







1.由数组+链表的结构改为数组+链表+红⿊树。
2. 优化了⾼位运算的hash算法:h^(h>>>16)
3. 扩容后,元素要么是在原位置,要么是在原位置再移动2次幂的位置,且链表顺序不变。【当超过限制的时候会resize,然而又因为我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置】
1. 底层数据结构?
JDK 1.7 : Table数组+ Entry链表
JDK1.8 : Table数组+ Entry链表/红黑树
数组里面每个地方都存了Key-Value这样的实例,在Java7叫Entry在Java8中叫Node

2. 链表如何插入?
java8之前是头插法
在java8之后,都是所用尾部插入了
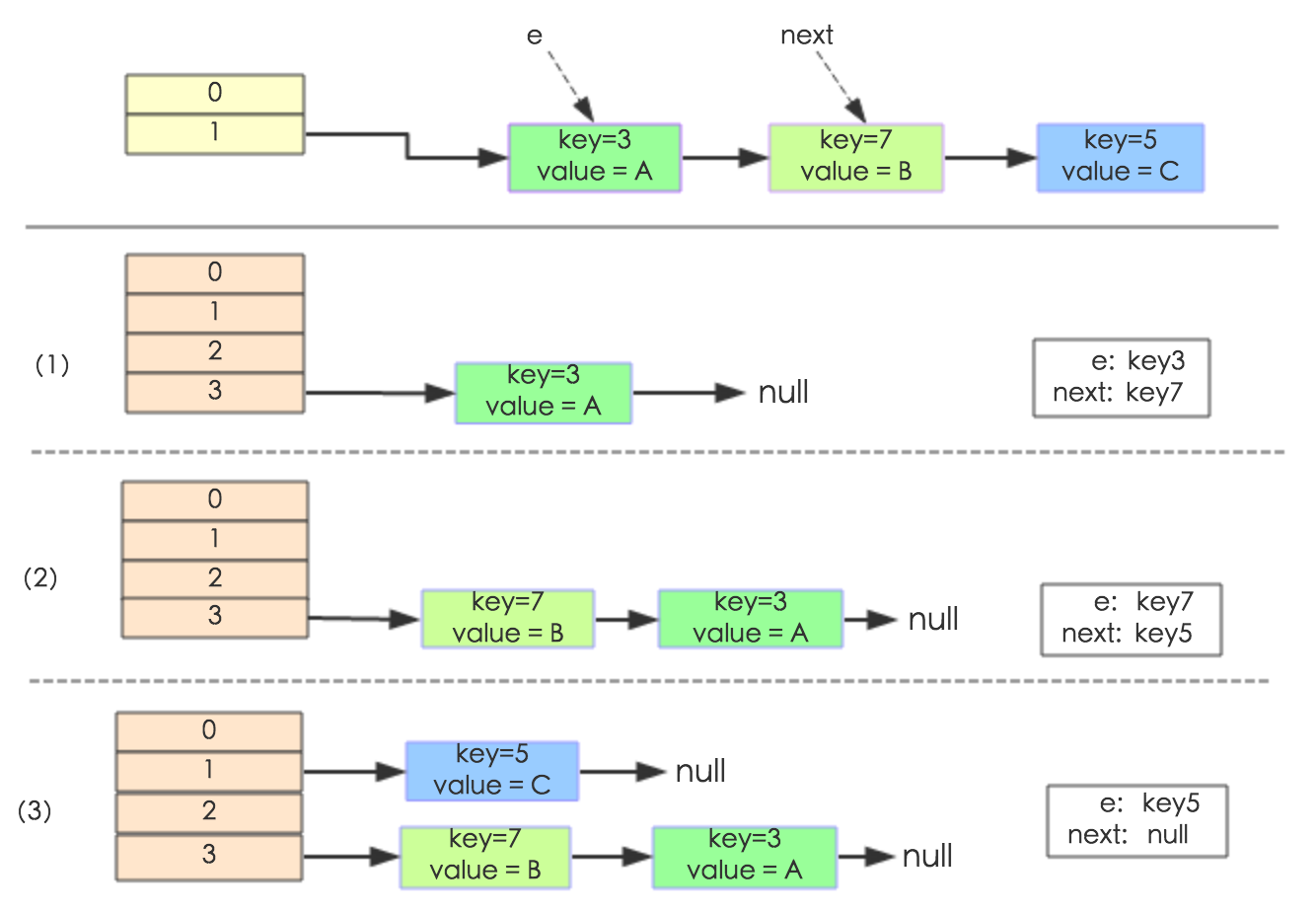
JDK 1.7 采用头插法来添加链表元素,存在链表成环的问题,1.8 中做了优化,采用尾插法来添加链表元素
【核心还是因为头插会改变顺序】
3. 核心变量?什么时候扩容?什么时候链表树化?
DEFAULT_INITIAL_CAPACITY:Table数组的初始化长度16
MAXIMUM_CAPACITY:Table数组的最大长度
DEFAULT_LOAD_FACTOR:当元素的总个数>当前数组的长度 * 负载因子。2倍扩容
TREEIFY_THRESHOLD:链表树化阙值: 默认值为
8【将链表转红黑树】UNTREEIFY_THRESHOLD:红黑树链化阙值: 默认值为
6
MIN_TREEIFY_CAPACITY:64最小树化阈值,当Table所有元素超过改值,才会进行树化
4. 具体如何扩容?
- 扩容:创建一个新的Entry空数组,长度是原数组的2倍。
- ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组
为什么需要重新Hash?
index = hash(Key) & (Length - 1)
其中:hash
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
高16bit不变,低16bit和高16bit做了一个异或?
为了减少碰撞。

5. 为什么要使用数组?使用其他结构是否可行?
是否可以使用LinkedList代替数组结构?
List<Entry> table=new LinkedList<Entry>();当然可以啊。
因为数组的效率最高。定位位置是通过hash&(length-1) .而LinkedList底层是链表
使用ArrayList是否可行?因为使用基本数组扩容可以自定义。HashMap中数组扩容刚好是2的次幂,在做取模运算的效率⾼
⽽ArrayList的扩容机制是1.5倍扩容
6. resize

7. 线程
在多线程使用场景中,应该尽量避免使用线程不安全的HashMap,而使用线程安全的ConcurrentHashMap
1.在JDK1.7中,当并发执行扩容操作时会造成环形链和数据丢失的情况。
2.在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。















 1761
1761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









