






heritrix作为一个比较经典的开源爬虫,写这篇文章目的是因为,3.X之后的heritrix的介绍以及配置的文章比较少了。
heritrix 3.x 以后使用maven 2配置jar包引用,但是总是有好多包没法从maven库下载。所以,这里讲的环境搭建直接使用了编译好的工程来做,heritrix-3.2.0-dist.tar.gz以及源码压缩包heritrix-3.2.0-src.tar.gz
具体方法如下:
新建java工程(非maven)
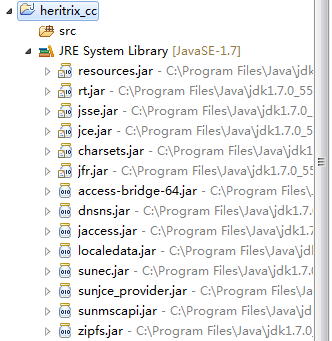
将heritrix-3.2.0-dist.tar.gz解压放到工程目录
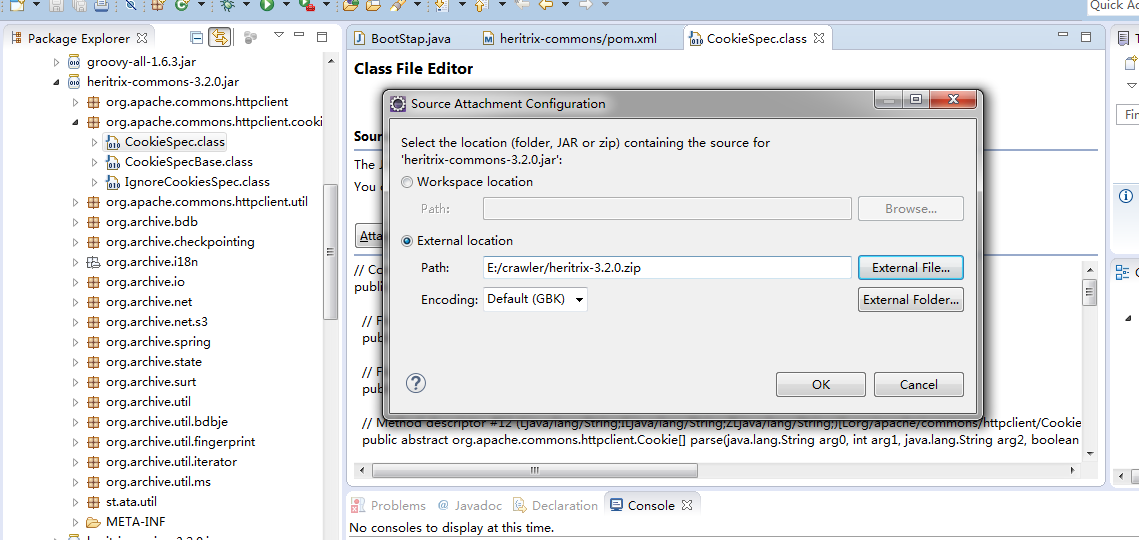
添加源代码引用,使用heritrix-3.2.0-src.zip:
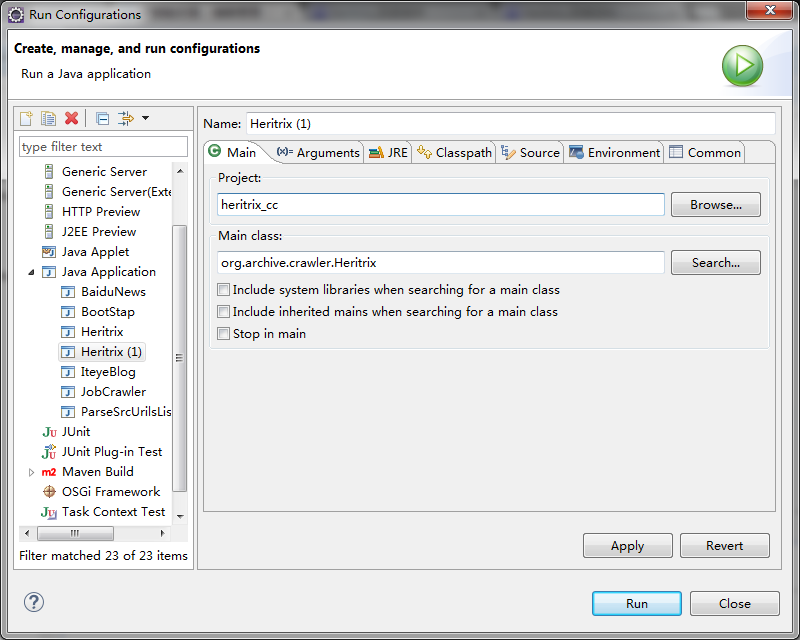
尝试启动heritrix,heritrix内核使用jetty所以不需要依附tomcat或者其他web容器。
入口类是这个org.archive.crawler.Heritrix
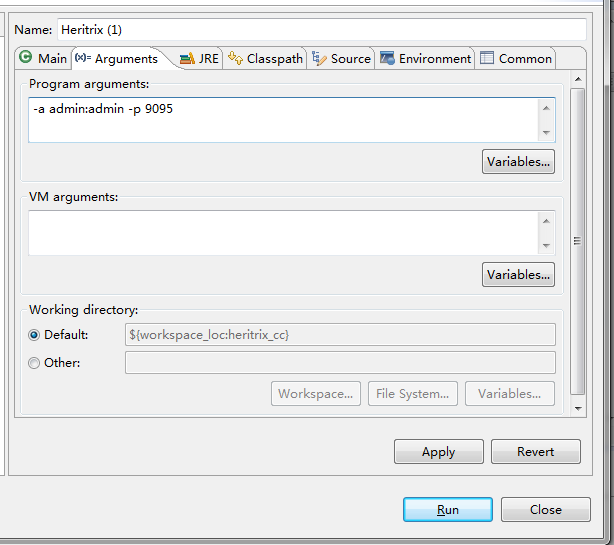
启动成功:
Oracle Corporation Java(TM) SE Runtime Environment 1.7.0_55-b13
Using ad-hoc HTTPS certificate with fingerprint...
SHA1:7C:99:FC:BC:62:13:DD:F3:B8:24:2F:EF:B7:60:0E:E2:AF:A1:13:8E
Verify in browser before accepting exception.
2014-07-11 01:54:31.408 警告 thread-1 org.archive.crawler.framework.Engine.findJobConfigs() invalid job directory: .\jobs\.gitignore where job expected from: .\jobs\.gitignore
2014-07-11 01:54:31.550:INFO::Logging to STDERR via org.mortbay.log.StdErrLog
2014-07-11 01:54:31.552:INFO::jetty-6.1.26
2014-07-11 01:54:31.753:INFO::Started SslSocketConnector@localhost:9095
engine listening at port 9095
operator login set per command-line
NOTE: We recommend a longer, stronger password, especially if your web
interface will be internet-accessible.
Heritrix version: 3.2.0
请求: https://localhost:9095/
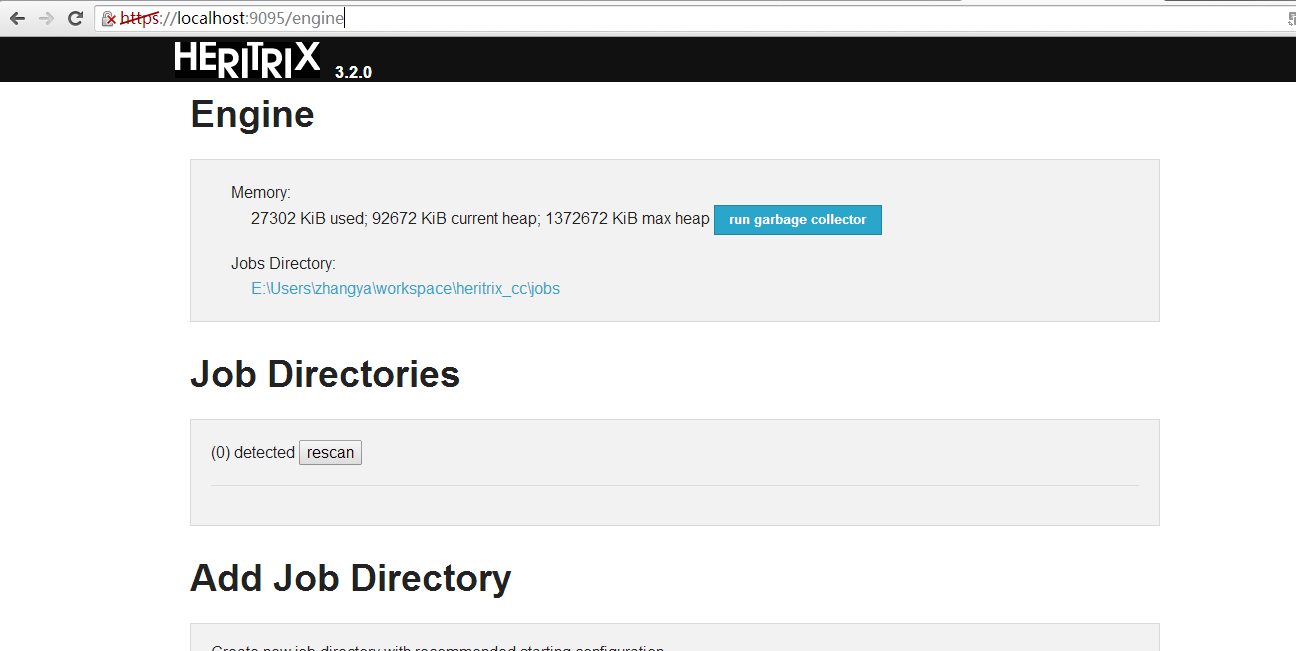
现在可以正常使用了。















 4787
4787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









