






在HystrixCommand之前可以使用请求合并器(HystrixCollapser就是一个抽象的父类)来把多个请求合并成一个然后对后端依赖系统发起调用。
下图显示了两种情况下线程的数量和网络的连接数的情况:第一种是不使用合并器,第二种是使用请求合并器(假设所有的链接都是在一个短的时间窗口内并行的,比如10ms内)。
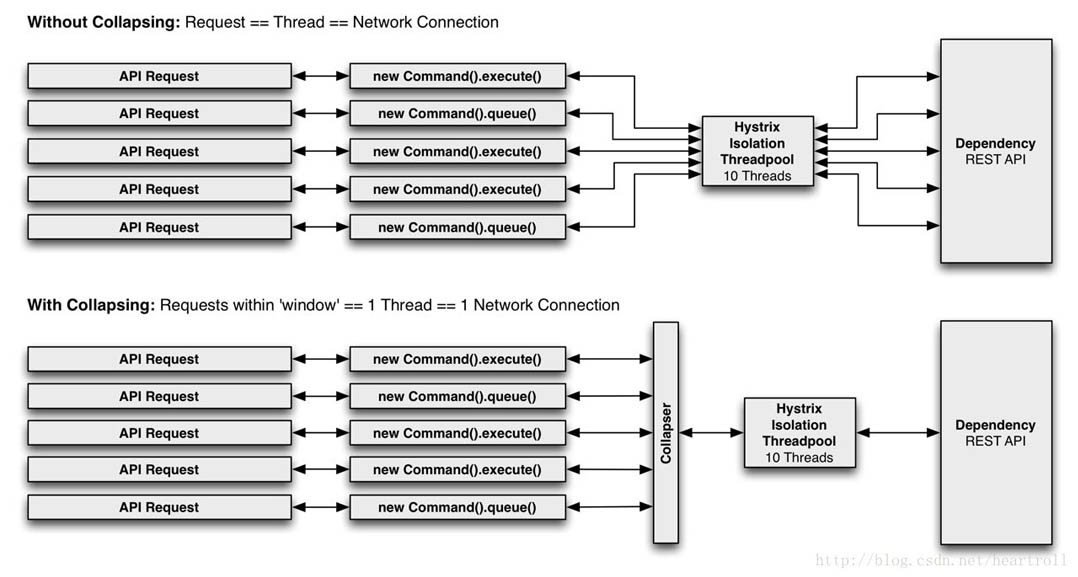
为什么要使用请求合并?
使用请求合并来减少执行并发HystrixCommand执行所需的线程数和网络连接数,请求合并是自动执行的,不会强制开发人员手动协调批处理请求。
全局上下文-global context(跨越所有Tomcat线程)
这种合并类型是在全局应用级别上完成的,因此任何Tomcat线程上的任何用户的请求都可以一起合并。
例如,如果您配置一个HystrixCommand支持任何用户请求依赖关系来检索电影评级,那么当同一个JVM中的任何用户线程发出这样的请求时,Hystrix会将其请求与任何其他请求一起添加到同一个已折叠网络通话。
用户请求上下文-request context(单个Tomcat线程)
如果你配置一个HystrixCommand仅仅为一个单个用户处理批量请求,Hystrix可以在一个Tomcat线程(请求)中合并请求。
例如,一个用户想要加载300个视频对象的书签,不是去执行300次网络请求,Hystrix能够将他们合并成为一个。
Hystrix默认是的就是request-scope,要使用request-scoped的功能(request caching,request collapsing, request log)你必须管理HystrixRequestContext的生命周期(或者实现一个可替代的HystrixConcurrencyStrategy)
这就意味你在执行一个请求之前需要执行以下的代码:
HystrixRequestContext context=HystrixRequestContext.initializeContext();
并且在请求的结束位置执行:
context.shutdown();
在标准的JavaWeb应用中,你也可以使用一个Servlet过滤器来初始化这个生命周期
public class HystrixRequestContextServletFilter implements Filter {
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
HystrixRequestContext context = HystrixRequestContext.initializeContext();
try {
chain.doFilter(request, response);
} finally {
context.shutdown();
}
}
}
然后将它配置在web.xml中
HystrixRequestContextServletFilter
HystrixRequestContextServletFilter
com.netflix.hystrix.contrib.requestservlet.HystrixRequestContextServletFilter
HystrixRequestContextServletFilter
/*
如果你是springboot开发的话代码如下:
@WebFilter(filterName = "hystrixRequestContextServletFilter",urlPatterns = "/*")
public class HystrixRequestContextServletFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HystrixRequestContext context = HystrixRequestContext.initializeContext();
try{
filterChain.doFilter(servletRequest,servletResponse);
}finally {
context.shutdown();
}
}
@Override
public void destroy() {
}
}
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients
@EnableHystrix
//这个是必须的,否则filter无效
@ServletComponentScan
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}
请求合并的成本是多少?
启用请求合并的成本是在执行实际命令之前的延迟。最大的成本是批处理窗口的大小,默认是10ms。
如果你有一个命令需要花费5ms去执行并且有一个10ms的批处理窗口,执行的时间最坏的情况是15ms,一般情况下,请求不会在批处理窗口刚打开的时候发生,所以时间窗口的中间值是时间窗口的一半,在这种情况下是5ms。
这个成本是否值得取决于正在执行的命令,高延迟命令不会受到少量附加平均延迟的影响。而且,给定命令的并发量也是关键:如果很少有超过1个或2个请求被组合在一起,那么这个成本就是不值得的。事实上,在一个单线程的顺序迭代请求合并将会是一个主要的性能瓶颈,每一次迭代都会等待10ms的窗口等待时间。
但是,如果一个特定的命令同时被大量使用,并且可以同时批量打几十个甚至几百个呼叫,那么成本通常远远超过所达到的吞吐量的增加,因为Hystrix减少了它所需的线程数量,依赖。(这段话不太好理解,其实就是说如果并发比较高,这个成本是值得的,因为hystrix可以节省很多线程和连接资源)。
请求合并的流程(如下图)
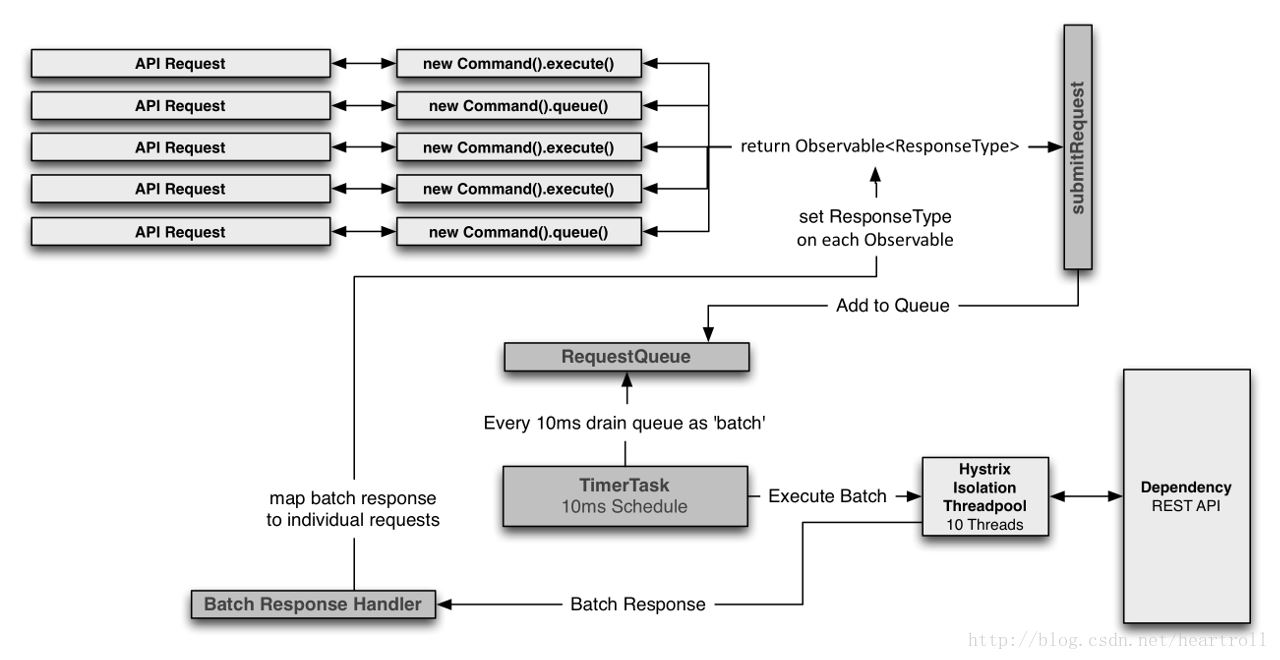
理论知识已经讲完了,下面来看看例子,下面的例子集成了eureka+feign+hystrix,完整的例子请查看:https://github.com/jingangwang/micro-service
实体类
public class User {
private Integer id;
private String username;
private Integer age;
public User() {
}
public User(Integer id, String username, Integer age) {
this.id = id;
this.username = username;
this.age = age;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
final StringBuffer sb = new StringBuffer("User{");
sb.append("id=").append(id);
sb.append(", username='").append(username).append('\'');
sb.append(", age=").append(age);
sb.append('}');
return sb.toString();
}
}
服务提供者代码
@RestController
@RequestMapping("user")
public class UserController {
@RequestMapping("getUser")
public User getUser(Integer id) {
return new User(id, "test", 29);
}
@RequestMapping("getAllUser")
public List getAllUser(String ids){
String[] split = ids.split(",");
return Arrays.asList(split)
.stream()
.map(id -> new User(Integer.valueOf(id),"test"+id,30))
.collect(Collectors.toList());
}
}
消费者代码
UserFeignClient
@FeignClient(name = "eureka-provider",configuration = FeignConfiguration.class)
public interface UserFeignClient {
/**
* 根据id查找用户
* @param id 用户id
* @return User
*/
@RequestMapping(value = "user/getUser.json",method = RequestMethod.GET)
User findUserById(@RequestParam("id") Integer id);
/**
* 超找用户列表
* @param ids id列表
* @return 用户的集合
*/
@RequestMapping(value = "user/getAllUser.json",method = RequestMethod.GET)
List findAllUser(@RequestParam("ids") String ids);
}
UserService(设置为全局上下文)
@Service
public class UserService {
@Autowired
private UserFeignClient userFeignClient;
/**
* maxRequestsInBatch 该属性设置批量处理的最大请求数量,默认值为Integer.MAX_VALUE
* timerDelayInMilliseconds 该属性设置多长时间之内算一次批处理,默认为10ms
* @param id
* @return
*/
@HystrixCollapser(collapserKey = "findCollapserKey",scope = com.netflix.hystrix.HystrixCollapser.Scope.GLOBAL,batchMethod = "findAllUser",collapserProperties = {
@HystrixProperty(name = "timerDelayInMilliseconds",value = "5000" ),
@HystrixProperty(name = "maxRequestsInBatch",value = "5" )
})
public Future find(Integer id){
return null;
}
@HystrixCommand(commandKey = "findAllUser")
public List findAllUser(List ids){
return userFeignClient.findAllUser(StringUtils.join(ids,","));
}
}
FeignCollapserController
@RequestMapping("user")
@RestController
public class FeignCollapserController {
@Autowired
private UserService userService;
@RequestMapping("findUser")
public User getUser(Integer id) throws ExecutionException, InterruptedException {
return userService.find(id).get();
}
上面的代码我们这是的是全局上下文(所有tomcat的线程的请求都可以合并),合并的时间窗口为5s(每一次请求都得等5s才发起请求),最大合并数为5。我们在postman中,5s之内发起两次请求,用户id不一样。
localhost:8082/user/findUser.json?id=123189891
localhost:8082/user/findUser.json?id=222222
结果如下图所示,两次请求合并为一次请求批量请求。

我们再来测试一下请求上下文(Request-Scope)的情况,加入上面所提到的HystrixRequestContextServletFilter,并修改UserService
HystrixRequestContextServletFilter
/**
* @author wjg
* @date 2017/12/22 15:15
*/
@WebFilter(filterName = "hystrixRequestContextServletFilter",urlPatterns = "/*")
public class HystrixRequestContextServletFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HystrixRequestContext context = HystrixRequestContext.initializeContext();
try{
filterChain.doFilter(servletRequest,servletResponse);
}finally {
context.shutdown();
}
}
@Override
public void destroy() {
}
}
UserService(设置为请求上下文)
@Service
public class UserService {
@Autowired
private UserFeignClient userFeignClient;
/**
* maxRequestsInBatch 该属性设置批量处理的最大请求数量,默认值为Integer.MAX_VALUE
* timerDelayInMilliseconds 该属性设置多长时间之内算一次批处理,默认为10ms
* @param id
* @return
*/
@HystrixCollapser(collapserKey = "findCollapserKey",scope = com.netflix.hystrix.HystrixCollapser.Scope.REQUEST,batchMethod = "findAllUser",collapserProperties = {
@HystrixProperty(name = "timerDelayInMilliseconds",value = "5000" ),
@HystrixProperty(name = "maxRequestsInBatch",value = "5" )
})
public Future find(Integer id){
return null;
}
@HystrixCommand(commandKey = "findAllUser")
public List findAllUser(List ids){
return userFeignClient.findAllUser(StringUtils.join(ids,","));
}
}
FeignCollapser2Controller
@RequestMapping("user")
@RestController
public class FeignCollapser2Controller {
@Autowired
private UserService userService;
@RequestMapping("findUser2")
public List getUser() throws ExecutionException, InterruptedException {
Future user1 = userService.find(1989);
Future user2= userService.find(1990);
List users = new ArrayList<>();
users.add(user1.get());
users.add(user2.get());
return users;
}
}
我们在postman中输入:localhost:8082/user/findUser2.json

可以看到一个请求内的两次连续调用被合并了。这个地方要注意,不能直接使用userServer.find(1989).get(),否则直接按同步执行处理,不会合并。如果两个tab页同时调用上述地址,发现发起了两次批量请求,说明作用域是request范围。
参考资料如下:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。














 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









