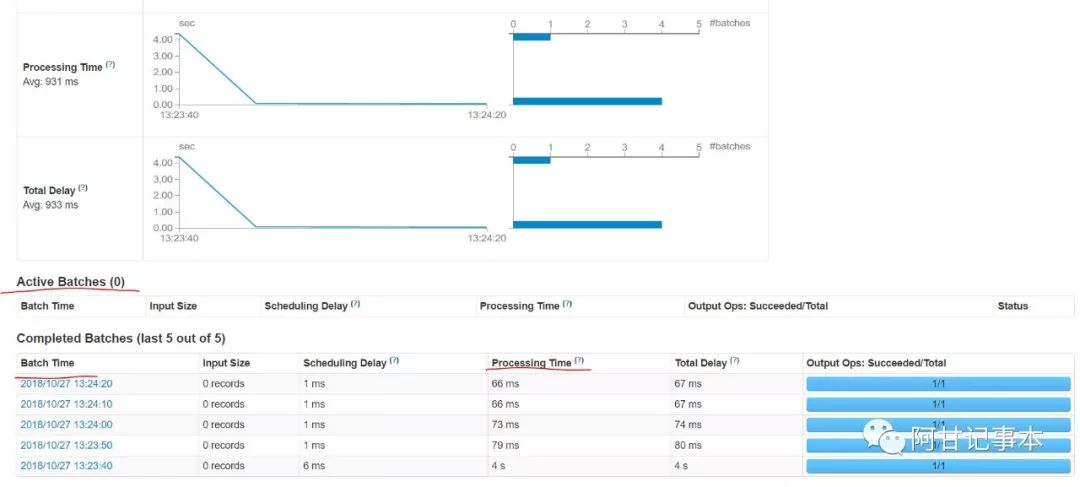
对比Processing time 与Batch Time的时间可分析出批处理时间与批次时间情况,Active Baatchs 可得出任务积压情况,sparkStreaming任务性能首要满足的就是Processing time
StreamingContext 的时候第二个参数指定任务的批次生成时间, 但是这种方式不能从根本上解决问题,最主要方式就是减少批次的执行时间,如何找到需要优化的任务关键点, 有以下几种方式:观察任务GC时间、序列化时间
任务GC会造成任务的暂时卡顿,增长了任务的执行时间, GC由于内存不足造成,可增大内存解决(按照资源调优方式解决),也有可能是shuffle 阶段内存不足造成GC,那么需要对shuffle 进行调优, 最主要是找到发生GC的区域,是年轻代还是老年代 或者永久代,通过配置spark.executor.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimeStamps 查看具体的GC日志情况对相应的区域进行调整 , 并且通常用年轻代使用并行回收算法、老年代使用CMS回收算法。
序列化是在数据的传输过程中,spark默认使用java 的序列化方式,但是这种方式序列化与反序列化包含的信息多、耗时长,通常使用Kyro的方式进行序列化,包含的信息少、耗时短,sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") 进行设置,对于自定义对象需要手动注册: sparkConf.registerKryoClasses(class)
2 . 找到耗时的stage,并且在代码层面进行优化
saprk任务是以shuffle来划分stage , 找到对应的stage代码从以下几点出发:
a. 高性能算子使用
使用reduceByKey 替换groupByKey , reduceByKey 类似于mr中combiner ;
使用mapPartitions 替换 map操作, 由于sparkStreaming 是小批次的处理任务,可直接将其全部加载到内存进行处理
b. 多次使用的RDD 进行持久化
对于多次使用的RDD ,将其持久化避免重复计算
c . 外部读写选择高性能数据库
面试几次经常遇到sparkStreaming 写hdfs 的情况的, hdfs特点就是高延时、高吞吐量,并不满足sparkStreaming 低延迟为标准,尽可能选择hbase/redis/mysql 这些读写低延迟的数据库。
d. 外部数据的读写方式
通常需要面临的情况是根据外部数据(维度数据) 对源数据进行过滤, 那么如何查询是关键,每处理一条数据查询一次数据不仅影响效率还会在外部数据源造成很大的压力,那么批次方式进行查询可以减少处理时间并且对外部数据压力也减少不少,如果维度维度数据量很小,或者内存满足要求,可以全部查询出来以广播变量的方式使用; 那么对于结果数据的输出方式同样重要,
曾使用batch 插入方式到mysql , 几百条记录耗时秒级, 最后使用replace into方式只需要毫秒级别就可以完成。由此可见一定要选择适合的外部数据使用方式。
e . 广播变量的使用方式
广播变量将数据从driver端发送到executor端, 因此广播变量要在driver进行broadcast 、 在executor端进行value 获取, 曾在使用中出现在driver端value ,导致任务的序列化时间很长,这一点需要注意。另外使用fastutil 包下面的集合类代替java 的集合类, 减少广播数据所占大小
sparkStreaming 中从source 获取的数据默认是存储在内存中的,那么处理过的批次数据会不会一直存储在内存中中, sparkStreaming 提供数据自动清理机制,会智能化的将一些无用的数据清除掉,配置spark.streaming.unpersist=true即可。
对于上游source , sparkStreming 一般对接kafka , 可通过kafka 管理平台查看对应topic的生产速率、消费速率、消费延迟量指标,以判断sparkStreaming 是否存在消费延迟,即生产速率> 消费速率, 那么同样需要优化sparkStreaming 任务, 因为根绝spakrStreaming的反压机制, 任务批次处理时间越短,就会自动调整其消费的速率。
对于下游sink , 需要关注其QPS与IO指标, 通常情况IO量不是瓶颈,QPS才是需要担忧的地方,QPS不仅会影响sparkStreming任务执行效率还会影响其他业务系统的性能。 在一些大型的项目中,对mysql 或者redis 同通常使用读写分离的方式, 对于查询使用从库,更新使用主库,减少对单台机器的使用压力。以上提到对于读使用批量或者广播方式完成,对于写可以使用foreachPartition 方式并且在里面数据库连接池的方式输出, 我们可以大致计算所消耗的连接数,假设连接池的最大可连接数10个, executor的数量是5个,那么总的连接数就是50个, 若每foreach一次就获取一次连接,不仅会造成连接数过高、也会影响任务的性能。
以上便是sparkStreming 需要关注的性能指标以及一些常用的优化点。















 484
484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









