






MySQL用户和权限管理
元数据数据库:mysql
系统授权表:
db, host, user
columns_priv, tables_priv, procs_priv, proxies_priv
用户账号:
'USERNAME'@'HOST'
@'HOST':
主机名
IP地址或Network
可用通配符: % _
示例:172.16.%.%
用户管理
创建用户:CREATE USER
CREATE USER 'USERNAME'@'HOST' [IDENTIFIED BY 'password'];
默认权限:USAGE(用户权限)
用户重命名:RENAME USER
RENAME USER old_user_name TO new_user_name;
删除用户:
DROP USER 'USERNAME'@'HOST'
示例:删除默认的空用户
DROP USER ''@'localhost';
修改密码:
mysql>SET PASSWORD FOR 'user'@'host' = PASSWORD('password');
mysql>UPDATE mysql.user SET password=PASSWORD('password') WHERE clause(比如说user='root');
注意第二种改表的方式需要执行下面指令才能生效:
mysql> FLUSH PRIVILEGES; (刷新权限)
当然重新启动服务也可。
#mysqladmin -u root -poldpass password ‘newpass’
忘记管理员密码的解决办法:
重新启动mysqld进程时,为其使用如下选项(用在safe脚本上)(如果写入配置文件中my.cnf注意把前面的--去掉):
--skip-grant-tables :不检查授权表,所有用户都变成了root权限
--skip-networking :不让网络用户连接
使用UPDATE命令修改管理员密码(set password命令此模式下用不了)
关闭mysqld进程,移除上述两个选项,重启mysqld
权限管理
权限类别:
管理类
程序类
数据库级别
表级别
字段级别
管理类:
CREATE TEMPORARY TABLES
CREATE USER
FILE
SUPER
SHOW DATABASES
RELOAD
SHUTDOWN
REPLICATION SLAVE
REPLICATION CLIENT
LOCK TABLES
PROCESS
程序类: FUNCTION、 PROCEDURE、 TRIGGER
CREATE
ALTER
DROP
EXCUTE
库和表级别:DATABASE、 TABLE
ALTER
CREATE
CREATE VIEW
DROP
INDEX
SHOW VIEW
GRANT OPTION:能将自己获得的权限转赠给其他用户
数据操作
SELECT
INSERT
DELETE
UPDATE
字段级别
SELECT(col1,col2,...)
UPDATE(col1,col2,...)
INSERT(col1,col2,...)
所有权限
ALL PRIVILEGES 或 ALL
授权
参考:https://dev.mysql.com/doc/refman/5.7/en/grant.html
https://mariadb.com/kb/en/library/grant/
GRANT priv_type [(column_list)],... ON [object_type] priv_level TO 'user'@'host' [IDENTIFIED BY 'password'] [WITH GRANT OPTION];
其中:
priv_type: ALL [PRIVILEGES]
object_type:TABLE | FUNCTION | PROCEDURE
priv_level: (所有库) |.| db_name. | db_name.tbl_name | tbl_name(当前库的表) | db_name.routine_name(指定库的函数,存储过程,触发器)
with_option: GRANT OPTION
| MAX_QUERIES_PER_HOUR count
| MAX_UPDATES_PER_HOUR count
| MAX_CONNECTIONS_PER_HOUR count
| MAX_USER_CONNECTIONS count
示例:GRANT SELECT (col1), INSERT (col1,col2) ON mydb.mytbl TO 'someuser'@'somehost';
回收授权
REVOKE priv_type [(column_list)] [, priv_type [(column_list)]] ... ON [object_type] priv_level FROM user [, user] ...
示例:REVOKE DELETE ON testdb.* FROM 'testuser'@‘172.16.0.%’;
查看指定用户获得的授权
Help SHOW GRANTS
SHOW GRANTS FOR 'user'@'host';
SHOW GRANTS FOR CURRENT_USER[()];
注意:MariaDB服务进程启动时会读取mysql库中所有授权表至内存
(1) GRANT或REVOKE等执行权限操作会保存于系统表中,MariaDB的服务进程通常会自动重读授权表,使之生效
(2) 对于不能够或不能及时重读授权表的命令,可手动让MariaDB的服务进程重读授权表:mysql> FLUSH PRIVILEGES;
注意点1(用户权限和授权):
本机上如果创建了可以远程连接的用户比如说 'zhang'@'192.168.36.%' , 此时如果user表中仍然有匿名用户的localhost主机的话,则在本机上照样可以用mysql -uzhang -h127.1的方式来连接。
注意这里的匿名用户的zhang和创建的可以远程连接的用户zhang并非是同一个账户。
因此为了安全一定要删除掉匿名账户的连接方式。利用drop user 删除掉这些账户。
注意,在当前的数据库创建的用户后面指定的host是允许远程的主机连接的主机IP(或者主机名),而并非是本机上的。不要混淆了。连接的时候注意如果端口号不同被忘了加上-P选项指定端口号。
默认用create命令创建的用户的权限很小(usage)。
注意了,如果用create 创建一个root账号,虽然它的名字和超级管理员的root名字是一致的,但是它权限仍然是usage的很小的权限。
select password('string') 此命令可以查看srting(一定要用单引号引起来)被转化为hash加密后的密码结果,可用这种方式修改用户的加密密码。
可以用help password查看它的详细说明,其中有个变量old_passwords的值能够影响次函数的hash结果的长度
可用show create table mysql.user\G ;和自己设置明文密码测试得知密码必须为41个十六进制数,不能设置明文密码。
注意当创建用户的时候如果同时设置密码(identified),不需要password函数,只有修改密码的时候(两种方式修改都)才需要password函数对密码进行加密。
注意忘记密码利用skip-grant-tables修改密码的的时候,是不能使用DDL语言的(比如drop user name@host),但可以用DML语言进行表中的增删改,因此此时用update命令用修改表的方式修改密码即可。
--skip-networking选项一定要加上。
权限设置的时候可以精确到字段的级别(更不用说表和数据库级别了),因此还是非常灵活的。
授权grant的命令可以同时创建用户,不过要注意必须加上identified by 'password' 选项 (创建的时候必须加上,授权的时候不加,不然报错,不过后面可知这是因为SQL_mode的默认模式造成不能创建空用户的原因)因此大多就是用这个命令来进行创建用户的。
with grant option 参数可以让当前被授权的用户拥有授权给其他用户的权限的能力,不过能够授权给其他用户的权限必须是这个用户所拥有的权限。
帮助中有详解:To use GRANT, you must have the GRANT OPTION privilege, and you must have theprivileges that you are granting.
示例比如说grant all on wordpress.* to wpsuser@'192.168.36.%' identified by '123456' ; 注意此命令虽然授权了全部的权限,但是它是在wordpress这个数据库上的全部权限,它仍然不能看到其它的数据库和对它们进行操作。
注意权限设置之后需要重新开启session(终端)重新登录或者先退出连接再重新连接才能生效,虽然用show grants命令查看到的权限是正确的,但不代表当前直接就能用这些新授权的权限了
也可多利用flush privileges命令,它不仅可以设置密码生效,也可设置权限生效,不过经过测试对于权限来说它没用~~,还是需要重新登录连接
重要注意点1:经过测试,以系统创建的root身份登录之后,它可以把这些系统创建的超级管理员的权限(也就是自己的权限)给revoke掉的(因为登陆的时候这个root权限是ALL权限,已经载入内存了,所以此时就算删除掉自己的权限,也不会在当前session中受影响。不过如果退出后再次连接的时候这些被删除的权限就真的被删除了)
重要注意点2:而且,如果root的某些权限被删除掉之后,user表中再也没有其他的用户拥有这个被删除的权限以及同时拥有with option权限的话,这个被删除的权限则永远无法被再次授权出来了(因为用户必须要有这个权限,同时有with option才能给其他用户授权这个权限),此时就崩了~~
重要注意点3:经过测试就算是利用skip-grant-tables模式,也无法再把root被删除的权限给找回来了,因为在这个模式下,无法使用grant命令,甚至无法查看show grants;
还有一个代理权限(匿名用户用,和PAM模块有关),这个以后再讨论。基本上都是删除掉匿名用户。
MySQL体系结构

存储引擎
InnoDB support for FULLTEXT indexes is available in MySQL 5.6.4 and later.
存储引擎比较: https://docs.oracle.com/cd/E17952_01/mysql-8.0-en/storage-engines.html
目前主要用InnoDB存储引擎,老版本的数据库用的MyISAM存储引擎,这里需要了解它俩的区别。
MyISAM引擎:
MyISAM引擎特点
不支持事务
表级锁定
读写相互阻塞,写入不能读,读时不能写
只能缓存索引,不能缓存数据
不支持外键约束
不支持聚簇索引
支持全文索引
读取数据较快,占用资源较少
不支持MVCC(多版本并发控制机制)高并发
崩溃恢复性较差(因为不支持事务)
MySQL5.5.5前默认的数据库引擎
MyISAM存储引擎适用场景
只读(或者写较少)、表较小(可以接受长时间进行修复操作)
MyISAM引擎文件
tbl_name.frm 表格式定义
tbl_name.MYD 数据文件
tbl_name.MYI 索引文件
InnoDB引擎:
InnoDB引擎特点
行级锁
支持事务,适合处理大量短期事务
读写阻塞与事务隔离级别相关
可缓存数据和索引
支持外键约束
支持聚簇索引
崩溃恢复性更好
支持MVCC高并发
从MySQL5.5后支持全文索引
从MySQL5.5.5开始为默认的数据库引擎
InnoDB数据库文件
一种方式是(低版本默认):所有InnoDB表的数据和索引放置于同一个表空间中
表空间文件:datadir定义的目录下
数据文件:ibddata1, ibddata2, ...
另外一种方式(推荐,高版本默认开启):每个表单独使用一个表空间存储表的数据和索引
启用:innodb_file_per_table=ON (写在my.cnf配置文件中)
参看:https://mariadb.com/kb/en/library/xtradbinnodb-server
system-variables/#innodb_file_per_table
ON (>= MariaDB 5.5)
两类文件放在数据库的database独立目录中
数据文件(存储数据和索引):tb_name.ibd
表格式定义:tb_name.frm
其它存储引擎
Performance_Schema:Performance_Schema数据库使用
Memory :将所有数据存储在RAM中,以便在需要快速查找参考和其他类似数据的环境中进行快速访问。适用存放临时数据。引擎以前被称为HEAP引擎
MRG_MyISAM:使MySQL DBA或开发人员能够对一系列相同的MyISAM表进行逻辑分组,并将它们作为一个对象引用。适用于VLDB(Very Large Data Base)环境,如数据仓库
Archive :为存储和检索大量很少参考的存档或安全审核信息,只支持SELECT和INSERT操作;支持行级锁和专用缓存区
Federated联合:用于访问其它远程MySQL服务器一个代理,它通过创建一个到远程MySQL服务器的客户端连接,并将查询传输到远程服务器执行,而后完成数据存取,提供链接单独MySQL服务器的能力,以便从多个物理服务器创建一个逻辑数据库。非常适合分布式或数据集市环境
BDB:可替代InnoDB的事务引擎,支持COMMIT、 ROLLBACK和其他事务特性
Cluster/NDB:MySQL的簇式数据库引擎,尤其适合于具有高性能查找要求的应用程序,这类查找需求还要求具有最高的正常工作时间和可用性
CSV:CSV存储引擎使用逗号分隔值格式将数据存储在文本文件中。可以使用CSV引擎以CSV格式导入和导出其他软件和应用程序之间的数据交换
BLACKHOLE :黑洞存储引擎接受但不存储数据,检索总是返回一个空集。该功能可用于分布式数据库设计,数据自动复制,但不是本地存储
example:“stub”引擎,它什么都不做。可以使用此引擎创建表,但不能将数据存储在其中或从中检索。目的是作为例子来说明如何开始编写新的存储引擎
MariaDB支持的其它存储引擎:
OQGraph
SphinxSE
TokuDB
Cassandra
CONNECT
SQUENCE
管理存储引擎
查看mysql支持的存储引擎
show engines;
查看当前默认的存储引擎
show variables like '%storage_engine%';
设置默认的存储引擎
vim /etc/my.conf
[mysqld]
default_storage_engine= InnoDB
查看库中所有表使用的存储引擎
show table status from db_name;
查看库中指定表的存储引擎
show table status like ' tb_name ';
show create table tb_name;
设置表的存储引擎:
CREATE TABLE tb_name(... ) ENGINE=InnoDB;
ALTER TABLE tb_name ENGINE=InnoDB;
MySQL中的系统数据库
mysql系统数据库
mysql数据库
是mysql的核心数据库,类似于SqlServer中的master库,主要负责存储数据库的用户、权限设置、关键字等mysql自己需要使用的控制和管理信息
performance_schema数据库
MySQL 5.5开始新增的数据库,主要用于收集数据库服务器性能参数,库里表的存储引擎均为PERFORMANCE_SCHEMA,用户不能创建存储引擎为 PERFORMANCE_SCHEMA的表
information_schema数据库
MySQL 5.0之后产生的,一个虚拟数据库,物理上并不存在 information_schema数据库类似与“数据字典”,提供了访问数据库元数据的方式,即数据的数据。比如数据库名或表名,列类型,访问权限(更加细化的访问方式)
注意点2(存储引擎):
Myisam和innodb虽然都支持压缩数据,不过前者只能对row进行压缩(且压缩后变成了只读的),因此后者所占空间相对而言会更少。
MYiasm是表级锁,一个用户修改这个表的数据时,另外一个用户必须等待(另外的用户可以修改别的表),innodb则是行级锁,度用户可以同时修改一张表,只要是不同的行row即可。因此innodb并发性比较好。
重要注意点:innodb支持MVCC高并发
关于MVCC高并发的简单解释就是,在innodb引擎的数据库里,每一张表不仅仅有定义的可见字段,其中系统还会给它后面加上两个隐藏的字段insert和delete,这两个字段中记录的是对应的行的操作的事件ID
事件ID就是相当于当前操作的一个编号,每操作一次就加1。隐藏的两个字段insert就代表此行添加的时候的事件ID,delete代表删除时的事件ID。如果对一个行进行了update修改操作,就相当于是先delete后insert,此时的这两项是相同的(一般都是delete大于insert),这两项均为当前进行update操作的事件ID
因此,通过这个事件ID,当使用DQL语句(select命令)的时候,因为不管是什么操作都有事件ID,就可以根据当前select的操作的事件ID来显示不同的结果;
比如说当前select操作的事件ID为300,则在表中300事件ID之前的所有结果(行)都会被显示出来,而300之后(相当于还未做这些操作)当然也就不会被显示出来了。
注意在上面的例子中,300事件ID之前被被删除的行(delete值大于insert值)是不会显示出来的,因为已经被删除了。只有那些insert存在而delete为空的和insert和delete相等的事件ID的行才会被显示出来。
由此也可以看出,数据库的delete命令并未直接就把表中的记录record行给删除掉了,而是说把它加上了当前删除命令delete的事件ID,当再用其他的命令比如select的时候,根据它的事件ID来选择显示结果等,给人一种确实把record删除掉的效果。这也是一种数据库的设计思路,能保证短期内的数据安全。
创建新的表的时候(注意是新的表table,而不是database,database就是个文件夹而已,没有存储引擎的说法)会按照当前mysql服务器设置的默认存储引擎来创建这个数据库,新版本已经是innodb了,如果是老版本的话按照上面介绍的命令操作进行设置修改为innodb即可。
服务器配置
mysqld选项,服务器系统变量和服务器状态变量(注意3个的区分)
注意:
其中有些参数支持运行时修改,会立即生效(Dynamic);
有些参数不支持,且只能通过修改配置文件,并重启服务器程序生效;
有些参数作用域是全局的,且不可改变;有些可以为每个用户提供单独(会话)的设置
获取mysqld的可用选项列表:
mysqld --help --verbose
mysqld --print-defaults 获取默认设置
设置服务器选项方法:
在命令行中设置
shell> ./mysqld_safe --skip-name-resolve=1
注意这样就启动了这个mysql服务了,一般这种都是写到脚本中的,或者就是按照下面2中的写到配置文件中即可。
在配置文件my.cnf中设置
skip_name_resolve=1
服务器系统变量:分全局和会话两种
获取系统变量
mysql> SHOW GLOBAL VARIABLES;
mysql> SHOW [SESSION] VARIABLES;
mysql> SHOW VARIABLES LKIE '%VARIABLE%';
mysql> SELECT @@VARIABLES;
修改服务器变量的值:
mysql> help SET
修改全局变量:仅对修改后新创建的会话有效;对已经建立的会话无效
mysql> SET GLOBAL system_var_name=value;
mysql> SET @@global.system_var_name=value;
修改会话变量:
mysql> SET [SESSION] system_var_name=value;
mysql> SET @@[session.]system_var_name=value;
服务器状态变量:
分全局和会话两种
状态变量(只读):用于保存mysqld运行中的统计数据的变量,不可更改
mysql> SHOW GLOBAL STATUS;
mysql> SHOW [SESSION] STATUS;
服务器变量SQL_MODE
SQL_MODE:对其设置可以完成一些约束检查的工作,可分别进行全局的设置或当前会话的设置,参看:https://mariadb.com/kb/en/library/sql-mode/
此变量可同时拥有许多值,常见MODE:
NO_AUTO_CREATE_USER
禁止GRANT创建密码为空的用户
NO_ZERO_DATE
在严格模式,不允许使用‘0000-00-00’ 的时间
ONLY_FULL_GROUP_BY
对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么将认为这个SQL是不合法的
NO_BACKSLASH_ESCAPES
反斜杠“\” 作为普通字符而非转义字符
PIPES_AS_CONCAT
将"||"视为连接操作符而非“或运算符”
注意点3(服务器配置):
注意服务选项,系统变量和系统状态变量的区别(可以查看那个链接);有些只有选项没有变量,有些只有变量没有选项。
其中的系统变量分为全局和回话两个级别,不论是全局性变量还是会话级变量都是用两个@@符号表示(set的时候可以省略不加,详细看help set),而用户的自定义的变量前面用一个@符号表示,用select查询它们的时候别忘了在前面加上(set的时候不能省略,也必须加上)
不过要注意如果进行赋值set命令的话,系统变量的话直接写系统变量名进行set设置即可,可省略@@等,带一个@variable的代表着自定义的变量了。注意set和select使用变量的区别。
注意选项中用下划线或者横线都行,但是变量中都是下划线。
利用show variables like的方式查看变量,大部分是以on off的形式显示,但如果用select @@variable 的方式显示系统变量,则大部分是以0,1 的方式显示。
全局系统变量修改之后能够影响到整个连接到服务器的用户(所有的终端),而会话级别的只能影响这个会话的变量
一个session会话就代表着一个连接,终端连接是session的一个实现方式,终端一般指的是相对于服务器的连接的客户端,终端通过会话建立连接后,才和服务器进行通讯,只要通信就有会话
复习知识点:比如ssh服务,不论是SSH中的同一个应用端口号通过复制通道的方式再开启多个session,还是直接新开一个客户端和SSH通道连接到sshD服务器端,都是相当于新开了session.
ssh服务中,复制出来Xshell中的SSH的远程的一个chanel连接,此时虽然应用端口号并没有增加,但仍然是开启了两个session,两个虚拟终端。
注意在ssh有个选项可以控制在相同的ssh通道内(也就是一个相同的应用端口号),能够开启的最多的session数量(其实这些session每一个都会被看做为一个虚拟终端),在Xshell中这种就是复制ssh通道连接的方式。
但是如果直接重新开一个ssh通道,相当于新开了一个SSH应用客户端,增加了一个连接,应用端口号不同,这样就不会受到这个选项的控制了(当然它这个通道也会受最大session的限制,这里主要讲的是这个选项限制的位置是在一个SSH通道内的最大连接数,而并非SSHD服务器的最大连接数)
而在mysql中,就算是同一台主机连接同一个mysql服务器,只要新开一个连接,这就算是不同的session了,(虽然表面上的终端仍旧是一个)。
不过就算是全局系统变量,它修改之后也只能对新建立连接的用户生效,已经连接上的用户不会受到影响。
系统的状态变量用show status [like 'variable'] 来查看,注意它和系统变量的区别:它只读,不能用set命令修改。
重要注意点,结合之前的博客,可用mysqld --help -v 来查看mysql服务的主程序的参数都被设置成了哪些。
经过测试得知,这个命令得到的各种变量的值就是根据mysql它的默认配置(safe中写的配置)以及各种配置文件my.cnf中写的配置文件来进行显示的
可见这个命令相当于是对mysql服务进行了一次伪启动,并不真正的启动它,但是能够看到按照当前的配置如果启动它,各个参数都是什么
mysql --help
mysql -uroot -p123456 --socket=/data/mysql/3307/socket/mysql.sock
mysqladmin --help
mysqld_safe --help
mysqld --help -v
mysqld --help -v --socket=/data/mysql/3307/socket/mysql.sock
=============
因为这个是mysqld启动服务器的选项,因此它和客户端命令mysql 的直接可以用socket连接的方式不同。
在多实例中执行这个命令会看到,虽然socket指定的目标正确,但是datadir命令仍然不正确(因为没有载入多实例的my.cnf文件,它和mysql连接只需要写socket不一样)
因此下面的命令才是最好的:
mysqld --defaults-extra-file=/data/mysql/3307/etc/my.cnf --help -v
这里不用写socket了是因为,这个配置文件中本来就写的有socket选项。注意书写的时候要把--help -v放在最后面,不然会报错。
=============
一些变量
skip_name_resolve=1 此选项的功能就是禁止将IP地址反向解析成名字,建议加到服务器的配置中去。
它也有同名的系统变量,但是经过查看得知它是个只读变量,无法更改,因此只能通过写入配置文件或者说启动服务器的时候加上--skip_name_resolve=1 的参数的方式(注意是加在safe脚本后面,也可以加在mysqld后面,不过一般不这么做)更改。
max_connections 全局变量,它控制着最大同时能并发连接到数据库的主机个数。此变量是动态dynamic变量,可以直接在mysql数据库中进行设置并生效,无需重启mysqld服务。
还有一些关于threads的状态变量,以及com_select,com_insert等状态变量(它们分别表示着自从数据库上次启动后,对当前对数据库共进行了多少次select查询操作,insert操作等,除了这些还有有其他一系列com统计操作总数的变量)
注意状态变量只能用show status命令查看到,用show variables 命令无法查看。
sql_mode,这个变量比较特殊,它的值会影响到当前数据库的一些模式。
比如说把它设置为traditional,则在字符串类型char中的字段数据,如果输入的数据的长度多于定义字段时这个字符串char字段所允许的最大长度,此种语法将不被允许; 而如果不设置它之前,则是把超过最大长度后面的字符串给截断,把前面的内容存储到字段的记录中去。
注意traditional是多个sql_mode的集合,并非是一个。
最新版本mariadb默认的严格模式,如果表的字符集不是utf8格式(比如默认成了latin1格式),则无法把中文输入到这个表中的char类型字段中。
在mysql数据库中可以直接用set命令修改这个变量,注意它默认是一个global变量。注意global修改之后需要重新开启终端连接才会生效。
经过研究测试得知,sql_mode即是全局变量又是session变量(之前一直的错误认知主要就是把一个@当做了系统变量中的session变量的表示,实际上一个@variable就是代表着自定义的变量,不会代表系统变量,系统变量不论是什么都用@@表示,或者省略它)
Setting the GLOBAL variable requires the SYSTEM_VARIABLES_ADMIN or SUPER privilege and affects the operation of all clients that connect from that time on. Setting the SESSION variable affects only the current client. Each client can change its session sql_mode value at any time.
可见global设置之后要重新连接才能生效。
注意,global变量用set设置的时候前面必须要加上global关键字,session可以不用加,这个无一例外。
更详细的查看它的官方文档帮助
接着6,可见session的优先级比global要高,而且自己随时可以更改sessson变量的值,直接生效,退出连接再次连接就会失效;(猜想如果一个变量既有global又有session的话,登陆连接上数据库之后,这个session的值其实就是从global继承的,只不过每个session都可自己设置,更方便)。
而global更改之后必须重连数据库生效(当然服务器重启的话不论是global还是session都恢复配置文件以及默认设置)。
需要注意的一点就是show [global |session ] variables 或 status ; select [@@global | @@session.] variable ; set [ global | session ] system_var=value 等命令默认都是显示或者设置的session变量(因为它优先级高,且省略不写global显示的就是session),如果想要显示或者设置global变量,则前面必须加上global关键字。(这里注意set设置系统变量时@@也可省略,select不可,别总是弄混淆!)
命令select [global] variables\G;测试,global变量数量比session的要少,说明有些系统变量只有session没有global。不过show status状态变量在目前最新版mariadb中global和session数量一致,,但不代表它俩就没区别了,还是有区别的
附加:利用mysql的额外架构方式:

查询缓存
查询的执行过程
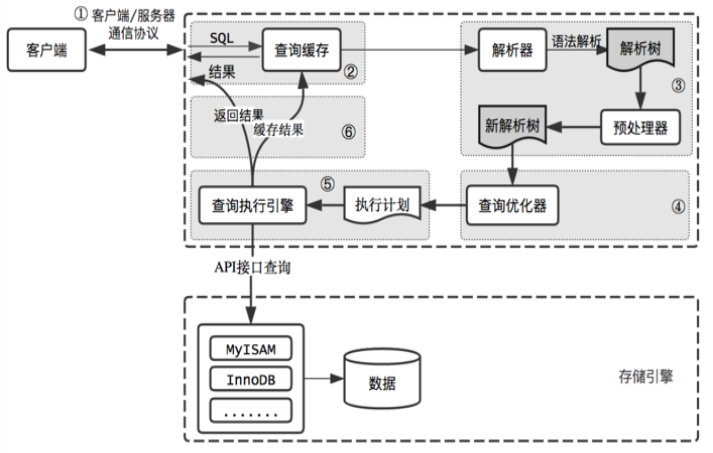
它利用不同数据库的自己的通讯协议,客户端连接服务器端,先查询缓存,如果没有再查询数据库(并将结果存入缓存),以实现加速查询(和下次查询相同目标加速)的效果。
查询缓存( Query Cache )原理
缓存SELECT操作或预处理查询的结果集和SQL语句,当有新的SELECT语句或预处理查询语句请求,先去查询缓存,判断是否存在可用的记录集,判断标准:与缓存的SQL语句,是否完全一样,区分大小写
优缺点
不需要对SQL语句做任何解析和执行,当然语法解析必须通过在先,这里不解析指的是命令的执行。
直接从Query Cache中获得查询结果,提高查询性能
查询缓存的判断规则,不够智能,也即提高了查询缓存的使用门槛,降低其效率;
查询缓存的使用,会增加检查和清理Query Cache中记录集的开销
哪些查询可能不会被缓存
查询语句中加了SQL_NO_CACHE参数(这个是select语句的参数)
查询语句中含有获得值的函数,包含自定义函数,如:NOW() CURDATE()、 GET_LOCK()、 RAND()、 CONVERT_TZ()等
对系统数据库的查询:mysql、 information_schema
查询语句中使用SESSION级别变量或存储过程中的局部变量
查询语句中使用了LOCK IN SHARE MODE、 FOR UPDATE的语句
查询语句中类似SELECT …INTO 导出数据的语句
对临时表的查询操作;存在警告信息的查询语句;不涉及任何表或视图的查询语句;某用户只有列级别权限的查询语句
事务隔离级别为Serializable时,所有查询语句都不能缓存
查询缓存相关的服务器系统变量(注意在variable中他们都是以byte单位显示的)
query_cache_min_res_unit:它表示在内存中给查询缓存中分配的最小分配单位(内存块),默认4k,较小值会减少浪费,但会导致更频繁的内存分配操作,较大值会带来浪费,会导致碎片过多,内存不足
query_cache_limit:单个查询结果能缓存的最大值,默认为1M,对于查询结果过大而无法缓存的语句,建议使用SQL_NO_CACHE参数
query_cache_size:查询缓存总共可用的内存空间;单位字节,必须是1024的整数倍,最小值40KB,低于此值有警报
query_cache_wlock_invalidate:如果某表被其它的会话锁定,是否仍然可以从查询缓存中返回结果,默认值为OFF,表示可以在表被其它会话锁定的场景中继续从缓存返回数据;ON则表示不允许
query_cache_type:是否开启缓存功能,取值为ON, OFF, DEMAND
SELECT语句的缓存控制
SQL_CACHE:显式指定存储查询结果于缓存之中
SQL_NO_CACHE:显式查询结果不予缓存
query_cache_type参数变量
query_cache_type的值为OFF或0时,查询缓存功能关闭
query_cache_type的值为ON或1时,查询缓存功能打开,SELECT的结果符合缓存条件即会缓存,否则,不予缓存,显式指定SQL_NO_CACHE,不予缓存,此为默认值
query_cache_type的值为DEMAND或2时,查询缓存功能按需进行,显式指定SQL_CACHE的SELECT语句才会缓存;其它均不予缓存
查询缓存相关的状态变量:SHOW GLOBAL STATUS LIKE ‘Qcache%';
Qcache_free_blocks:处于空闲状态 Query Cache中内存 Block 数
Qcache_total_blocks:Query Cache 中缓存所占的总Block数量 ,当Qcache_free_blocks相对此值较大时,可能用内存碎片,执行FLUSH QUERY CACHE清理碎片
Qcache_free_memory:处于空闲状态的 Query Cache 内存总量
Qcache_hits:Query Cache 命中次数
Qcache_inserts:向 Query Cache 中插入新的 Query Cache的次数,即没有命中的次数
Qcache_lowmem_prunes:记录因为内存不足而被移除出查询缓存的查询数(LRU算法:最近最少使用)
Qcache_not_cached:没有被 Cache 的 SQL 数,包括无法被 Cache 的 SQL以及由于 query_cache_type 设置的不会被 Cache 的 SQL语句
Qcache_queries_in_cache:在 Query Cache 中的 SQL 数量
命中率和内存使用率估算
注:此项有问题,说明查询缓存内部还是进行过优化的:查询缓存中内存块的最小分配单位query_cache_min_res_unit :
(query_cache_size - Qcache_free_memory) / Qcache_queries_in_cache
查询缓存命中率 :
Qcache_hits / ( Qcache_hits + Qcache_inserts ) 100%
查询缓存内存使用率:
(query_cache_size – qcache_free_memory) /query_cache_size 100%
优化查询缓存

其中需要解释的点:
频繁发生验证工作:验证工作就是验证这个缓存是否还有效。比如缓存的结果放到内存查询缓存区之后,是否把这个缓存的结果的数据(比如说一张表)在数据库中进行了频繁修改。如果这样的话这个缓存的结果必然就无效了,需要重新缓存,这就造成命中率低。
InnoDB存储引擎的缓存
InnoDB存储引擎的缓冲池:
通常InnoDB存储引擎缓冲池的命中不应该小于99%
查看相关状态变量:
show global status like 'innodb%read%'\G
Innodb_buffer_pool_reads: 表示从物理磁盘读取页的次数
Innodb_buffer_pool_read_ahead: 预读的次数
Innodb_buffer_pool_read_ahead_evicted:预读页,但是没有读取就从缓冲池中被替换的页数量,一般用来判断预读的效率
Innodb_buffer_pool_read_requests: 从缓冲池中读取页次数
Innodb_data_read: 总共读入的字节数
Innodb_data_reads:发起读取请求的次数,每次读取可能需要读取多个页
Innodb缓冲池命中率计算:

平均每次读取的字节数:

注意点4(查询缓存):
因为查询缓存是基于HASH值来存放的,也就是说把客户的select查询命令的的SQL语句进行hash运算之后的结果给存储到缓存中。如果用户的select语句中(哪怕大小写或者空格)稍有不同,就会被看作是不同的缓存语句(hash值不同),会被分别存储为两条缓存记录。
注意查询缓存的内存中一条记录存放的有两部分内容:一个是查询语句select的hash值,另外一部分就是这个查询语句对应的查询结果。
query_cache_size是一个global类型的dynamic变量,不过在runtime级别修改时不能加单位(M K等),只能用数值。只有在配置文件中写入它的值的时候才可以加上这些单位。
注意Qcache_tital_blocks是目前缓存中总的已经是使用的blocks数量,它大于等于Qcache_queries_in_cache,因为后者中的一个缓存记录可能占用多个blocks(在默认情况下也就是大于4096bytes时)
Qcache_free_memory是当前总的未使用的内存memory,并非query_cache_size
复习知识点:
session代表一个会话,只要新开一个终端就开启了一个新的会话,开启一个新的连接,也是开启了一个新的会话。更详细看前面介绍。
session变量作用此session,runtime设置直接生效,关闭seession终端重连服务器便会失效;
global影响整个mysql服务器的所有终端,runtime修改时只影响本次mysql服务器的runtime(注意需要重新开的终端session才会生效,之前已经开启的终端session的不变,因为session变量优先级高,改global没有改session不会影响它,除非同时修改session变量),mysql服务重启(下一个runtime)global变量也会失效。
只有配置文件my.cnf中设置的global 变量才能跨越runtime,每次服务启动都生效。不过注意在这里修改的话要重启服务~
索引1
索引:
是特殊数据结构,定义在查找时作为查找条件的字段,在MySQL又称为键key,索引通过存储引擎实现
优点:
索引可以降低服务需要扫描的数据量,减少了IO次数
索引可以帮助服务器避免排序和使用临时表
索引可以帮助将随机I/O转为顺序I/O
缺点:
占用额外空间,影响插入速度
索引类型:
B+ TREE、 HASH、 R TREE
聚簇(集)索引、非聚簇索引:数据和索引是否存储在一起
主键索引、二级(辅助)索引
稠密索引、稀疏索引:是否索引了每一个数据项
简单索引、组合索引
左前缀索引:取前面的字符做索引
覆盖索引:从索引中即可取出要查询的数据,性能高
二叉树:根,枝,叶的左右比重可能不同
红黑树:尽量让叶子的比重平均

B TREE
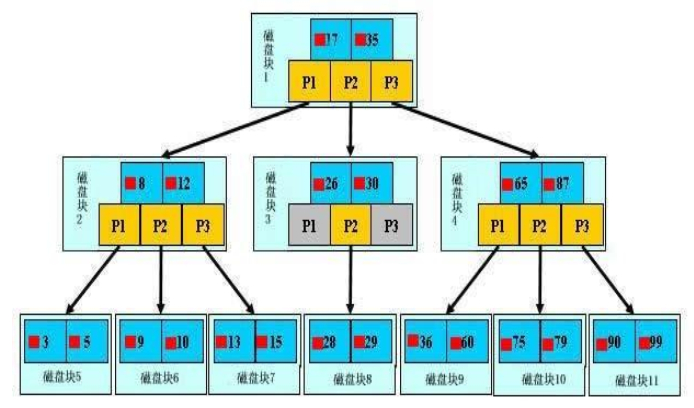
B+ TREE


B+Tree索引:顺序存储,每一个叶子节点到根结点的距离是相同的;左前缀索引,适合查询范围类的数据
可以使用B+Tree索引的查询类型:
全值匹配:精确所有索引列,如:姓zhang,名yinsheng,年龄24
匹配最左前缀:即只使用索引的第一列,如:姓wang
匹配列前缀:只匹配一列值开头部分,如:姓以w开头的
匹配范围值:如:姓duan和姓zhang之间
精确匹配某一列并范围匹配另一列:如:姓zhang,名以y开头的
只访问索引的查询
B+Tree索引的限制:
如不从最左列开始,则无法使用索引,如:查找名为yinsheng,或姓为g结尾
不能跳过索引中的列:如:查找姓zhang,年龄24的,只能使用索引第一列
特别提示:
索引列的顺序和查询语句的写法应相匹配,才能更好的利用索引
为优化性能,可能需要针对相同的列但顺序不同创建不同的索引来满足不同类型的查询需求
Hash索引
Hash索引:基于哈希表实现,只有精确匹配索引中的所有列的查询才有效,索引自身只存储索引列对应的哈希值和数据指针,索引结构紧凑,查询性能好
Memory存储引擎支持显式hash索引,InnoDB和MyISAM存储引擎不支持
适用场景:只支持等值比较查询,包括=, <=>, IN()
不适合使用hash索引的场景:
不适用于顺序查询:索引存储顺序的不是值的顺序
不支持模糊匹配
不支持范围查询
不支持部分索引列匹配查找:如A,B列索引,只查询A列索引无效
6.1 空间数据索引R-Tree( Geospatial indexing )
MyISAM支持地理空间索引,可以使用任意维度组合查询,使用特有的函数访问,常用于做地理数据存储,使用不多
InnoDB从MySQL5.7之后也开始支持
6.2 全文索引(FULLTEXT)
在文本中查找关键词,而不是直接比较索引中的值,类似搜索引擎
InnoDB从MySQL 5.6之后也开始支持
聚簇和非聚簇索引

外加主键和二级索引

冗余和重复索引:
冗余索引:(A),(A,B)
重复索引:已经有索引,再次建立索引
索引优化策略:
独立地使用列:尽量避免其参与运算,独立的列指索引列不能是表达式的一部分,也不能是函数的参数,在where条件中,始终将索引列单独放在比较符号的一侧
左前缀索引:构建指定索引字段的左侧的字符数,要通过索引选择性来评估
索引选择性:不重复的索引值和数据表的记录总数的比值
多列索引:AND操作时更适合使用多列索引,而非为每个列创建单独的索引
选择合适的索引列顺序:无排序和分组时,将选择性最高放左侧
索引优化建议
只要列中含有NULL值,就最好不要在此例设置索引,复合索引如果有NULL值,此列在使用时也不会使用索引
尽量使用短索引,如果可以,应该制定一个前缀长度
对于经常在where子句使用的列,最好设置索引
对于有多个列where或者order by子句,应该建立复合索引
对于like语句,以%或者‘-’开头的不会使用索引,以%结尾会使用索引
尽量不要在列上进行运算(函数操作和表达式操作)
尽量不要使用not in和<>操作
SQL语句性能优化
查询时,能不要就不用,尽量写全字段名
大部分情况连接效率远大于子查询
多表连接时,尽量小表驱动大表,即小表 join 大表
在有大量记录的表分页时使用limit
对于经常使用的查询,可以开启缓存
多使用explain和profile分析查询语句
查看慢查询日志,找出执行时间长的sql语句优化
管理索引
创建索引:
CREATE INDEX [UNIQUE] index_name ON tbl_name (index_col_name[(length)],...);
ALTER TABLE tbl_name ADD INDEX index_name(index_col_name);
help CREATE INDEX;
删除索引:
DROP INDEX index_name ON tbl_name;
ALTER TABLE tbl_name DROP INDEX index_name(index_col_name);
查看索引:
SHOW INDEXES FROM [db_name.]tbl_name;
优化表空间:
OPTIMIZE TABLE tb_name;
查看索引的使用
SET GLOBAL userstat=1;
SHOW INDEX_STATISTICS;
EXPLAIN
通过EXPLAIN来分析索引的有效性
EXPLAIN SELECT clause
获取查询执行计划信息,用来查看查询优化器如何执行查询
输出信息说明:
参考 https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
id: 当前查询语句中,每个SELECT语句的编号
复杂类型的查询有三种:
简单子查询
用于FROM中的子查询
联合查询:UNION
注意:UNION查询的分析结果会出现一个额外匿名临时表
select_type:
简单查询为SIMPLE
复杂查询:
SUBQUERY 简单子查询
PRIMARY 最外面的SELECT
DERIVED 用于FROM中的子查询
UNION UNION语句的第一个之后的SELECT语句
UNION RESULT 匿名临时表
table:SELECT语句关联到的表
type:关联类型或访问类型,即MySQL决定的如何去查询表中的行的方式,以下顺序,性能从低到高
ALL: 全表扫描
index:根据索引的次序进行全表扫描;如果在Extra列出现“Using index”表示了使用覆盖索引,而非全表扫描
range:有范围限制的根据索引实现范围扫描;扫描位置始于索引中的某一点,结束于另一点
ref: 根据索引返回表中匹配某单个值的所有行
eq_ref:仅返回一个行,但与需要额外与某个参考值做比较
const, system: 直接返回单个行
possible_keys:查询可能会用到的索引
key: 查询中使用到的索引
key_len: 在索引使用的字节数
ref: 在利用key字段所表示的索引完成查询时所用的列或某常量值
rows:MySQL估计为找所有的目标行而需要读取的行数
Extra:额外信息
Using index:MySQL将会使用覆盖索引,以避免访问表
Using where:MySQL服务器将在存储引擎检索后,再进行一次过滤
Using temporary:MySQL对结果排序时会使用临时表
Using filesort:对结果使用一个外部索引排序
注意点5(索引)
索引在大部分情况下会提高查询效率(小部分就是比如说就在数据库表中的最前面的几条记录,直接查询更快),不过它会影响record插入(insert)的效率,因为插入新数据之后还要更新一下它的索引(或者叫目录)。
B 树是根据表中某一字段(比如ID号,主键)进行区间分段,然后再在分段的区间上继续进行分段进行查询数据的索引表的建立,并以此为依据进行查询的。
它的优点是相对于二叉树来说,分支变多但分级变少,容易查询
不过它的缺点是在索引表的各个节点上都包含有分段的ID这些分段边界ID号的record的数据,会占用很多空间且影响查询速率,并且让查询的效率变得不同(比如说查询一个分段边界ID的数据和查询不是分段边界ID的数据,后者会比前者要多搜索一个分支级别);同时如果对数据进行部分连续范围查询的话,每次都要从根节点往下到叶子节点进行查询,降低了查询效率(因为每个叶子节点之间没有关联)。
因此目前都用的是B+ 树的索引结构,它的所有的非叶子节点都只有指针信息(指向下一级的索引节点)而不包含数据,只有叶子结点才有数据。同时每个叶子节点之间不仅包含有此部分叶子结点包含的所有record的数据(一个叶子结点包含多个record的数据,不要认为只包含一个record),也包含有和它相连的下一个叶子结点的位置信息(指向下一个叶子节点)
因此B+ 数进行索引查询的时候,每个数据查询的效率是一样的(因为都要到叶子结点的层级,索引节点不包含数据),同时它可以进行范围搜索。同时它相比于B数来说,因为索引节点没有了数据,它更加的矮胖,查询效率更高。
接2,B+树是左前缀索引,顺序存储模式:它代表把一个字段创建索引之后,此索引是按照从左往右左前缀字符进行排序存储的,并将每个记录的真正的数据的位置的指针放到此索引表中对应的索引记录上。
当对这个索引进行查询的时候,虽然说B+ 数是顺序存储的结果(按照数字ID或者字符排列顺序,类似ls的排序,或者说字符集的排序顺序),但是查询的时候只能通过最左边的匹配字符进行查询,而不能跳过左边的字符按照右边的字符进行查询。
比如说 select from students where name like 'zhang%' 和
select from students where name like '%yinsheng[%]' 的查询方式,前者可以利用建立在name字段上的索引,而后者则相当于并没有利用到此索引,和直接查询没有区别。因此要避免使用后者的查询方式,也就是不能用跳过左边的字符的查询方式。
同时,如果对两个或多个字段建立B+ 复合索引,则根据建立的复合索引的查询,也是要根据复合索引建立时的字段的先后顺序进行查询,它也是左前缀索引。因为这个索引的建立过程就是从左往右的进行一个字段一个字段的排序,后面的字段没有前面的字段优先级高(后面的字段的排序会受到前面的字段排序结果的限制,后面字段的排序只是对前面字段的排序的进一步排序和补充,只有前面的字段记录内容相同的情况下,复合索引才有意义,如果前面的字段每一个都不相同,则后面的字段进行复合索引的排序毫无意义)
相同的字段,不同的建立复合索引的顺序,则索引表的查询也是不同的,要注意。先根据最左边的字段进行查询,然后进行下一个次左边的字段进行查询,以此类推。同时也要注意,在每个字段内查询的时候也要左前缀查询,上面已经介绍。
从3中也可以看出,建立索引的字段要保证大部分的数据内容都不一样,不然就没有意义了。一个表的主键本身就是一个索引,叫做主键索引(创建主键的时候就已经自定定义它的字段为索引了),而唯一键也是一个索引叫唯一键索引(注意它可以为空,尽量不让它为空)
InnoDB的聚簇索引排列:在建立表的时候,有且只能有一个(复合)主键,而这个主键索引的叶子节点上最终就放着这个表的主键的各个顺序排列的值,以及其对应的每个记录的数据信息。这些直接把数据放在叶子节点上的索引表就叫做聚簇索引。
而这个聚簇索引的二级索引,比如说针对这个表的另外的非主键字段建立索引,则这个索引表的叶子节点上存放的内容是这个索引字段的顺序排列的值,以及其相对应的主键的字段的值(注意和主键索引的区别)。通过这个索引查询的时候,找到叶子节点之后还需去找主键索引进行二次查询,最终才能找到全部的数据。
由此也可以看出,一个表的主键只能有一个,不然这种聚簇索引存放方式将会导致数据存放的位置有多个重复的地方(如果能建立多个主键,则多个主键索引表的叶子节点上都存放数据,),浪费空间。
简单来说数据和索引放在一起就是聚簇索引,分开存放就是非聚簇索引。上面的二级索引就是非聚簇索引(不包含全部数据,只包含索引数据),主键索引就是聚簇索引(包含全部字段信息)。innodb引擎就是聚簇索引引擎,只有两个数据文件。
MyIASM引擎就是非聚簇索引,有三个数据文件,它的主键索引和二级索引没有很大的区别,都是非聚簇索引,因为都不包含数据,都只包含指针指向真正的数据存放的位置。
B+树的叶子索引是稠密索引,上面的索引节点是稀疏索引。
覆盖索引就类似B树的数据放在索引中的方式,可从索引出提取出数据。
explain select语句:可以查看是否利用到了索引来进行这个select语句的查询过程
注意select命令在实际的执行过程中,它先利用查询缓存进行缓存查询,如果没有匹配结果再进入表中利用可能的index索引查询,如果没有index则最后再直接遍历查询表进行查询。
用explain selece 语句 命令经过测试发现对于查询缓存来说没有任何影响,既不会增加hits,也不会增加inserts,同时也没有被记录到not-cached中,反正它的数据没有任何变化。
有些情况下即使建立了index表也有可能不用它来查询,比如说要查询的结果过多,占了整个表的所有记录的一大部分,则系统自动就进入表中去遍历了,而不是使用index.
可在配置文件中设置userstat为1, 重启服务之后则mysql便可以记录索引使用信息,利用show index_statistics 查看。
如果发现某个索引使用很少或者几乎不使用,可以删除掉次索引用以节省空间。















 226
226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









