







1. string
redis 设计了一种简单动态字符串(SDS)来作为底层实现
typedef char *sds;
struct sdshdr {
// buf 已占用长度
int len;
// buf 剩余可用长度
int free;
// 实际保存字符串数据的地方
char buf[];
};二进制安全(只关心二进制化的字符、不关心具体格式,不会遇到\0进行停止,获取长度通过sds->len)、减少内存分配(动态空间预分配和惰性空间释放)空间分配原则:当len小于IMB(1024*1024)时增加字符串分配空间大小为原来的2倍,当len大于等于1M时每次分配 额外多分配1M的空间。
2. list
Redis进阶-List底层数据结构精讲_小工匠-CSDN博客_redis的list底层数据结构
Redis 的列表相当于 Java 语言里面的 LinkedList,是链表而不是数组 。
这意味着list 的插入和删除操作非常快,时间复杂度为 O(1),但是查找数据很慢,时间复杂度为 O(n)
-
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是 ziplist ,即压缩列表 . 它将所有的元素紧挨着一起存储,分配的是一块连续的内存
-
当数据量比较多才会改成 quicklist.
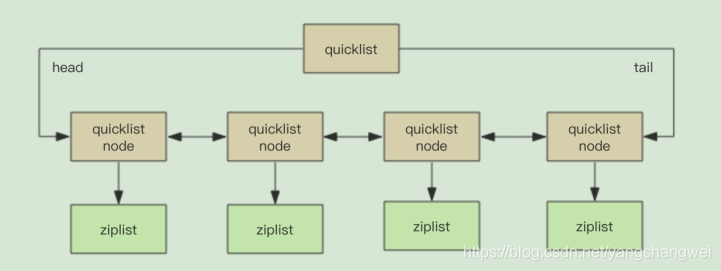
考虑到链表的附加空间相对太高,prev 和 next 指针就要占去 16 个字节 (64bit 系统的指针是 8 个字节),另外每个节点的内存都是单独分配,会加剧内存的碎片化,影响内存管理效率。后续版本对列表数据结构进行了改造,使用 quicklist 代替了 ziplist 和 linkedlist
quicklist 是 ziplist 和 linkedlist 的混合体,它将 linkedlist 按段切分,每一段使用 ziplist 来紧凑存储,多个 ziplist 之间使用双向指针串接起来
3. 持久化-RDB
- Redis的持久化是可以禁用的,就是说你可以让数据的生命周期只存在于服务器的运行时间里。
- 两种方式的持久化是可以同时存在的,但是当Redis重启时,AOF文件会被优先用于重建数据。
- 比起AOF,在数据量比较大的情况下,RDB的启动速度更快
RDB原理
- Redis调用fork(),产生一个子进程。
- 子进程把数据写到一个临时的RDB文件。
- 当子进程写完新的RDB文件后,把旧的RDB文件替换掉。


4. 持久化-AOF
Redis AOF原理_pythonluo的专栏-CSDN博客_redis的aof
Redis 将所有对数据库进行过写入的命令(及其参数)记录到 AOF 文件。AOF 文件使用网络通讯协议的格式来保存这些命令
举个例子, 如果执行以下命令:
redis> RPUSH list 1 2 3 4
(integer) 4redis> LRANGE list 0 -1
1) "1"
2) "2"
3) "3"
4) "4"redis> KEYS *
1) "list"redis> RPOP list
"4"redis> LPOP list
"1"redis> LPUSH list 1
(integer) 3redis> LRANGE list 0 -1
1) "1"
2) "2"
3) "3"
那么其中四条对数据库有修改的写入命令就会被同步到 AOF 文件中:RPUSH list 1 2 3 4
RPOP list
LPOP list
LPUSH list 1
为了处理的方便, AOF 文件使用网络通讯协议的格式来保存这些命令。比如说, 上面列举的四个命令在 AOF 文件中就实际保存如下:
*2
$6
SELECT
$1
0
*6
$5
RPUSH
$4
list
$1
1
$1
2
$1
3
$1
4
*2
$4
RPOP
$4
list
*2
$4
LPOP
$4
list
*3
$5
LPUSH
$4
list
$1
1
除了 SELECT 命令是 AOF 程序自己加上去的之外, 其他命令都是之前我们在终端里执行的命令。【这个SELECT命令是由 AOF 写入程序自动生成的, 它确保程序可以将数据还原到正确的数据库上】
























 930
930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









