






前言
相信大部分开发人员,或多或少都看过或写过并发编程的代码。并发关键字除了Synchronized,还有另一大分支Atomic。如果大家没听过没用过先看基础篇,如果听过用过,请滑至底部看进阶篇,深入源码分析。
提出问题:int线程安全吗?
看过Synchronized相关文章的小伙伴应该知道其是不安全的,再次用代码应验下其不安全性:
public classtestInt {static int number = 0;public static void main(String[] args) throwsException {
Runnable runnable= newRunnable() {
@Overridepublic voidrun() {for (int i = 0; i < 100000; i++) {
number= number+1;
}
}
};
Thread t1= newThread(runnable);
t1.start();
Thread t2= newThread(runnable);
t2.start();
t1.join();
t2.join();
System.out.println("number:" +number);
}
}

运行结果:
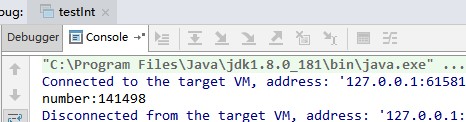
在上面的例子中,我们定义一个初始值为0的静态变量number,再新建并运行两个线程让其各执行10万次的自增操作,如果他是线程安全的,应该两个线程执行后结果为20万,但是我们发现最终的结果是小于20万的,即说明他是不安全的。
在之前Synchronized那篇文章中说过,可以在number=number+1这句代码上下加Synchronized关键字实现线程安全。但是其对资源的开销较大,所以我们今天再看下另外一种实现线程安全的方法Atomic。
Atomic基础篇分界线
原子整数(基础类型)
整体介绍
Atomic是jdk提供的一系列包的总称,这个大家族包括原子整数(AtomicInteger,AtomicLong,AtomicBoolean),原子引用(AtomicReference,AtomicStampedReference,AtomicMarkableReference),原子数组(AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray),更新器(AtomicIntegerFieldUpdater,AtomicLongFieldUpdater,AtomicReferenceFieldUpdater)。
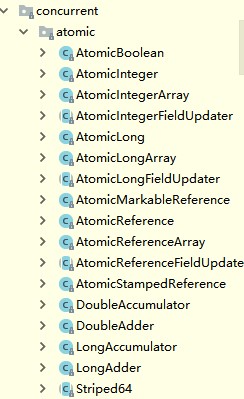
AtomicInteger
AtomicInteger,AtomicBoolean,AtomicLong三者功能类似,咱就以AtomicInteger为主分析原子类。
先看下有哪些API,及其他们具体啥功能:
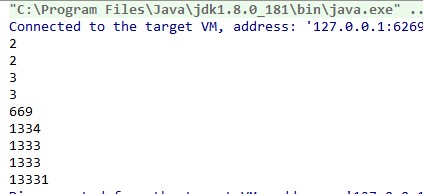
public classtestInt {public static voidmain(String[] args) {//定义AtomicInteger类型的变量,值为1
AtomicInteger i = new AtomicInteger(1);//incrementAndGet方法先新增1再返回,所以打印2,此时i为2
System.out.println(i.incrementAndGet());//getAndIncrement方法先返回值再新增1,所以打印2,此时i为3
System.out.println(i.getAndIncrement());//get方法返回当前i值,所以打印3,此时i为3
System.out.println(i.get());//参数为正数即新增,getAndAdd方法先返回值再新增666,所以打印3,此时i为669
System.out.println(i.getAndAdd(666));//参数为负数即减去,getAndAdd方法先返回值再减去1,所以打印669,此时i为668
System.out.println(i.getAndAdd(-1));//参数为正数即新增,addAndGet方法先新增666再返回值,所以打印1334,此时i为1334
System.out.println(i.addAndGet(666));//参数为负数即减去,addAndGet方法先减去-1再返回值,所以打印1333,此时i为1333
System.out.println(i.addAndGet(-1));//getAndUpdate方法IntUnaryOperator参数是一个箭头函数,后面可以写任何操作,所以打印1333,此时i为13331
System.out.println(i.getAndUpdate(x -> (x * 10 + 1)));//最终打印i为13331
System.out.println(i.get());
}
}
执行结果:
对上述int类型的例子改进
public classtestInt {//1.定义初始值为0的AtomicInteger类型变量number
static AtomicInteger number = new AtomicInteger(0);public static void main(String[] args) throwsException {
Runnable runnable= newRunnable() {
@Overridepublic voidrun() {for (int i = 0; i < 100000; i++) {//2.调用incrementAndGet方法,实现加1操作
number.incrementAndGet();
}
}
};
Thread t1= newThread(runnable);
t1.start();
Thread t2= newThread(runnable);
t2.start();
t1.join();
t2.join();
System.out.println("number:" +number.get());
}
}
我们可以看到运行结果是正确的20万,说明AtomicInteger的确保证了线程安全性,即在多线程的过程中,运行结果还是正确的。但是这存在一个ABA问题,下面将原子引用的时候再说,先立个flag。

源码分析
我们以incrementAndGet方法为例,看下底层是如何实现的,AtomicInteger类中的incrementAndGet方法调用了Unsafe类的getAndAddInt方法。
public final intincrementAndGet() {return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
我们看下getAndAddInt方法,里面有个循环,直接值为compareAndSwapInt返回值为true,才结束循环。这里就不得不提CAS,这就是多线程安全性问题的解决方法。
public final int getAndAddInt(Object var1, long var2, intvar4) {intvar5;do{
var5= this.getIntVolatile(var1, var2);
}while(!this.compareAndSwapInt(var1, var2, var5, var5 +var4));returnvar5;
}
CAS
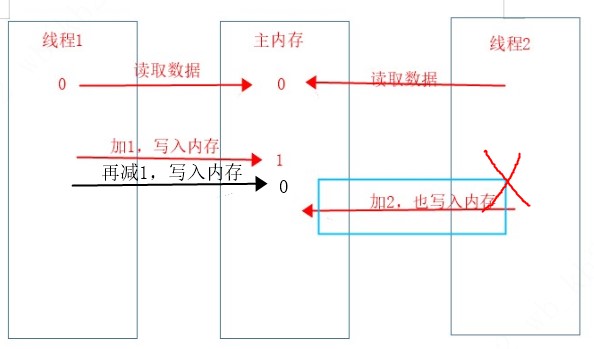
线程1和线程2同事获取了主内存变量值0,线程1加1并写入主内存,现在主内存变量值1,线程2也加2并尝试写入主内存,这个时候是不能写入主内存的,因为会覆盖掉线程1的操作,具体过程如下图。
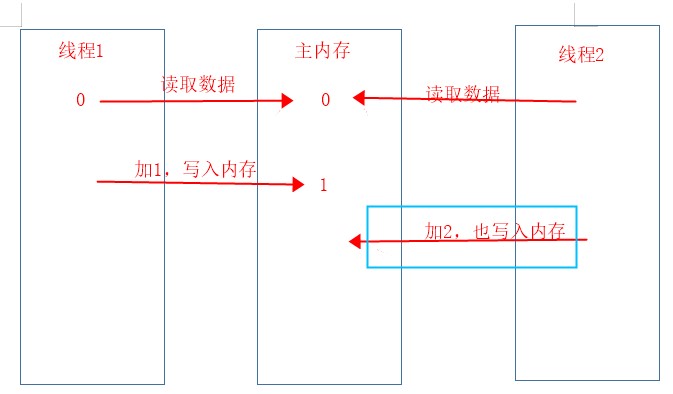
CAS是在线程2尝试写入内存的时候,通过比较并设置(CompareAndSet)发现现在主内存当前值为1,和他刚开始读取的值0不一样,所以他会放弃本次修改,重新读取主内存的最新值,然后再重试下线程2的具体逻辑操作,再次尝试写入主内存。如果这时候线程1,再次对主内存进行了修改,线程2发现现在主内存的值又和预期不一样,所以将放弃本次修改,再次读取主内存最新值,再次重试并尝试写入主内存。我们可以发现这是一个重复比较的过程,即直到和预期初始值一样,才会写入主内存,否则将一直读取重试的循环。这就是上面for循环的意义。
CAS的实现实际上利用了CPU指令来实现的,如果操作系统不支持CAS,还是会加锁的,如果操作系统支持CAS,则使用原子性的CPU指令。
原子引用
在日常使用中,我们不止对上述基本类型进行原子操作,而是需要对一些复杂类型进行原子操作,所以需要AtomicReference。
不安全实现
先看不安全的BigDecimal类型:
public classtestReference {static BigDecimal number =BigDecimal.ZERO;public static void main(String[] args) throwsException {
Runnable runnable= newRunnable() {
@Overridepublic voidrun() {for (int i = 0; i < 1000; i++) {
number=number.add(BigDecimal.ONE);
}
}
};
Thread t1= newThread(runnable);
t1.start();
Thread t2= newThread(runnable);
t2.start();
t1.join();
t2.join();
System.out.println(number);
}
}
运行结果如下图,我们可以看到两个线程,自循环1000次加1操作,最终结果应该是2000,可是结果小于2000。

安全实现-使用CAS
public classtestReference {//定义AtomicReference类型BigDecimal变量
static AtomicReference number = new AtomicReference(BigDecimal.ZERO);public static void main(String[] args) throwsException {
Runnable runnable= newRunnable() {
@Overridepublic voidrun() {for (int i = 0; i < 1000; i++) {//手动写循环+CAS判断
while(true){
BigDecimal pre=number.get();
BigDecimal next=number.get().add(BigDecimal.ONE);if(number.compareAndSet(pre,next)) {break;
}
}
}
}
};
Thread t1= newThread(runnable);
t1.start();
Thread t2= newThread(runnable);
t2.start();
t1.join();
t2.join();
System.out.println(number.get());
}
}
运行结果如下:

ABA问题及解决
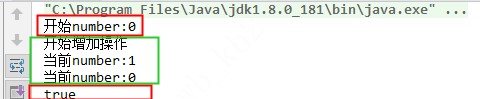
在上面CAS过程中,是通过值比较来知晓是不是能够更新成功,那如果线程1先加1再减1,这样主内存还是原来的值,即线程2还是可以更新成功的。但是这样逻辑错了,线程1已经发生了修改,线程2不能直接更新成功。
代码:
public classtestInt {static AtomicInteger number = new AtomicInteger(0);public static void main(String[] args) throwsException {
Thread t1= new Thread(newRunnable() {
@Overridepublic voidrun() {int a =number.get();
System.out.println("开始number:" +a);try{
Thread.sleep(5000L);
}catch(InterruptedException e) {
e.printStackTrace();
}
System.out.println(number.compareAndSet(a, a++));
}
});
t1.start();
Thread t2= new Thread(newRunnable() {
@Overridepublic voidrun() {
System.out.println("开始增加操作");int a =number.incrementAndGet();
System.out.println("当前number:" +a);int b =number.decrementAndGet();
System.out.println("当前number:" +b);
}
});
t2.start();
t1.join();
t2.join();
}
}
我们看线程2对其进行了一系列操作,但是最后打印了还是true,表示可以更新成功的。这显然不对。
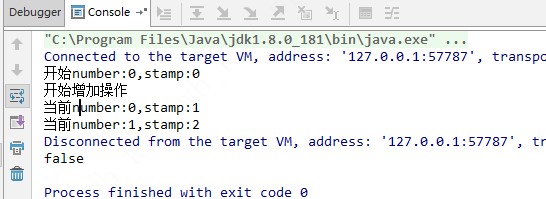
那我们可以使用AtomicStampedReference,为其添加一个版本号。线程1在刚开始读取主内存的时候,获取到值为0,版本为1,线程2也获取到这两个值,线程1进行加1,减1的操作的时候,版本各加1,现在主内存的值为0,版本为2,而线程2还拿着预计值为0,版本为1的数据尝试写入主内存,这个时候因版本不同而更新失败。具体我们用代码试下:
public classtestInt {static AtomicStampedReference number = new AtomicStampedReference(0, 0);public static void main(String[] args) throwsException {
Thread t1= new Thread(newRunnable() {
@Overridepublic voidrun() {int a =number.getReference();int s =number.getStamp();
System.out.println("开始number:" + a + ",stamp:" +s);try{
Thread.sleep(5000L);
}catch(InterruptedException e) {
e.printStackTrace();
}
System.out.println(number.compareAndSet(a, a+ 1, s, s + 1));
}
});
t1.start();
Thread t2= new Thread(newRunnable() {
@Overridepublic voidrun() {
System.out.println("开始增加操作");int a =number.getReference();int s =number.getStamp();
number.compareAndSet(a, a+ 1, s, s + 1);
System.out.println("当前number:" + a + ",stamp:" + (s + 1));
a=number.getReference();
s=number.getStamp();
number.compareAndSet(a, a- 1, s, s + 1);
System.out.println("当前number:" + a + ",stamp:" + (s+1));
}
});
t2.start();
t1.join();
t2.join();
}
}
我们可以看到每次操作都会更新stamp(版本号),在最后对比的时候不仅比较值,还比较版本号,所以是不能更新成功的,false.
原子数组
AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray三者类似,所以以AtomicIntegerArray为例,我们可以将下面AtomicIntegerArray看做是AtomicInteger类型的数组,其底层很类似,就不详细写了。
AtomicIntegerArray array = new AtomicIntegerArray(10);
array.getAndIncrement(0); //将第0个元素原子地增加1
AtomicInteger[] array= new AtomicInteger[10];
array[0].getAndIncrement(); //将第0个元素原子地增加1
字段更新器和原子累加器比较简单,这里就不说了。
Atomic进阶篇分界线
LongAdder源码分析
LongAdder使用
LongAdder是jdk1.8之后新加的,那为什么要加他?这个问题,下面将回答,我们先看下如何使用。
public classtestLongAdder {public static void main(String[] args) throwsException {
LongAdder number= newLongAdder();
Runnable runnable= newRunnable() {
@Overridepublic voidrun() {for (int j = 0; j < 10000; j++) {
number.add(1L);
}
}
};
Thread t1= newThread(runnable);
Thread t2= newThread(runnable);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("number:" +number);
}
}
我们可以看到LongAdder的使用和AtomicLong大致相同,使用两个线程Thread1,Thread2对number值各进行一万次的自增操作,最后的number是正确的两万。

与Atomic的对比优势
那问题来了,既然AtomicLong能够完成对多线程下的number进行线程安全的操作,那为什么还要LongAdder?我们先来段代码比较下,两个在结果都是正确的前提下,性能方面的差距。
public classtestLongAdder {public static voidmain(String[] args) {//1个线程,进行100万次自增操作
test1(1,1000000);//10个线程,进行100万次自增操作
test1(10,1000000);//100个线程,进行100万次自增操作
test1(100,1000000);
}static void test1(int threadCount,inttimes){long startTime=System.currentTimeMillis();
AtomicLong number1=newAtomicLong();
List threads1=new ArrayList<>();for(int i=0;i
threads1.add(new Thread(newRunnable() {
@Overridepublic voidrun() {for (int j = 0; j < times; j++) {
number1.incrementAndGet();
}
}
}));
}
threads1.forEach(thread->thread.start());
threads1.forEach(thread->{try{
thread.join();
}catch(InterruptedException e) {
e.printStackTrace();
}
} );long endTime=System.currentTimeMillis();
System.out.println("AtomicLong:"+number1+",time:"+(endTime-startTime));
LongAdder number2=newLongAdder();
List threads2=new ArrayList<>();for(int i=0;i
threads2.add(new Thread(newRunnable() {
@Overridepublic voidrun() {for (int j = 0; j < times; j++) {
number2.add(1);
}
}
}));
}
threads2.forEach(thread->thread.start());
threads2.forEach(thread->{try{
thread.join();
}catch(InterruptedException e) {
e.printStackTrace();
}
} );
System.out.println("LongAdder:"+number2+",time:"+(System.currentTimeMillis()-endTime));
}
}
上述代码对比了1个线程,10个线程,100个线程在进行100百次自增操作后,AtomicLong和LongAdder所花费的时间。通过打印语句,我们发现在最终number1和number2都正确的基础上,LongAdder花费的时间比AtomicLong少了一个量级。
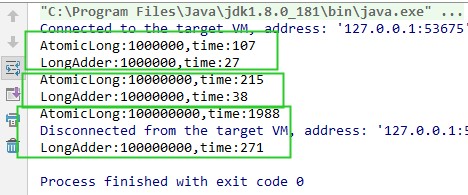
源码分析
那为什么会导致这种情况,我们就要从源码层面分析。AtomicLong为什么效率低?因为如果线程数量一多,尤其在高并发的情况下,比如有100个线程同时想要对对象进行操作,肯定只有一个线程会获取到锁,其他99个线程可能空转,一直循环知道线程释放锁。如果该线程操作完毕释放了锁,其他99个线程再次竞争,也只有一个线程获取锁,另外98个线程还是空转,直到锁被释放。这样CAS操作会浪费大量资源在空转上,从而使得AtomicLong在线程数越来越多的情况下越来越慢。
AtomicLong是多个线程对同一个value值进行操作,导致多个线程自旋次数太多,性能降低。而LongAdder在无竞争的情况,跟AtomicLong一样,对同一个base进行操作,当出现竞争关系时则是采用化整为零的做法,从空间换时间,用一个数组cells,将一个value拆分进这个数组cells。多个线程需要同时对value进行操作时候,可以对线程id进行hash得到hash值,再根据hash值映射到这个数组cells的某个下标,再对该下标所对应的值进行自增操作。当所有线程操作完毕,将数组cells的所有值和无竞争值base都加起来作为最终结果。
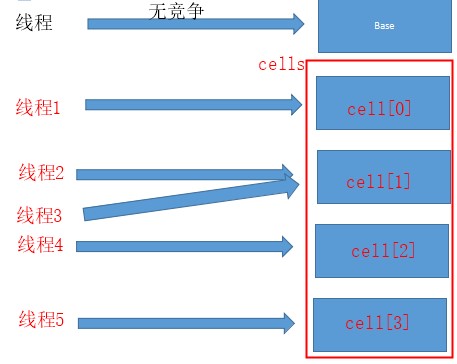
我们先看下LongAdder里面的字段,发现其里面没有,主要是在其继承的Stripped64类中,有下面四个主要变量。
/**CPU数量,即cells数组的最大长度*/
static final int NCPU =Runtime.getRuntime().availableProcessors();/***cells数组,为2的幂,2,4,8,16.....,方便以后位运算*/
transient volatileCell[] cells;/*** 基值,主要用于没有竞争的情况,通过CAS更新。*/
transient volatile longbase;/*** 调整单元格大小(扩容),创建单元格时使用的锁。*/
transient volatile int cellsBusy;
下面是add方法开始。
public void add(longx) {//as:cells数组的引用//b:base的基础值//v:期望值//m:cells数组大小//a:当前数组命中的单元
Cell[] as; long b, v; intm; Cell a;//as不为空(cells已经初始化过,说明之前有其他线程对初始化)或者CAS操作不成功(线程间出现竞争)
if ((as = cells) != null || !casBase(b = base, b +x)) {//初始化uncontented,true表示未竞争(因为有两个情况,这里先初始化,后面对其修改,就能区分这两种情况)
boolean uncontended = true;//as等于null(cells未初始化)//或者线程id哈希出来的下标所对应的值为空(cell等于空),getProbe() & m功能是获取下标,底层逻辑是位运算//或者更新失败为false,即发生竞争,取非就为ture
if (as == null || (m = as.length - 1) < 0 ||(a= as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v +x)))//进入到if里面,说明更新case失败,或者更新某个cell也失败了,或者cell为空,或者cells为空
longAccumulate(x, null, uncontended);
}
}
从LongAdder调用Stripped64的longAccumulate方法,主要是初始化cells,cells的扩容,多个线程同时命中一个cell的竞争操作。
final void longAccumulate(longx, LongBinaryOperator fn,booleanwasUncontended) {//x:add的值,fn:为null,wasUncontended:是否发生竞争,true为发生竞争,false为不发生竞争
int h;//线程的hash值//如果该线程为0,即第一次进来,所以ThreadLocalRandom强制初始化线程id,再对其hash
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current();
h=getProbe();
wasUncontended= true;
}//扩容意向,为false肯定不扩容,为true可能扩容
boolean collide = false;//死循环
for(;;) {//as:cells数组的引用//a:当前线程命中的cell//n:cells的长度//v:当前线程命中的cell所拥有的value值
Cell[] as; Cell a; int n; longv;//cells不为空
if ((as = cells) != null && (n = as.length) > 0) {//当前线程命中的cell为空,下面逻辑是新增cell
if ((a = as[(n - 1) & h]) == null) {if (cellsBusy == 0) { //Try to attach new Cell
Cell r = new Cell(x); //Optimistically create
if (cellsBusy == 0 &&casCellsBusy()) {boolean created = false;try { //Recheck under lock
Cell[] rs; intm, j;if ((rs = cells) != null &&(m= rs.length) > 0 &&rs[j= (m - 1) & h] == null) {
rs[j]=r;
created= true;
}
}finally{
cellsBusy= 0;
}if(created)break;continue; //Slot is now non-empty
}
}
collide= false;
}//发生竞争
else if (!wasUncontended) //CAS already known to fail
wasUncontended = true; //Continue after rehash//没有竞争,尝试修改当前线程对应的cell值,成功跳出循环
else if (a.cas(v = a.value, ((fn == null) ? v +x :
fn.applyAsLong(v, x))))break;//如果n大于CPU最大数量,不可扩容
else if (n >= NCPU || cells !=as)
collide= false; //At max size or stale
else if (!collide)
collide= true;//获取到了锁,进行扩容,为2的幂,
else if (cellsBusy == 0 &&casCellsBusy()) {try{if (cells == as) { //Expand table unless stale
Cell[] rs = new Cell[n << 1];//左移一位运算符,数量加倍
for (int i = 0; i < n; ++i)
rs[i]=as[i];
cells=rs;
}
}finally{
cellsBusy= 0;
}
collide= false;continue; //Retry with expanded table
}
h=advanceProbe(h);
}//cells等于空,并且获取到锁,开始初始化工作,创建结束释放锁,继续循环
else if (cellsBusy == 0 && cells == as &&casCellsBusy()) {boolean init = false;try { //Initialize table
if (cells ==as) {
Cell[] rs= new Cell[2];
rs[h& 1] = newCell(x);
cells=rs;
init= true;
}
}finally{
cellsBusy= 0;
}if(init)break;
}else if (casBase(v = base, ((fn == null) ? v +x :
fn.applyAsLong(v, x))))break; //Fall back on using base
}
}
结语
结束了,撒花。这篇主要说了Atomic的一些使用,包括Atomic原子类(AtomicInteger,AtomicLong,AtomicBoolean),Atomic原子引用(AtomicReference,AtomicStampedReference),以及1.8之后LongAdder的优势,源码分析。过程还穿插了一些CAS,ABA问题引入和解决方式。

参考资料















 504
504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









