








引言
深度强化学习最近取得了很多进展,并在机器学习领域得到了很多的关注。传统的强化学习局限于动作空间和样本空间都很小,且一般是离散的情境下。然而比较复杂的、更加接近实际情况的任务则往往有着很大的状态空间和连续的动作空间。实现端到端的控制也是要求能处理高维的,如图像、声音等的数据输入。前些年开始兴起的深度学习,刚好可以应对高维的输入,如果能将两者结合,那么将使智能体同时拥有深度学习的理解能力和强化学习的决策能力。2013和2015年DeepMind的DQN可谓是将两者成功结合的开端,它用一个深度网络代表价值函数,依据强化学习中的Q-Learning,为深度网络提供目标值,对网络不断更新直至收敛。DQN用到了两个关键技术,一是用来打破样本间关联性的样本池,二是使训练稳定性和收敛性更好的固定目标网络。DQN可以应对高维输入,而对高维的动作输出则束手无策。随后,同样是DeepMind提出的DDPG,则可以解决有着高维或者说连续动作空间的情境。它包含一个策略网络用来生成动作,一个价值网络用来评判动作的好坏,并吸取DQN的成功经验,同样使用了样本池和固定目标网络,是一种结合了深度网络的Actor-Critic方法。
一、强化学习
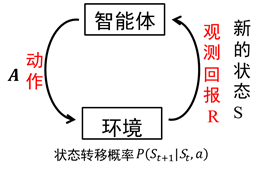
智能体在完成某项任务时,如上图所示,首先通过动作A与周围环境进行交互,在动作A和环境的作用下,智能体会产生新的状态,同时环境会给出一个立即回报。如此循环下去,智能体与环境进行不断地交互从而产生很多数据。强化学习算法利用产生的数据修改自身的动作策略,再与环境交互,产生新的数据,并利用新的数据进一步改善自身的行为,经过数次迭代学习后,智能体能最终地学到完成相应任务的最优动作(最优策略)。这就是一个强化学习的过程。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 7889
7889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









