






首先放上项目地址,喜欢的话就star一个吧!
Github:https://github.com/nashaofu/markdown365-parser
效果预览地址:https://nashaofu.github.io/markdown365-parser/
react的发布让前端摆脱了使用jQuery一点一点修改DOM的历史。对于后来的很多框架都产生非常重要的影响。其中最为重要的概念就是Virtual DOM了,在后面vue也借鉴了这一概念,不过这两个框架对Virtual DOM的实现是不一样的。
作为开发者,肯定是离不开markdwon的,markdwon能够用很简洁的语法表现出很好的排版样式。所以也就关注了一些markdwon的解析器,闲来无事,就有了自己造一个轮子的想法。在GitHub上找了几个比较流行的markdwon解析的库之后选择了marked(https://github.com/chjj/marked)来研究,选择marked的原因主要是从代码量和支持语法两个方面考虑的,由于自己单枪匹马的干,所以选用的库不能太大了(我怕搞不定),marked的源码只有1000多行,而且代码结构还是比较清晰的,整个扒下来也就定义了三个类,分别是Lexer(块级语法解析)、InlineLexer(行内语法解析)和Renderer(渲染成html字符串),这里就不过多说明marked了,其中我借鉴了Lexer和InlineLexer两个类的实现。

支持语法
项目已经支持了比较常用的一些语法,具体请查看https://github.com/nashaofu/markdown365-parser/blob/master/Grammar.md
使用示例如下
<html> <head> <meta charset="utf-8" /> <title>markdown365-parsertitle> <script src="dist/markdown365-parser.js">script> head> <body> <div id="previiew">div> <script> const markdwon = '## markdown365-parser' const parser = new Markdown365Parser({ gfm: true, tables: true, breaks: true, pedantic: false, smartypants: false, base = '', $el: document.querySelector('#previiew') }) parser.parse(markdown)script> body>html>参数说明
gfm: GitHub flavored markdown语法支持. 默认: true
tables: GFM tables语法支持. 必须要求gfm为true, 默认: true
breaks: GFM line breaks解析规则支持. 必须要求gfm为true. 默认: false
pedantic: 是否尽可能遵守markdown.pl的部分内容. 不去掉一些不严格的内容. 默认: false
smartypants: 是否替换特殊符号. 默认: false
base:这里是用来指定markdwon文档中的链接地址、图片地址的前置链接,如markdown中的所有图片都指向另一个域的时候,base就可以设置为指定域名。这里这个参数主要是考虑到编写桌面markdown编辑器用的,因为编辑器打开markdown文件时,对应的图片的路径要转换为相对markdown文件所在目录的相对路径,具体可参考我的另一个项目markdown365(https://github.com/nashaofu/markdown365)
$el:文档要渲染到的dom节点
源码目录结构
src│ index.js # 入口文件 Parser类│ utils.js # 工具代码│├─lexer # markdown解析相关代码 把字符串解析为vnode│ block-lexer.js # 块级语法解析 BlockLexer类│ block-rules.js # 块级语法解析规则│ index.js # Lexer类│ inline-lexer.js # 行内语法解析 InlineLexer类│ inline-rules.js # 行内语法解析规则│├─renderer # 渲染类 把vnode diff并渲染到真实dom中│ index.js # Renderer类│└─vnode # vnode定义代码 index.js # 传入节点信息返回vnode vnode.js # Vnode类Markdwon解析流程介绍
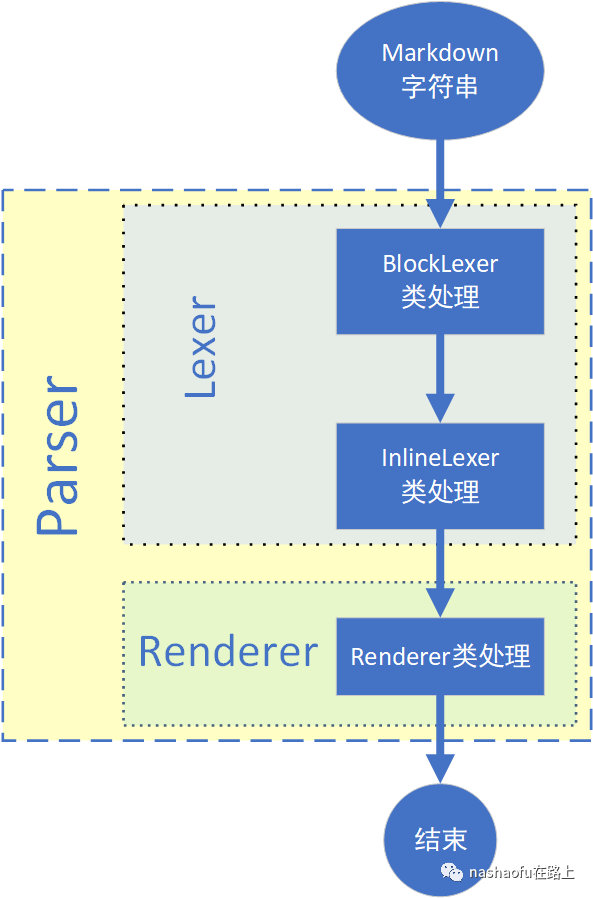
下面分别介绍每一个类的作用
Parser类:Parser类初始化后就可以调用parse方法,然后就开始执行lex和render
Lexer类:Lexer包含BlockLexer和InlineLexer两个部分,分别用来解析块级语法和行内语法,其中比较重点的是lexInline方法,该方法中会遍历解析块级语法解析后的vnode对象,如果vnode对象的source存在就要解析,并且由于块级节点解析后的会存在text类型的未解析的节点,即text类型的节点中还可以解析出一些语法。例如:一段文字中还包含链接或者斜体等,这些都是属于行内解析的范畴,但我们知道text类型的节点是不存在子节点的,所以解析出来的vnode对象不能挂载到原text节点的子节点上,所以就得把解析出来的节点挂载到原text节点的父节点上,并且对应的位置也不能错乱
行内解析说明,如下代码只进行说明,实际情况子节点还有parent属性,该属性指向父节点
进行行内解析前
const vnode = { uid: 0, $el: null, tag: 'li', type: 'node', parent: null, attributes: {}, text: '', source: null, children: [ { uid: 1, $el: null, tag: null, type: 'text', children: [], attributes: {}, text: '', source: '[x] [google](https://www.google.com/)' } ]}- 行内解析后应为
const vnode = { uid: 0, $el: null, tag: 'li', type: 'node', parent: null, attributes: {}, text: '', source: null, children: [ { uid: 1, $el: null, tag: 'input', type: 'node', attributes: { checked: 'checked', disabled: 'disabled', type: 'checkbox' }, text: '', source: null, children: [] }, { uid: 2, $el: null, tag: 'a', type: 'node', attributes: { href: 'https://www.google.com/' }, text: '', source: null, children: [ { uid: 3, $el: null, tag: null, type: 'text', attributes: {}, text: 'google', source: null, children: [] } ] } ]}BlockLexer类:BlockLexer类最主要的方法是lex,该方法是正真语法解析部分,在方法内部使用while循环,直到src被解析完才返回vnode,并且里面的每一个解析规则的顺序是不能随意更换的,因为规则之间会存在相互包含的关系,例如一个h1语法段落肯定是可以被解析为p标签的,所以这就要求h1的解析规则放在p标签规则解析的前面,如果不能匹配才会匹配为p标签。其次,对于lex的另两个参数的作用,top参数主要是为了区分一段文字是解析为p标签还是解析为text类型的节点,如果没有父节点就解析为p标签,反之则为text节点。**bq**参数用来区分是否为blockquote标签下的内容,在blockquote标签下的内容不会被解析到参考式的链接中去,其实也就是参考式的链接只能写在顶级,否则不会生效
InlineLexer类:InlineLexer中主要的方法是lex,lex有两个参数,其中src为带解析的源码字符串,parent为的当前解析text的父元素,该参数主要用来判断tasklink,要进入tasklink解析条件,必须要在父元素为li才行,否则不会解析为tasklist
Vnode类:
export default class VNode { static uid = 0 // 每次创建一个vnode就会加1,这是每个vnode的唯一标识 constructor ({ $el = null, tag = null, type = 'node', // 可为node/text/html parent = null, children = [], attributes = {}, text = null, source = null } = {}) { this.uid = VNode.uid++ this.$el = $el this.tag = tag this.type = type this.parent = parent this.children = children this.attributes = attributes this.text = text this.source = source }}Renderer类:Renderer类参考了vue中的render(https://github.com/vuejs/vue/blob/ef56410a2ca19641bd96bbc04056219fbc0bcb3e/src/core/vdom/patch.js#L700)实现方法,其中主要是在对比的时候就对真实dom进行修改,当patch结束dom更新也就结束了
diff原理说明
diff原理基本和vue的思路一致,只是在vue diff的基础上做了简化和修改。这里可以打开[源码](https://github.com/nashaofu/markdown365-parser/blob/master/src/renderer/index.js#L48)对比着看,同时这里也推荐一篇对于vue diff源码解析的文章[Vue原理解析之Virtual Dom](https://segmentfault.com/a/1190000008291645)
1. 单个节点进行比较
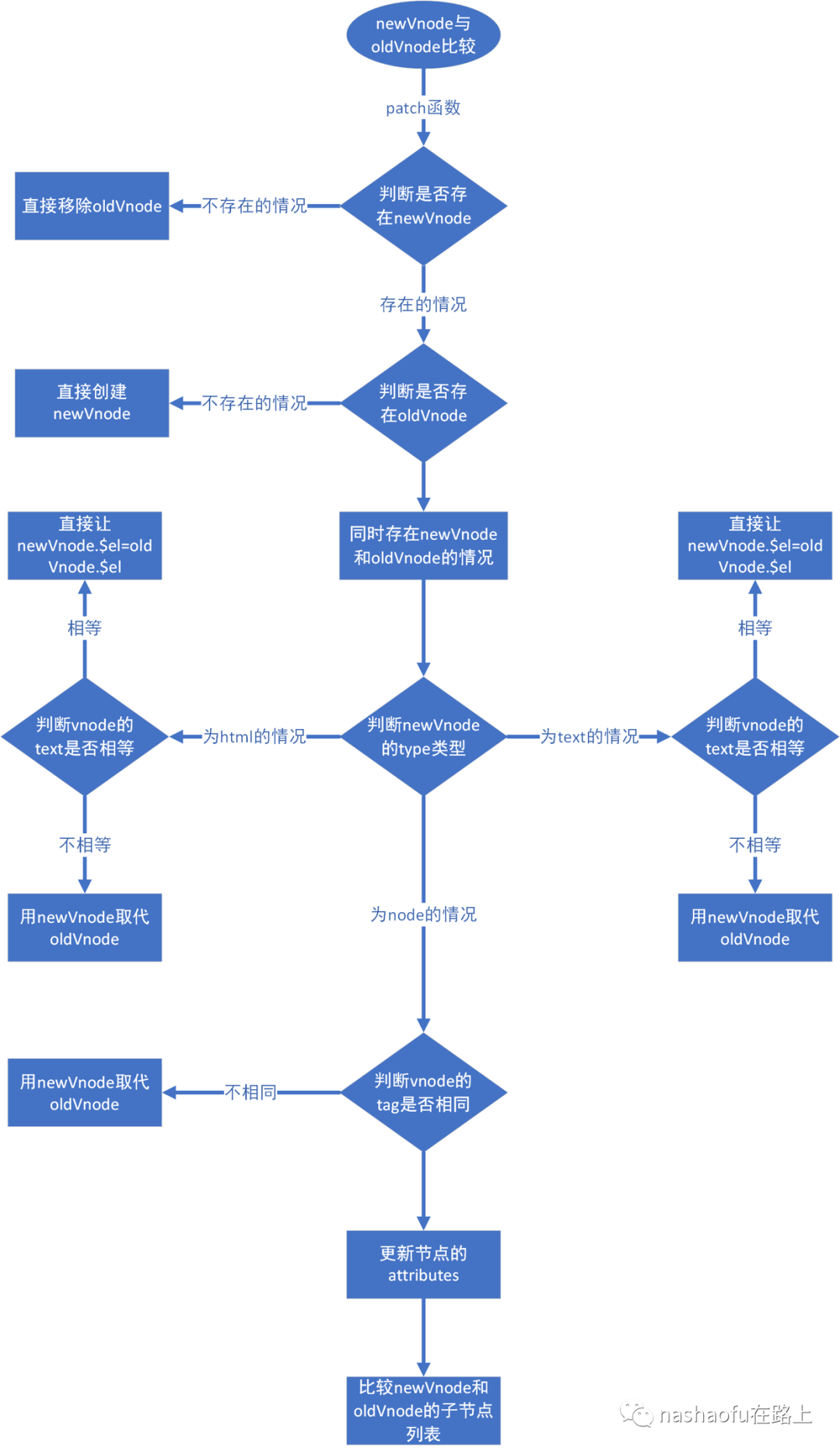
2. 子节点列表diff,子节点相对于单个节点的对比就复杂很多了,会存在列表中添加节点、删除节点、节点位置移动、某一个节点被替换这几种基本情况。这里先放上patchChildren方法的源码位置https://github.com/nashaofu/markdown365-parser/blob/c2a74b028e0cd18ff51f5430c2536469a61435a2/src/renderer/index.js#L96。
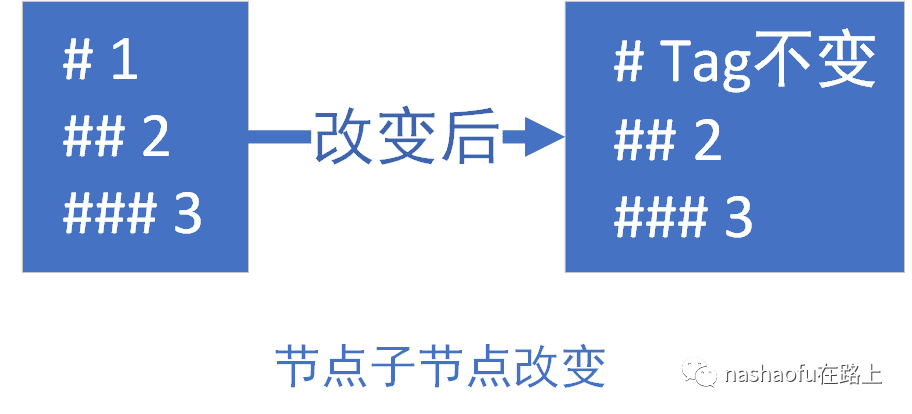
1. 如果oldStartVnode.tag == newStartVnode.tag,那么就认为这两个节点是匹配的,即认为为相同节点,直接对比更新这两个节点,如:在末尾追加节点这种情况或者节点子元素变化
2. 如果oldEndVnode.tag == newEndVnode.tag,那么就用新的节点去更新旧节点,如:第一个节点变为了其他类型的节点

3. 如果oldStartVnode.tag == newEndVnode.tag,那么就对比这两个节点,并且将真实dom节点移动到newEndVnode.tag所在的位置
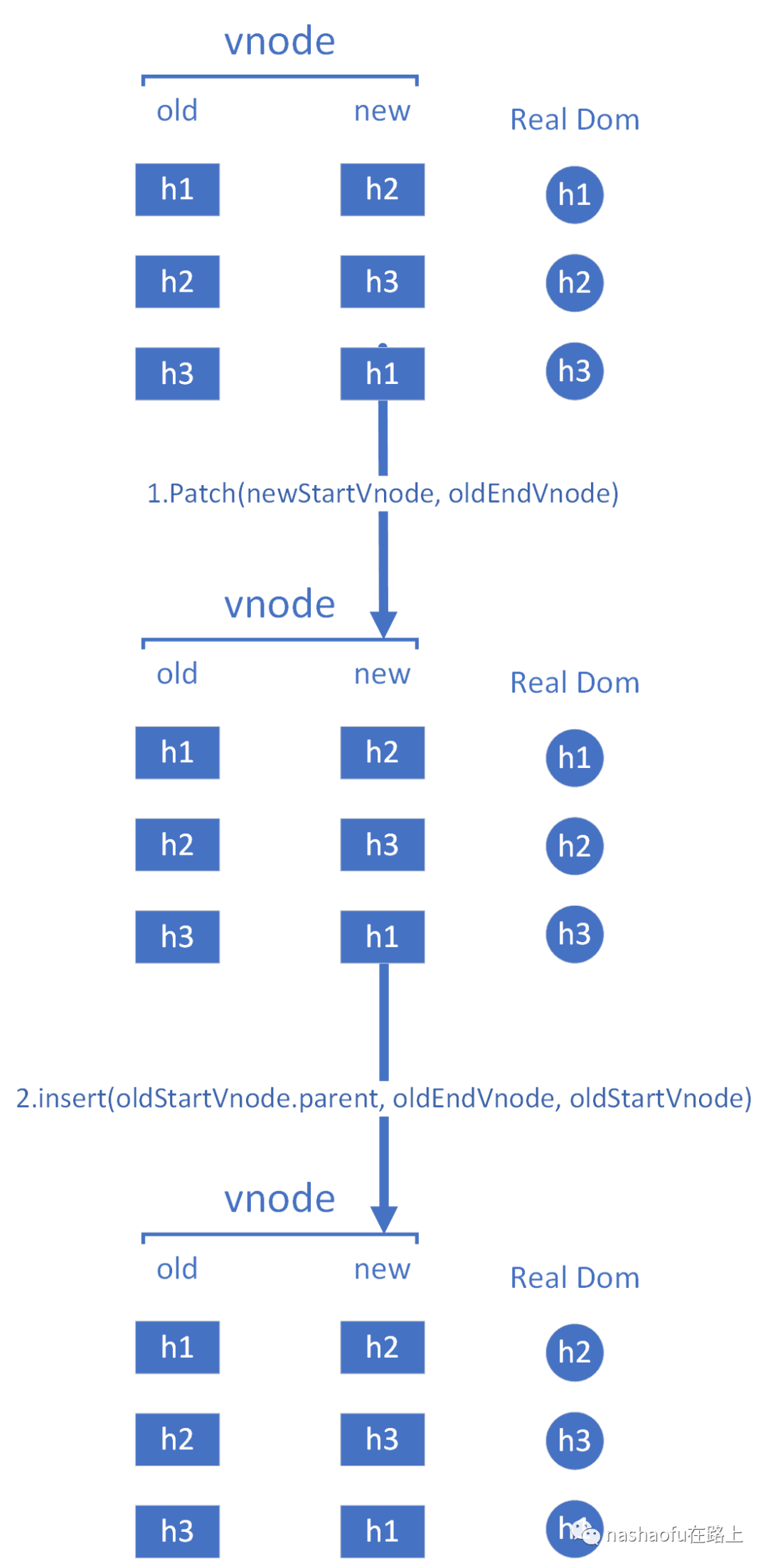
4. oldEndVnode.tag == newStartVnode.tag的情况基本和3一样,只是移动节点的位置要反过来,这里就不放图了
5. 如果以上几种情况都不能满足的话,就让节点newStartVnode取代oldStartVnod
循环结束之后的条件判断
1. 如果oldStartIdx > oldEndIdx,比如在末尾追加节点的情况,这是就需要插入新节点
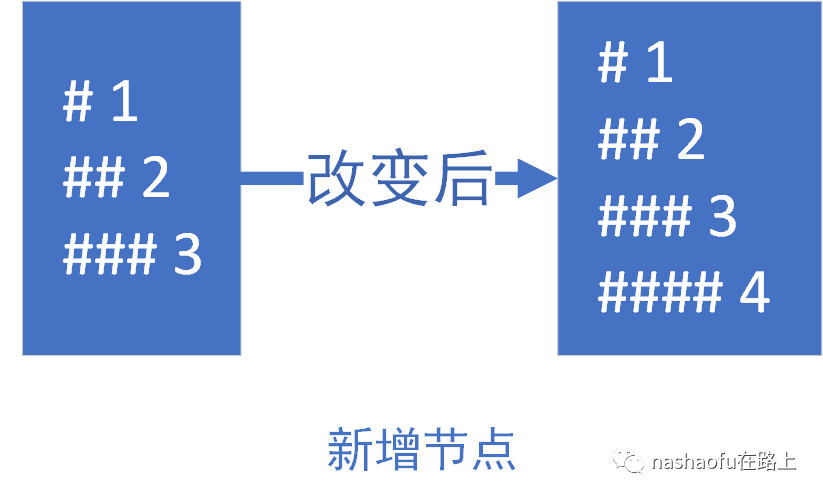
2. 如果newStartIdx > newEndIdx,这种情况可以用移除节点来做类比,所以就需要移除旧的多余的节点
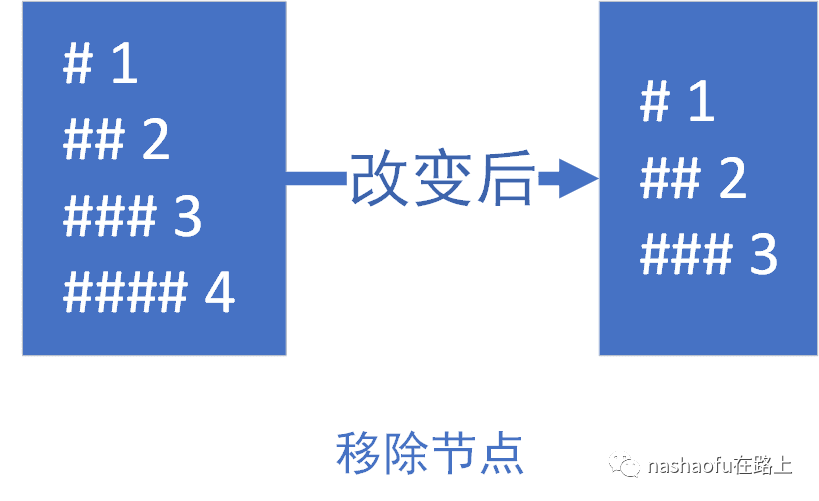
对于整个render的diff来说,整体的效率还是很低,还不完善,特别是对于子节点列表对比的方法,还有很大的优化空间
最后
项目目前很多功能还不是很完善,对于markdwon的解析也只是做了比较基础的支持,还有一部分语法没有能够支持,特别是对于html的支持还存在BUG,并且目前对于语法如何扩展也还存在问题,当前的代码结构不易于扩展语法。对于diff部分也还有很多需要改进的地方。所以如果有兴趣,欢迎提交pr。
请不要把项目应用在生产环境中,因为VDOM主要作用是让我们能减少真实DOM的操作,但这是需要一些条件的。例如在列表循环中,我们会使用唯一的key来标识VDOM,但在markdown这种情况显然是不可能的,我们不能规定用key,所以在列表对比中效率就会很低;同时对于markdown而言,我们一般不会有特别大的文本,所以很少会有性能问题。















 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









