





前面提到一种新的调优方法,通过写tuned profile 方案,调优参数随服务启动生效,按照启动顺序是先读取 /etc/sysctl.conf 然后再读取tuned.conf ,所以后者会覆盖前者,/etc/sysctl.conf 相当于是全局调优方案。
硬件监控及内核模块调优
四大核心子系统:
- CPU
- 内存
- 磁盘
- 网络
从cpu 开始,来看这台机器:
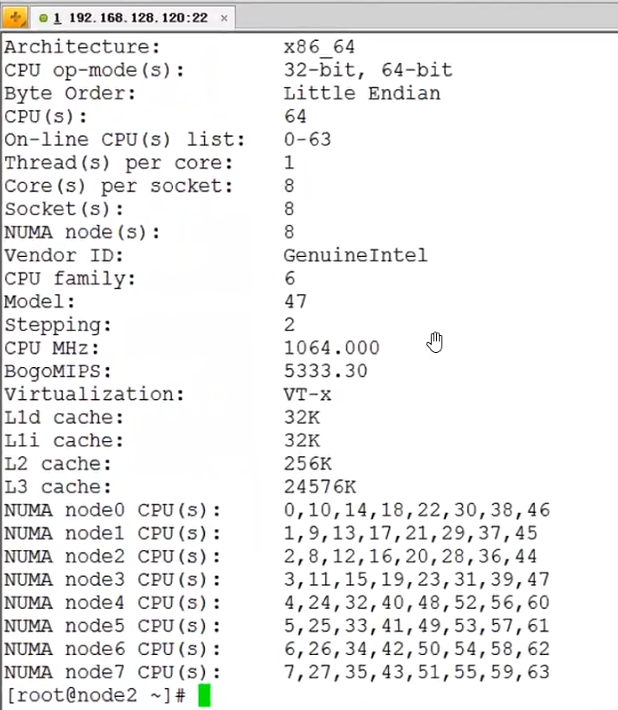
cpu的架构是x86_64,数量64,编号是从0 - 63,每个核有一个线程,一共有8 个插槽,被分成了8 个NUMA node。
接下来解释一下:
这台机器一共是有8 颗物理处理器,每一颗物理处理器有8 个核,每一个核只有一个线程,所以一共是有64 个cpu;
如果一个核是有两个线程,那么一共就有128 个cpu。
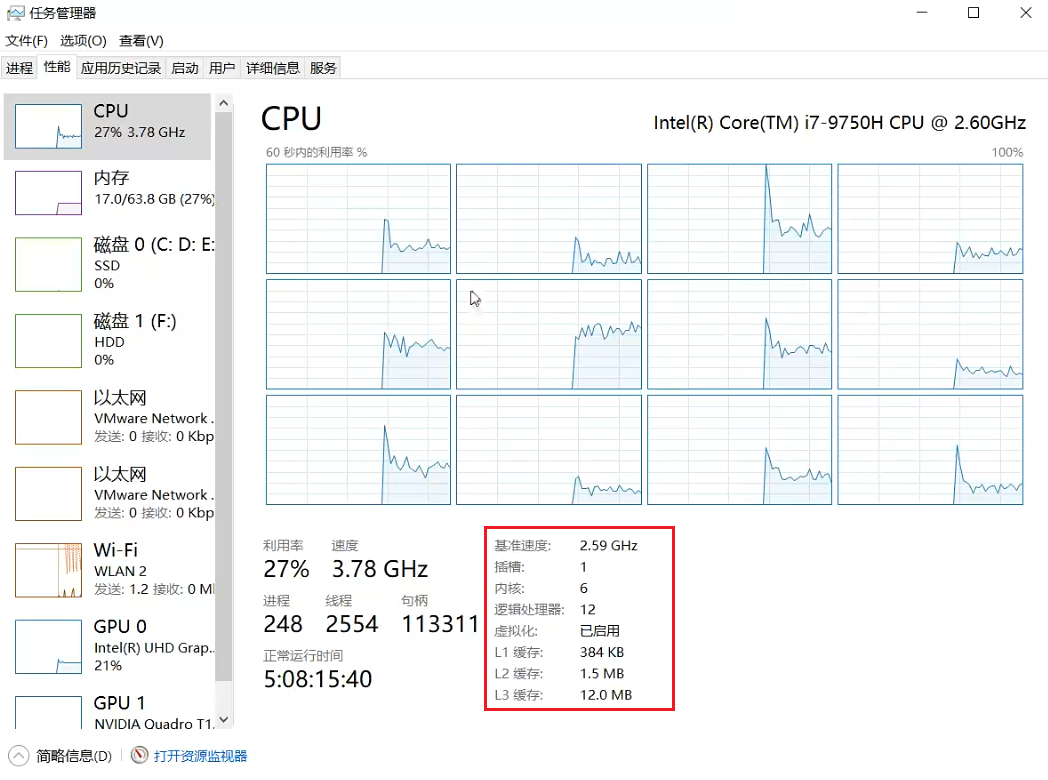
这是一台windows 系统主机,基准速度是这块cpu 的工作频率,1 个插槽,6 核心,每一个核心有两个线程,所以有12 个逻辑处理器,已启用虚拟化技术,下面分别是一级、二级、三级缓存区大小。
问题:
假如一台机器有四块物理处理器,每一块物理处理器有一个核;
一台机器有一块物理处理器,这一块物理处理器就有四个核;
逻辑处理器都是4,那么两者哪个性能更好呢?
到这里,来给大家做一个普及:
很多年前,那时候的电脑的cpu 还是i386...之类的架构,都不用谈有几个处理器,有一个就不错了,可能瓶颈不在处理器上,更多的是磁盘和内存,内存容量很小。后来随着技术的更新迭代,对cpu 的处理能力要求越来越高,一个处理器已经不能满足要求了,就要用到多个处理器,一旦使用多个处理器,那就对整个主板的设计有要求了,原来一个主板上就一个cpu 插槽,现在要两个,现在的物理服务器,一般来说主板有两个物理插槽,甚至只有一个物理插槽。如果为主板设计多个cpu 插槽,这个思路从技术角度来讲没有问题,但是从使用角度来看,主板就会做得很臃肿。为了解决这个问题,就发明了核心的概念,在一块物理cpu 上划分多个核心,相当于一块cpu 上分裂成多个脑袋,这样运算能力也提升上来了。所以核心是真正的物理cpu,只是为了避免主板上的cpu 数量过多,所以才会引出核心的概念。
一个处理器在同一时刻只能处理一个任务,如果要处理多个任务,就要用到队列技术,给每一个请求分配时间片,在队列里面排队。
什么是超线程?一个处理器在当前时刻只能处理一个任务,对如今cpu 的处理能力而言显得有点浪费,所以引出了超线程的概念,一个核心在同一时刻可以处理两个任务。
华为的鲲鹏920 处理器,它可以做到单处理器64 核心;
为什么Intel 发展这么多年,它也许才28 核心 * 2 呢?
是因为华为的鲲鹏处理器用的是精简指令集,而Intel 处理器用的是复杂指令集。
从字面上就知道,精简指令集更加优化,处理一个指令可能只需要一个循环,而复杂指令集可能要两个循环,所以很显然,精简指令集更优秀。
那么Intel 为什么不用精简指令集呢?原则上精简指令集的处理效率比复杂指令集更高,这里面有历史渊源。
其实Intel 在五六十年代就已经拥有了制作复杂指令集cpu 的能力,从8 位的指令集到32 位的指令集再到后面64 位的指令集,由Intel 制作的处理器与微软的操作系统联合,围绕复杂指令集打造了一整个硬件、操作系统及上层应用生态,沿用至今,新的生态很难融入进来。
以美国为首的Intel、AMD 厂商在复杂指令集这个生态之下拥有绝大部分的专利,其他厂商几乎没有办法与之竞争,其他国家也几乎没有办法与之竞争。
其他厂商如果想在x86 平台获得一席之地几乎是不可能的,所以就另辟蹊径,发明了基于精简型指令集的ARM 架构。
虽然ARM 架构的cpu 处理能力很强,但最大的问题在于生态,就像任正非说:生态成,则华为成,生态成,则鸿蒙成。
其实我们现在的安卓手机,绝大部分处理器采用的是高通或联发科的芯片,使用的就是精简指令集,这也是为什么Intel 处理器始终没能出现在手机上的原因,得益于在x86 平台的成功,使得他们持续在此深耕。
有了CPU 为什么又需要GPU 呢?
这也是英伟达成为世界市值第二的公司的原因。因为现如今我们在人工智能领域算力不足,尤其是在处理高并发、重复的海量数据的时候,cpu 的运算能力是不如gpu 的,在绝大部分场景下, cpu 的处理能力也不如gpu。那为什么当年gpu 没有取代cpu 呢?
cpu 处理器是由控制器 + 运算器组成,大约70% 的能力用在控制方面,30% 的能力用在运算方面,大部分的处理能力是用来做控制,为什么这样,因为它不能出错。
gpu 处理器大约90% 是用来运算的,它更关注运算,而非控制,并行运算能力强。
所谓异构计算,指的是以下几种组合:
- CPU + GPU
- CPU + FPGA:可编程芯片
- CPU + ASCI:专用芯片,不可编程,性能好
华为基于第三种组合做了一个昇腾架构。以上了解一下即可...
话题回到lscpu 的查询结果:
来看几个关注点:它支持虚拟化吗?看Virtualization 那行,如果是Intel 处理器,是VT-X,代表支持虚拟化。
还有一级缓存、二级缓存、三级缓存,现在的处理器一般都有三级缓存。
一级缓存又分为数据区和指令区,L1d 的d 就代表数据区,L1i 的i 就代表指令区,如果要问一级缓存有多大?就是64 K,二级缓存是256 K,三级缓存是24 M。
但一级缓存的大小64K 是单核的缓存大小,因为是8 核心,所以是64K * 8 = 512K,一般地,处理的一级缓存都是这样计算;
同样地,二级缓存大小应是256K * 8 = 2M,二级缓存只有数据区,不过有的处理器有大核与小核之分,对应的二级缓存大小也不同,主要是在个人pc 上存在这个区别,在服务器上目前来说一般没有这个问题;
现在的cpu 一般都有三级缓存,一级缓存和二级缓存都是每个核私有的,三级缓存是所有的核心共享的。所以,三级缓存大小应是24M。
来看下图:
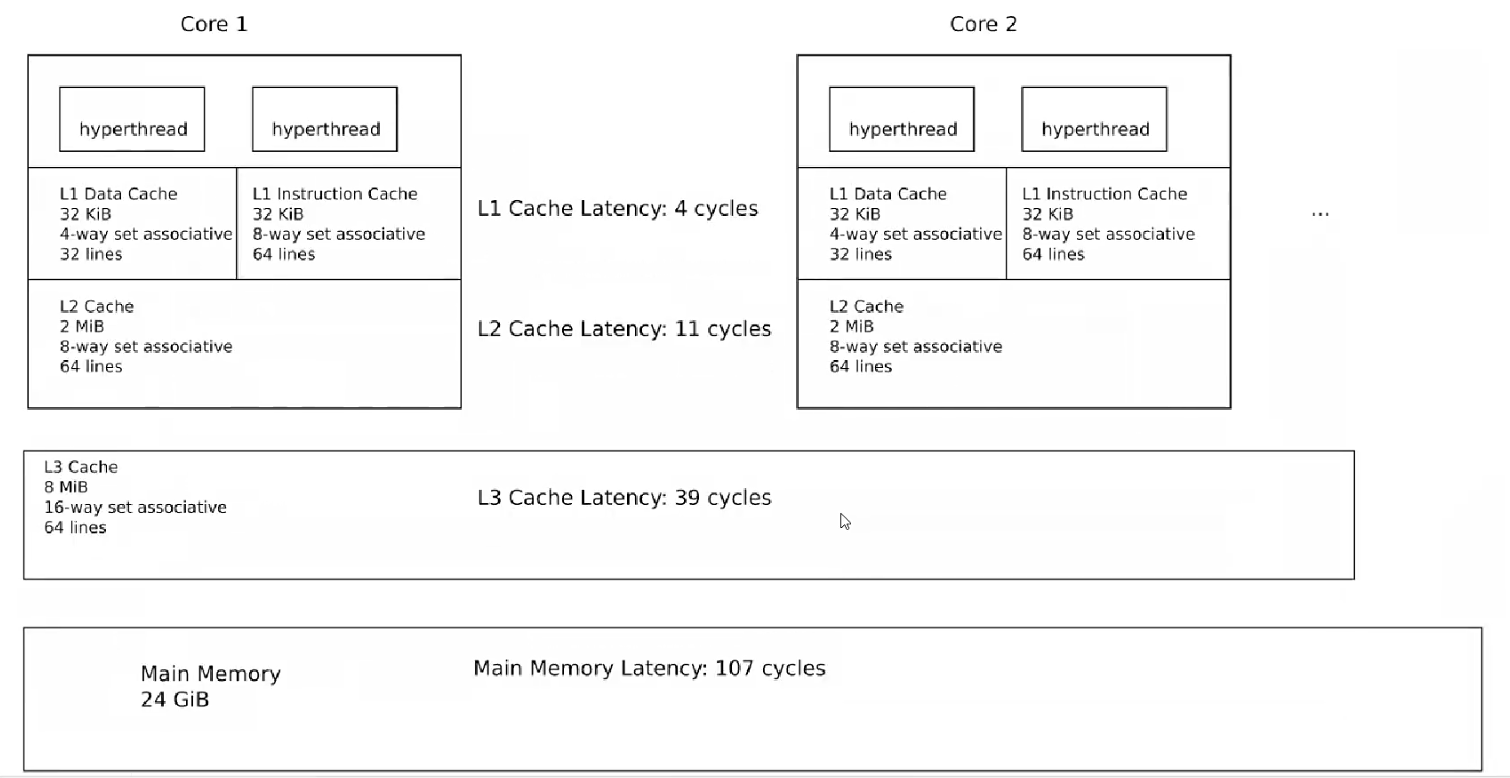
左边一个核,右边一个核,从上到下:L1、L2、L3 缓存、内存。为什么cpu 需要有L2、L3 缓存,而不是全部放在里面呢?缓存能提升读性能,cpu 在处理数据的时候,首先看L1 缓存中有没有,如果有,就在L1 缓存中命中了,它是速度最快的,因为在cpu 内部,路径最短,但L1 缓存不会很大;如果L1 缓存中没有,就看L2 缓存,如果有就命中,没有就看L3 缓存,如果有命中,没有则找主存。这里L1 缓存是处理4 个周期,L2 是11 个周期,L3 是39 个周期,主存(也即内存)是107 个周期。这张图也在说明一个事情,一级缓存处理速度是最快的,其次是二级缓存、三级缓存、主存,它们的速度之比:一级缓存相比于主存,它可能要快20 倍,如果你要问,cpu 缓存比内存快多少倍?那么上面这张图大概能说明问题。

执行这条命令,通过上图显示的结果,可以看到,一共七个字段。这个cpu 只有L2 缓存,没有L3 缓存,这是在比较老的cpu 上才能看到,现在很少了。如果cpu 只有L2 缓存,那么,L1 缓存是私有的,L2 是共享的:
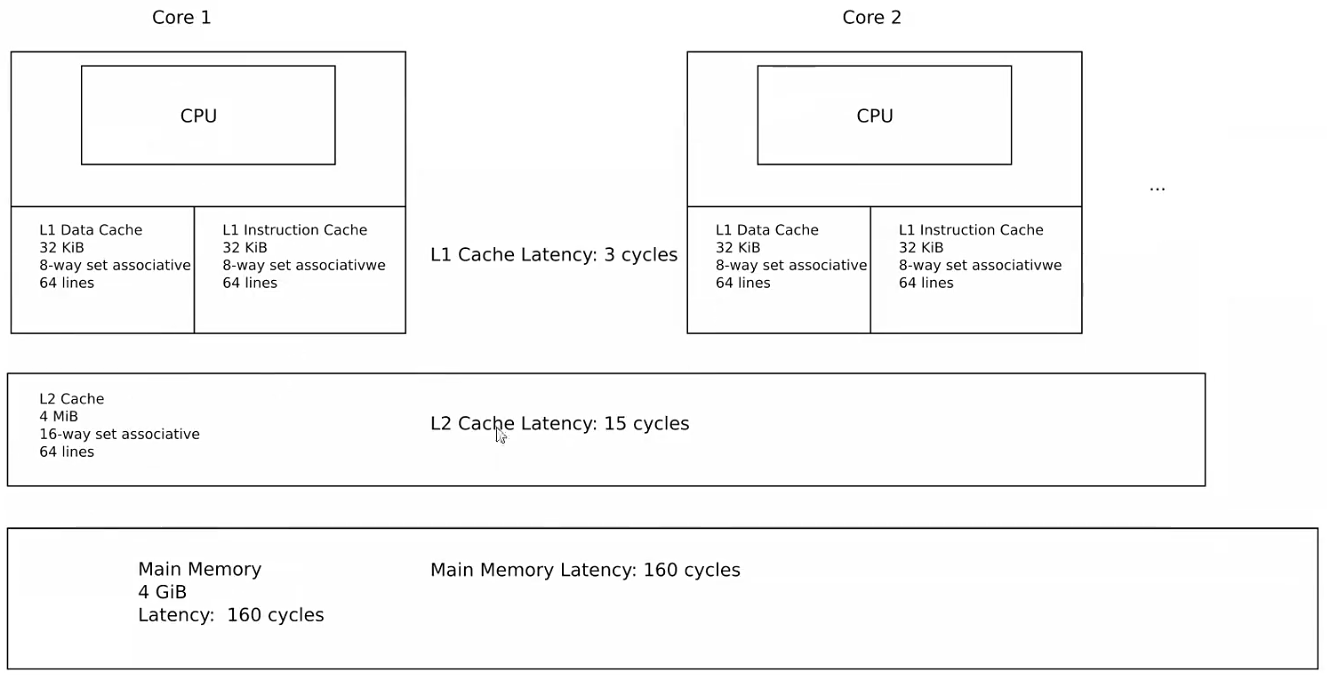
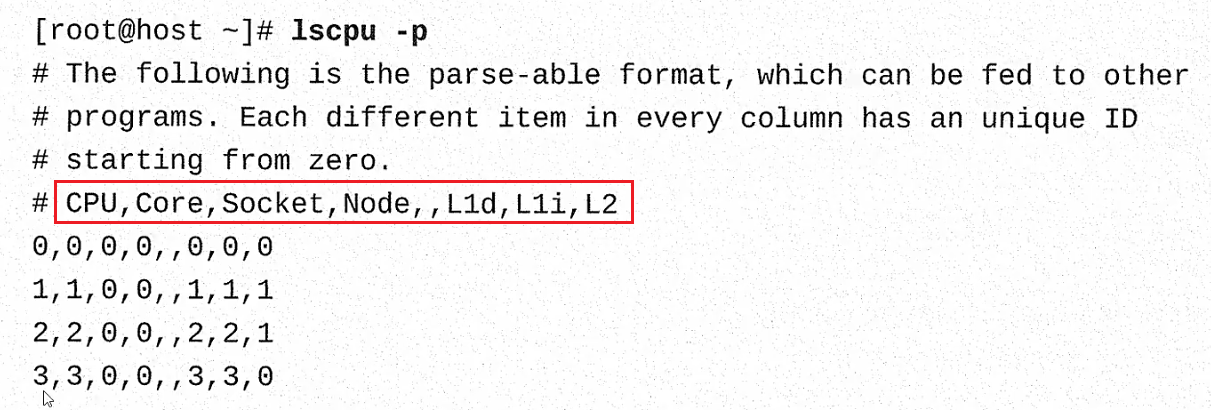
上图红色标记的七个字段,分别与下面的七列数字相对应。第一列是cpu 编号,第二列是核心,一个cpu 编号对应一个核心,说明没有超线程(也叫多线程),第三列插槽编号全部是0,说明只用了一个cpu 插槽,第四列全部是0,说明只有一个NUMA Node,第五列L1d 是一级缓存的数据区,从0 - 3,说明一级缓存是私有的,L1i 是一级缓存的索引区,从0 - 3,同样说明了一级缓存是私有的, L2 二级缓存是0,1,1,0,说明每两个cpu 核心共用一个L2 缓存。
下面这张图的执行结果,可以对比来看:
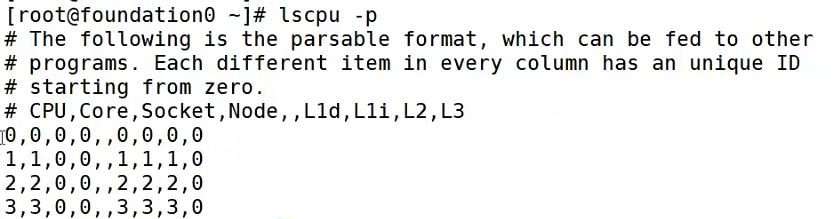
另外在红帽rhca 考试中,有一道题是需要对机器的cpu L1、L2 缓存进行分析,它不是用lscpu 命令来查看的,有另外一个命令:
这条命令很强大,可以获取系统上所有的硬件信息,比如:硬件厂商、产品序列号、工作电压等等...
下图是一个dmidecode 查询示例,搜索关键词找到“L1”,编号为“0x0094”:

继续搜索关键词“0x0094”,就可以看到L1 缓存大小为16 kB了:
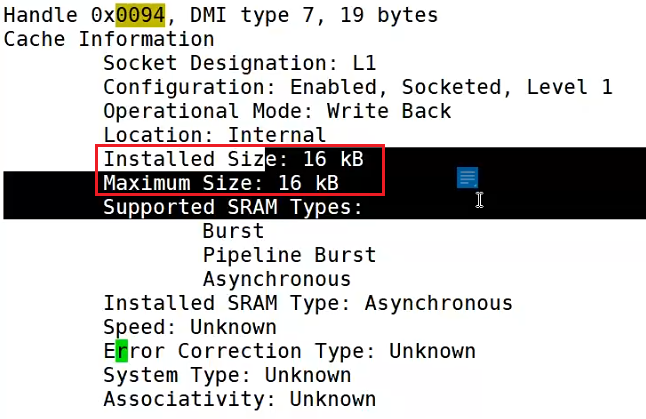
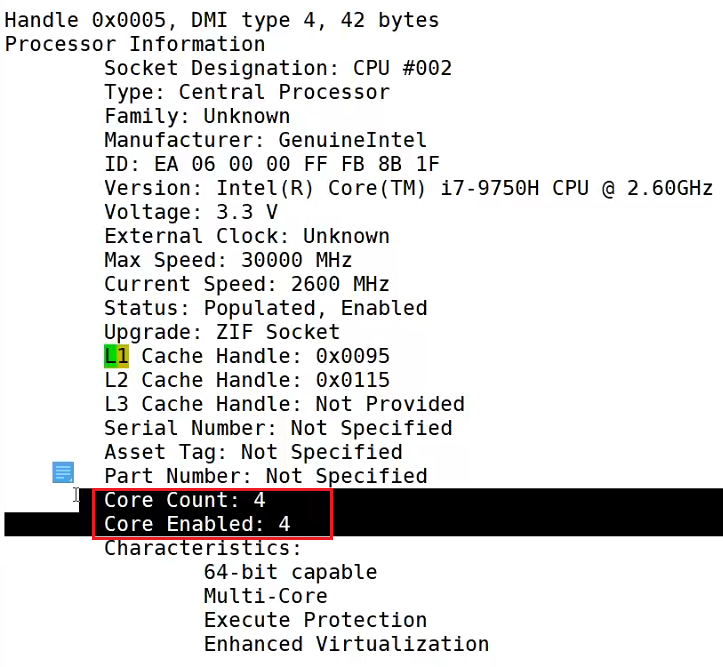
不过,这是一台虚拟机,这个缓存大小可能不是真实的缓存大小,在实际工作中,一台物理服务器上,16 kB就显得太小了, 如果这里显示的是512 kB,而cpu 是四核八线程的,那么单核的缓存大小应是512/4 = 64 kB 这样来计算,核心数量看这里:
UMA:一致性内存访问
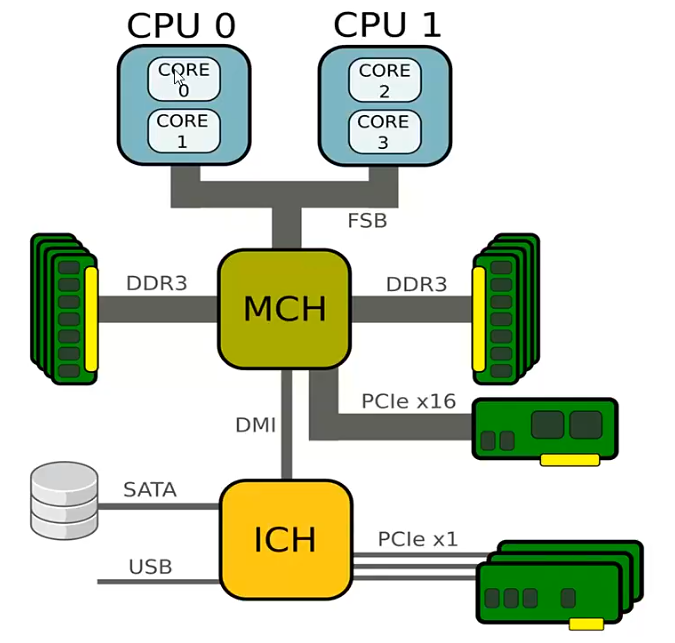
cpu 什么时候需要访问内存?当它要调用的数据不在cpu 缓存区的时候,通过FSB(前端总线)与内存交互。当一块主板上有多块cpu,很多条内存,cpu 与内存交换数据的时候,FSB 也许会成为性能瓶颈,如今一台机器的cpu 动辄几十核,内存几百GB,如果还采用上图这个架构,那么势必产生数据交换性能瓶颈。为了解决这个问题,现在不再采用UMA 这种架构,而是更流行的NUMA(非一致性内存访问)架构:
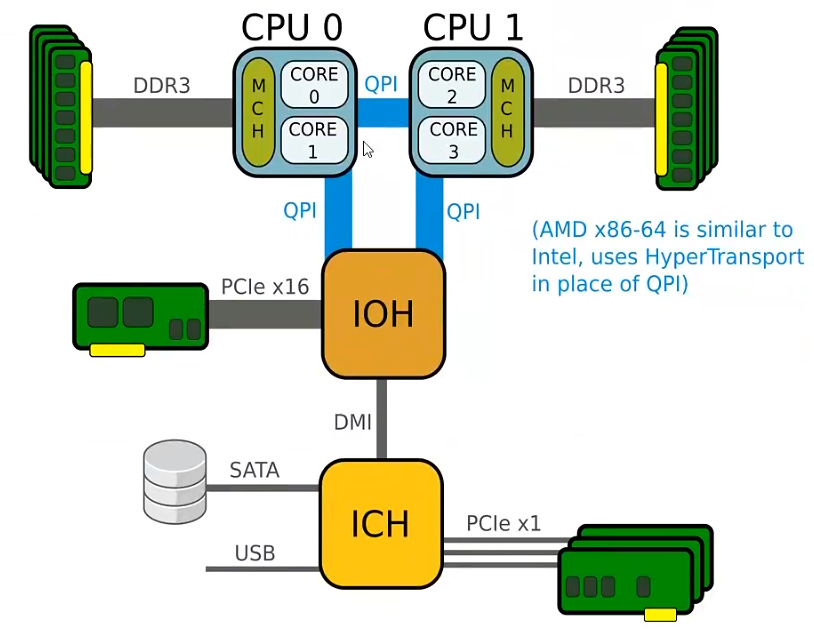
它将某一些cpu 与某一些内存绑定在一个区域里面,交换数据的时候尽可能在本区域内进行交换,如果本区域没有所需要的数据,可以通过QPI 这个快速通道连接到其它的区域调取所需要的数据。
NUMA 架构是由硬件本身决定的,与操作系统无关,如今一般的pc 和笔记本不支持这种架构,在服务器领域一般支持。
如果你经常接触服务器硬件,很有可能遇到过一个问题,在双路主板上只插了一块cpu,某些内存就识别不到了,然后尝试将这些识别不到的内存更换插槽就可以,这是因为每一块cpu 固定管辖其中固定一些编号的内存插槽。
再次回来看lscpu 命令的回显:

一共是8 个NUMA node,每一个node 里面有8 个cpu
这台机器的内存是1TB,单条内存16GB,插了64条内存,cpu 有64 核

所以默认情况下,将8 条内存和8 个核放置在一个node 里面。
华为的虚拟化平台Fusion Compute 里面有一个功能,叫做NUMA 自适应,如果勾选这个功能就表示:当运行一个虚拟机时,如果选择了4 个cpu,8G 内存,虚拟化平台会自动将该虚拟机运行在一个numa node 中,提升运行效率。
四大核心子系统 — 磁盘
如果从性能方面考虑,一定是选购SSD 硬盘更好,但相比于机械硬盘,它价格昂贵,容量较小。如今SSD 硬盘也有分类:
- SATA SSD
- SAS SSD
- NVME SSD
SATA、SAS、NVME 这是不同的硬盘接口,也是不同的协议。如果有条件,尽可能地采用SSD 硬盘,如果是做数据备份,只是存放一些冷数据,用更为廉价、大容量的机械硬盘就比较合适了。
还需要考虑磁盘阵列,常见的有:
- RAID 0
- RAID 1
- RAID 10
- RAID 5
- RAID 6
好一点的磁盘阵列卡可能还支持RAID 50 和 RAID 60
生产环境一般使用RAID 5、RAID 10 更多。
如果服务器只是用来安装OS,则一般使用RAID 1,在存储设备上配置RAID
应该根据业务类型创建不同级别的RAID
如果用4 块硬盘组成RAID 5,用D 表示数据位,用P 表示校验位,它的校验位可能像下面这样分布式存放:

处于同一水平线上的我们称之为是一个条带:

条带的大小是在创建磁盘阵列的时候决定的,比如可以设为64KB、128KB...
用更专业的术语来讲,叫“chunk size”。
如果业务属于顺序IO,例如视频监控、备份,那么RAID 5 的写性能较高;如果业务属于随机IO,例如数据库、OLTP,当需要修改一个数据位的时候,同时需要把这一个条带里的其他数据位和校验位全部读出来修改以后经过奇偶校验再写回去,这就是我们经常说的写惩罚:一次写操作带来了额外的读操作,此时磁盘的IO 性能特别差。
如果是4 块硬盘组成RAID 10,先把2 块盘组成 RAID 1、2块盘组成RAID 1,再把这两个RAID 1 组成RAID 0,也就组成了RAID 10,那么在写数据的时候数据位大概是这么分布的:
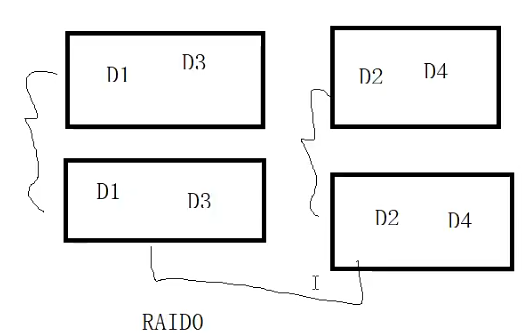
数据位完全等同复制,修改数据的时候不会带来额外的读操作,不用计算奇偶校验位,所以RAID 10 更适合于随机IO 的业务场景。
四大核心子系统 — 网络

四大核心子系统 — 内存
从硬件方面来讲,内存可供选择优化的余地不多,考虑的因素主要有:带宽、容量、工作频率。
再来学习一个命令:
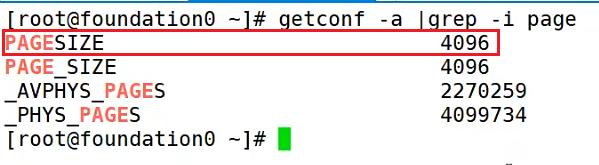
看PAGESIZE 这一行,它的大小是4KB,叫内存页大小,简称页大小。
在存储中有block size的概念,它是文件系统最小存储单元,一个文件至少占用一个block size 的磁盘空间。
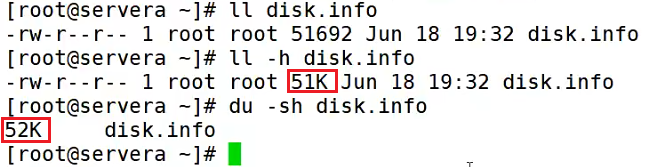
以上,ls 命令查看的是文件的实际大小,du 命令查看的是文件占用磁盘空间的大小,文件系统的block size 是4K,那么就是4K * 13 = 52 KB,也就是说这个文件占用了13 个block size。
一个文件至少占用一个block size,同样地,一个程序在运行的时候,它占用的内存至少是一个page size。在 x86 架构的服务器上,不论是安装什么操作系统,内存页大小都是4KB
使用pmap 命令查看一个进程:
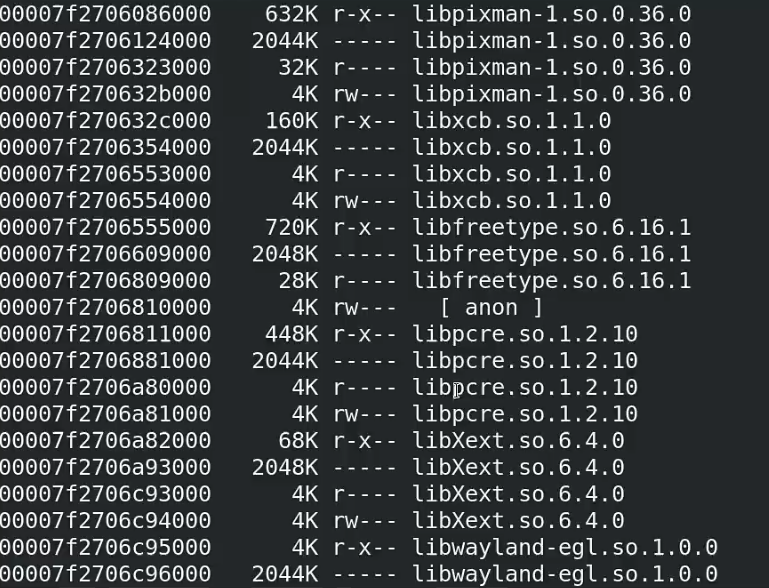
你会发现,这个程序调用的每个模块占用的内存空间都是4K 的倍数。
在ARM 架构的平台上,例如搭载了鲲鹏处理器的TS 2280,它的内存页大小是64K
接下来,来看最后一个监控项 —— dmesg buffer
在RHEL 7 及以前的系统中,有一个文件:
但从RHEL 8 开始,这个文件没有了,但是没有关系,这不妨碍我们使用dmesg 这个命令。
在红帽教室环境中,登录到servera,重启系统:
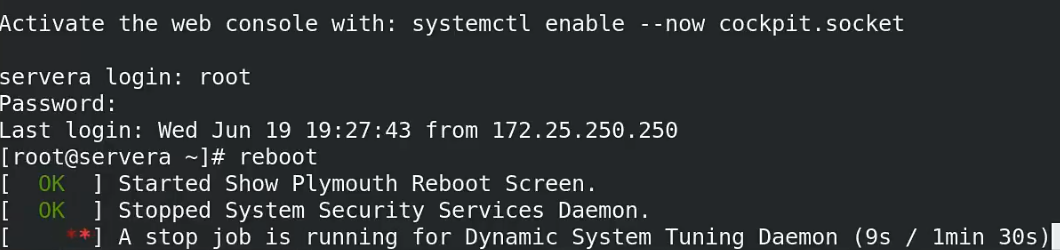
因为是从console 登录的,所以可以看到系统重启的过程,但是有个服务正在运行不能正常停止导致重启过程卡住了,来手动强制停止:
这样,重新开启servera,进入系统开机过程,由于开机的信息在屏幕上几乎都是一闪而过的,dmesg buffer 会把这一次的开机过程完整记录下来,系统开机以后可以使用dmesg 命令来查看,因为是buffer,在缓存区,是非持久性存储,仅会记录这一次的开机过程。
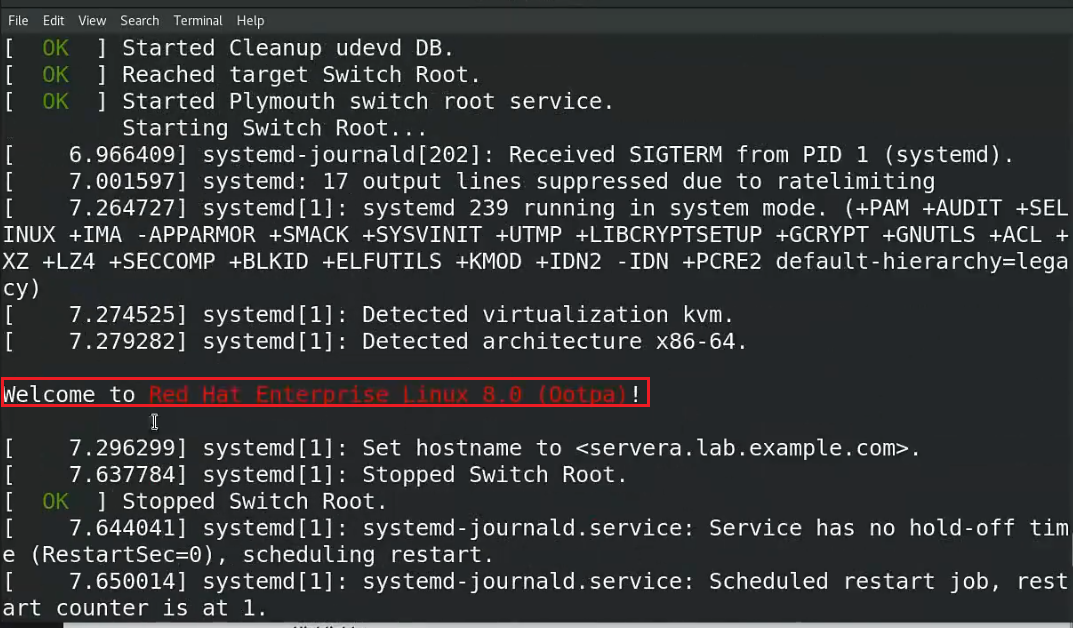
在出现红色标记这一行内容之前,按照系统启动流程,是加载内核、加载initramfs 文件、加载驱动的过程。
像我们经常查看的日志文件 /var/log/message 的内容每一行前面是有时间戳的,而dmesg 命令查看的开机过程,是没有时间戳的:
前面绿色字体的数字显示的是这每一步骤完成所消耗的时间。
如果我想知道这台机器在开机的时候是否有将网卡正常驱动:

从上面的回显信息中可以看到,系统有读取到eth0 这块网卡,它的驱动是vmxnet3,链路状态是UP,速率是万兆;并且它原本的名称叫eth0,将它重命名为了ens160
如果我的机器有两块网卡,但是进入系统后却只看到一块,那我想知道到底是驱动的问题,还是系统网卡配置的问题,怎么解?
如果用dmesg 命令可以看到两块网卡,而用ifconfig 或 ip addr 这样的命令没有看到,说明内核已经驱动了网卡,很有可能是其中一块网卡的配置文件没有生成,尤其在系统安装完成以后,再给机器添加一块网卡的场景中经常出现。
所以在遇到硬件类的问题的时候,可以用dmesg 帮助排错。
在RHEL 系统中,还有一条命令需要了解:
国外的企业通常与国内不同,在国内,如果你买了一个厂商的服务,碰到了搞不定的问题,他们甚至会安排专门的技术人员远程连接到你的电脑上来解决;而在红帽这样的公司是不可以的,只能通过邮件或电话提供技术支持,这其实也是基于安全考虑的,避免在技术支持的过程中业务出问题而要担负法律责任。
sosreport 命令执行时它会收集系统所有的信息,等待执行完成以后,在 /var/tmp 目录中会生成一个类似于这样的文件:

将这个文件发送给红帽公司,对方可以通过它查看到有关这个系统所有的信息。
持续更新中...















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









