






过节了也没痛快~~ 今天在补发吧 延庆废品世家的太不通人性了
一、RTOS多线程
裸机系统
裸机系统通常分成轮询系统和前后台系统。
1 轮询系统
轮询系统即是在裸机编程的时候,先初始化好相关的硬件,然后让主程序在一个死循环里面不断循环,顺序地做各种事情,大概的伪代码具体如代码清单所示:
轮询系统是一种非常简单的软件结构,通常只适用于那些只需要顺序执行代码且不需要外部事件来驱动的就能完成的事情。在代码清单 1-1 中,如果只是实现 LED 翻转,串口输出,液晶显示等这些操作,那么使用轮询系统将会非常完美。但是,如果加入了按键操作等需要检测外部信号的事件,用来模拟紧急报警,那么整个系统的实时响应能力就不会那么好了。
假设DoSomethingg3 是按键扫描,当外部按键被按下,相当于一个警报,这个时候,需要立马响 应 , 并 做 紧 急 处 理 , 而 这 个 时 候 程 序 刚 好 执 行 到 DoSomethingg1 , 要 命 的 是DoSomethingg1 需要执行的时间比较久,久到按键释放之后都没有执行完毕,那么当执行到 DoSomethingg3 的时候就会丢失掉一次事件。足见,轮询系统只适合顺序执行的功能代码,当有外部事件驱动时,实时性就会降低。
2 前后台系统
相比轮询系统,前后台系统是在轮询系统的基础上加入了中断。外部事件的响应在中断里面完成,事件的处理还是回到轮询系统中完成,中断在这里我们称为前台, main 函数里面的无限循环我们称为后台,大概的伪代码见代码清单所示:
在顺序执行后台程序的时候,如果有中断来临,那么中断会打断后台程序的正常执行流,转而去执行中断服务程序,在中断服务程序里面标记事件,如果事件要处理的事情很简短,则可在中断服务程序里面处理,如果事件要处理的事情比较多,则返回到后台程序里面处理。
虽然事件的响应和处理是分开了,但是事件的处理还是在后台里面顺序执行的,但相比轮询系统,前后台系统确保了事件不会丢失,再加上中断具有可嵌套的功能,这可以大大的提高程序的实时响应能力。在大多数的中小型项目中,前后台系统运用的好,堪称有操作系统的效果。
RTOS多线程
相比前后台系统,多线程系统的事件响应也是在中断中完成的,但是事件的处理是在线程中完成的。在多线程系统中,线程跟中断一样,也具有优先级,优先级高的线程会被优先执行。
当一个紧急的事件在中断被标记之后,如果事件对应的线程的优先级足够高,就会立马得到响应。相比前后台系统,多线程系统的实时性又被提高了。
多线程系统大概的伪代码具体见代码清单所示:
相比前后台系统中后台顺序执行的程序主体,在多线程系统中,根据程序的功能,我们把这个程序主体分割成一个个独立的,无限循环且不能返回的小程序,这个小程序我们称之为线程。
每个线程都是独立的,互不干扰的,且具备自身的优先级,它由操作系统调度管理。加入操作系统后,我们在编程的时候不需要精心地去设计程序的执行流,不用担心每个功能模块之间是否存在干扰。
加入了操作系统,我们的编程反而变得简单了。整个系统随之带来的额外开销就是操作系统占据的那一丁点的 FLASH 和 RAM。现如今,单片机的 FLASH 和 RAM 是越来越大,完全足以抵挡 RTOS 那点开销。
轮询、前后台和多线程系统软件模型区别:

二、AD超全封装库
下面给大家分享3个封装库,基本上常用的封装都能找得到,还带3D模型的!

3个文件加起来共1088个封装!大部分都是带3D模型的。
电阻器的封装(部分)

电容器的封装(部分)

接线端子、电源插座的封装(部分)
常用IC的封装(部分)

常用晶振的封装(部分)
其它封装(部分)

三、更接近底层的汇编与C语言
高级语言与低级语言
学习编程其实就是学习与计算机交流的语言。因为计算机不理解人类语言,通过编译器把人类写的代码转成二进制代码,才能在机器上运行。掌握了高级语言,并不等于理解计算机实际的运行步骤,还需要对C语言甚至是汇编有所了解才行。编程语言从低级到高级,如下图所示。其中,Assembly Language也就是我们说的汇编,在机器语言Machine Language与高级语言之间。
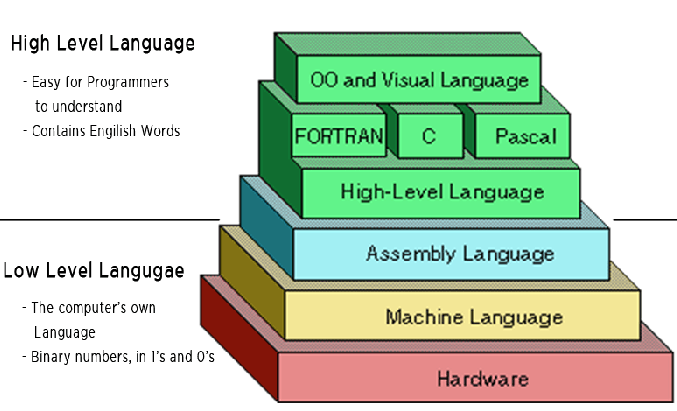
然而,计算机只能理解低级语言,它专门用来控制硬件。
汇编语言就是一种低级语言,直接描述或者控制CPU的运行。通过学习汇编语言,可以了解CPU到底干了些什么
汇编语言不容易学习,大多数的嵌入式开发用C语言就能做得很好。用C语言开发效率更高,程序运行效率并不会大打折扣。为什么还要学习汇编呢?权当是为了更接近真相吧!
汇编语言怎么来的
作为智能设备核心的CPU只负责计算,本身不具备智能,只会按照指令要求去执行相应动作。
这些指令都是二进制的,称为操作码(opcode),比如加法指令就是00000011。编译器的作用,就是将高级语言写好的程序,翻译成一条条操作码。
最早的时候,编写程序就是手写二进制指令,程序就是一串0或1。据说在上世纪,世界上只有为数不多的天才可以做到。写完一连串01程序之后,通过各种开关输入计算机,比如要做加法了,就按一下加法开关,后来发明了纸带打孔机,通过在纸带上打孔,将二进制指令自动输入计算机。如下图,就可能是一段计算机指令。
但是,这种反人类的二进制程序难以理解,可读性极差,换人来维护基本上等于从头再来!根本看不出来机器干了什么。为了解决可读性的问题,以及偶尔的编辑需求,汇编语言应运而生。
早期,为了解决二进制指令的可读性问题,工程师曾经将那些二进制指令写成了八进制,但是八进制的可读性也不行。很自然地,最后还是用文字表达。汇编语言是二进制指令的文本形式,与指令是一一对应的关系。比如,加法指令00000011写成汇编语言就是 ADD。内存地址也不再直接引用,而是用标签表示。
把这些文字指令翻译成二进制,这个步骤就称为汇编assembling,完成这个步骤的程序就叫做汇编器assembler。它处理的文本,标准化以后称为汇编语言Assembly Language,缩写为asm,文件名后缀为s。
寄存器与内存模型
寄存器
每一种CPU 的机器指令都是不一样的,因此对应的汇编语言也不一样。本文介绍的是最常见的Intel 公司CPU使用的那种x86汇编语言。
学习汇编语言要熟悉两个知识点:寄存器和内存模型。先来说一下寄存器。
CPU本身只负责运算,不负责储存数据。数据一般都储存在内存之中,CPU要用的时候就去内存读写数据。但是,CPU的运算速度远高于内存的读写速度,为了避免被拖慢,CPU都自带一级缓存和二级缓存。基本上,CPU缓存可以看作是读写速度较快的内存。
由于CPU缓存还是不够快,另外数据在缓存里面的地址是不固定的,CPU每次读写都要寻址也会拖慢速度。因此,除了缓存之外,CPU还自带了寄存器(register),用来储存最常用的数据。也就是说,像循环变量那种最频繁读写的数据都会放在寄存器里面,CPU优先读写寄存器,再由寄存器跟内存交换数据。如下图,按速度排序,从上到下依次降低。
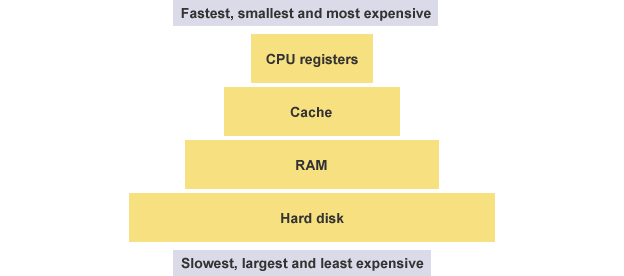
寄存器不依靠地址区分数据,而依靠名称。每一个寄存器都有自己的名称,我们告诉CPU去具体的哪一个寄存器拿数据,这样的速度是最快的。有人比喻寄存器是CPU的零级缓存。
早期的x86CPU只有8个寄存器,而且每个都有不同的用途。现在的寄存器已经有100多个了,都变成通用寄存器,不特别指定用途了,但是早期寄存器的名字都被保存了下来。
上面这8个寄存器之中,前面七个都是通用的。ESP 寄存器有特定用途,保存当前 Stack 的地址。
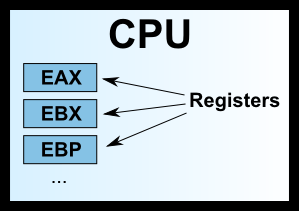
常常看到的32位 CPU、64位 CPU 这样的名称,其实指的就是寄存器的大小。32 位 CPU 的寄存器大小就是4个字节。
内存模型:Heap
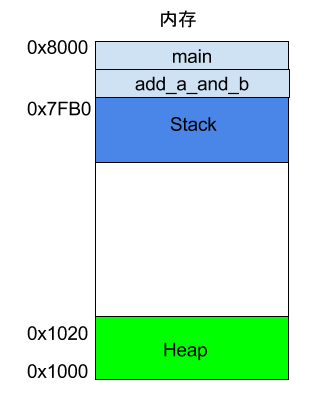
寄存器只能存放很少量的数据,大多数时候,CPU 要指挥寄存器,直接跟内存交换数据。所以,除了寄存器,还必须了解内存怎么储存数据。程序运行的时候,操作系统会给它分配一段内存,用来储存程序和运行产生的数据。这段内存有起始地址和结束地址,比如从0x1000到0x8000,起始地址是较小的那个地址,结束地址是较大的那个地址。

程序运行过程中,对于动态的内存占用请求(比如新建对象,或者使用malloc命令),系统就会从预先分配好的那段内存之中,划出一部分给用户,具体规则是从起始地址开始划分(实际上,起始地址会有一段静态数据,这里忽略)。举例来说,用户要求得到10个字节内存,那么从起始地址0x1000开始给他分配,一直分配到地址0x100A,如果再要求得到22个字节,那么就分配到0x1020。

这种因为用户主动请求而划分出来的内存区域,叫做 Heap(堆)。它由起始地址开始,从低位(地址)向高位(地址)增长。Heap 的一个重要特点就是不会自动消失,必须手动释放,或者由垃圾回收机制来回收。
内存模型:Stack
除了 Heap 以外,其他的内存占用叫做 Stack(栈)。简单说,Stack 是由于函数运行而临时占用的内存区域。
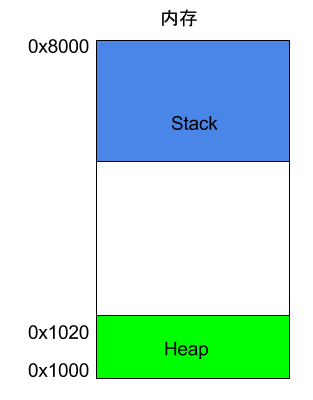
请看下面的例子。
上面代码中,系统开始执行main函数时,会为它在内存里面建立一个帧(frame),所有main的内部变量(比如a和b)都保存在这个帧里面。main函数执行结束后,该帧就会被回收,释放所有的内部变量,不再占用空间。
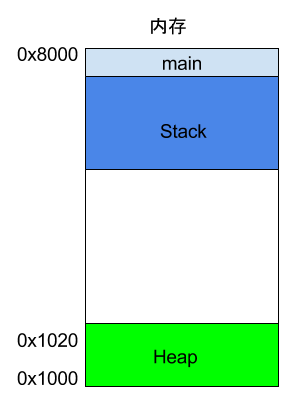
如果函数内部调用了其他函数,会发生什么情况?
上面代码中,main函数内部调用了add_a_and_b函数。执行到这一行的时候,系统也会为add_a_and_b新建一个帧,用来储存它的内部变量。也就是说,此时同时存在两个帧:main和add_a_and_b。一般来说,调用栈有多少层,就有多少帧。
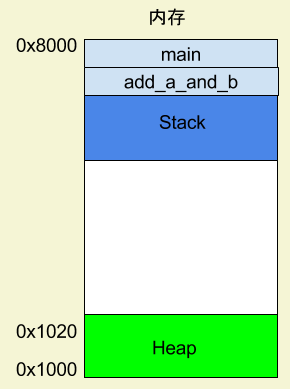
等到add_a_and_b运行结束,它的帧就会被回收,系统会回到函数main刚才中断执行的地方,继续往下执行。通过这种机制,就实现了函数的层层调用,并且每一层都能使用自己的本地变量。所有的帧都存放在 Stack,由于帧是一层层叠加的,所以 Stack 叫做栈。生成新的帧,叫做"入栈",英文是 push;栈的回收叫做"出栈",英文是 pop。Stack 的特点就是,最晚入栈的帧最早出栈(因为最内层的函数调用,最先结束运行),这就叫做"后进先出"的数据结构。每一次函数执行结束,就自动释放一个帧,所有函数执行结束,整个 Stack 就都释放了。
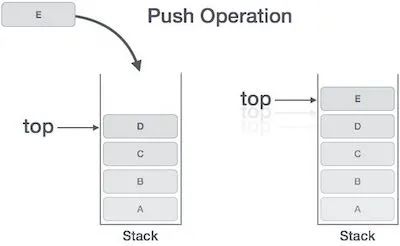
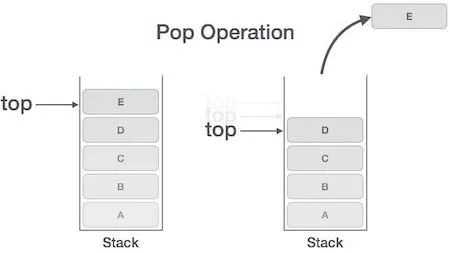
Stack 是由内存区域的结束地址开始,从高位(地址)向低位(地址)分配。比如,内存区域的结束地址是0x8000,第一帧假定是16字节,那么下一次分配的地址就会从0x7FF0开始;第二帧假定需要64字节,那么地址就会移动到0x7FB0。
CPU 指令
一个实例
了解寄存器和内存模型以后,就可以来看汇编语言到底是什么了。下面是一个简单的程序example.c。
gcc 将这个程序转成汇编语言。
上面的命令执行以后,会生成一个文本文件example.s,里面就是汇编语言,包含了几十行指令。这么说吧,一个高级语言的简单操作,底层可能由几个,甚至几十个 CPU 指令构成。CPU 依次执行这些指令,完成这一步操作。
example.s经过简化以后,大概是下面的样子。
可以看到,原程序的两个函数add_a_and_b和main,对应两个标签_add_a_and_b和_main。每个标签里面是该函数所转成的 CPU 运行流程。
每一行就是 CPU 执行的一次操作。它又分成两部分,就以其中一行为例。
这一行里面,push是 CPU 指令,%ebx是该指令要用到的运算子。一个 CPU 指令可以有零个到多个运算子。下面我就一行一行讲解这个汇编程序,建议读者最好把这个程序,在另一个窗口拷贝一份,省得阅读的时候再把页面滚动上来。
push指令
程序从_main标签开始执行,这时会在 Stack 上为main建立一个帧,并将 Stack 所指向的地址,写入 ESP 寄存器。后面如果有数据要写入main这个帧,就会写在 ESP 寄存器所保存的地址。然后,开始执行第一行代码。
push指令用于将运算子放入 Stack,这里就是将3写入main这个帧。
虽然看上去很简单,push指令其实有一个前置操作。它会先取出 ESP 寄存器里面的地址,将其减去4个字节,然后将新地址写入 ESP 寄存器。使用减法是因为 Stack 从高位向低位发展,4个字节则是因为3的类型是int,占用4个字节。得到新地址以后, 3 就会写入这个地址开始的四个字节。
第二行也是一样,push指令将2写入main这个帧,位置紧贴着前面写入的3。这时,ESP 寄存器会再减去 4个字节(累计减去8)。

call指令
第三行的call指令用来调用函数。
上面的代码表示调用add_a_and_b函数。这时,程序就会去找_add_a_and_b标签,并为该函数建立一个新的帧。下面就开始执行_add_a_and_b的代码。
这一行表示将 EBX 寄存器里面的值,写入_add_a_and_b这个帧。这是因为后面要用到这个寄存器,就先把里面的值取出来,用完后再写回去。这时,push指令会再将 ESP 寄存器里面的地址减去4个字节(累计减去12)。
mov指令
mov指令用于将一个值写入某个寄存器。
这一行代码表示,先将 ESP 寄存器里面的地址加上8个字节,得到一个新的地址,然后按照这个地址在 Stack 取出数据。根据前面的步骤,可以推算出这里取出的是2,再将2写入 EAX 寄存器。下一行代码也是干同样的事情。
上面的代码将 ESP 寄存器的值加12个字节,再按照这个地址在 Stack 取出数据,这次取出的是3,将其写入 EBX 寄存器。
add指令
add指令用于将两个运算子相加,并将结果写入第一个运算子。
上面的代码将 EAX 寄存器的值(即2)加上 EBX 寄存器的值(即3),得到结果5,再将这个结果写入第一个运算子 EAX 寄存器。
pop指令
pop指令用于取出 Stack 最近一个写入的值(即最低位地址的值),并将这个值写入运算子指定的位置。
上面的代码表示,取出 Stack 最近写入的值(即 EBX 寄存器的原始值),再将这个值写回 EBX 寄存器(因为加法已经做完了,EBX 寄存器用不到了)。
注意,pop指令还会将 ESP 寄存器里面的地址加4,即回收4个字节。
ret指令
ret指令用于终止当前函数的执行,将运行权交还给上层函数。也就是,当前函数的帧将被回收。如下,可以看到,该指令没有运算子。
随着add_a_and_b函数终止执行,系统就回到刚才main函数中断的地方,继续往下执行。
上面的代码表示,将 ESP 寄存器里面的地址,手动加上8个字节,再写回 ESP 寄存器。这是因为 ESP 寄存器的是 Stack 的写入开始地址,前面的pop操作已经回收了4个字节,这里再回收8个字节,等于全部回收。
最后,main函数运行结束,执行ret指令退出程序的执行。















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









