






 本文介绍了如何使用js将长文本加密成短文本,并探讨了文本查重(Online Copy Detection)的实现,包括查询文本切分策略、相似性度量算法如hash和字符串匹配,以及整体技术框架。文章提供了实验结果,选择了minHash-LSH Forest算法作为系统实现的算法。
本文介绍了如何使用js将长文本加密成短文本,并探讨了文本查重(Online Copy Detection)的实现,包括查询文本切分策略、相似性度量算法如hash和字符串匹配,以及整体技术框架。文章提供了实验结果,选择了minHash-LSH Forest算法作为系统实现的算法。
(给算法爱好者加星标,修炼编程内功)
作者:夜谷子
https://blog.csdn.net/weixin_43098787/article/details/82836140
前言:
我们每个人当年毕业的时候,大概都被论文查重折磨了很久吧? 那么你对查重技术有没有什么好奇呢?
希望本文能对你们有所启发。
1、概述
1.1 需求
给定一段文本,需要返回其和网络开放性数据相比的整体重复率以及具体的重复情况(具体重复的句子/字符串以及重复程度)。
1.2 问题分析
该问题属于copy-detection领域。
由于需要给出查询文本具体重复的句子/字符串以及相应的重复程度,所以我们需要对查询文本进行合理的切分,并需要一一计算出切分后得到的字符串与在线开放互联网数据的相似内容和相似度。
该问题属于短文本相似性计算问题。需寻求短文本相似性计算方案。
另外,对于计算规模,大体上一条300字的查询文本,可以被切分为10-20条短文本,对于每一条短文本,利用爬虫返回搜索引擎匹配的前20条结果(即20条长文本,切分后平均得到约为4000条短文本)。
 系统的关键性能指标主要包括结果精度和计算速度。
系统的关键性能指标主要包括结果精度和计算速度。
由上图可知,主要影响因素可概括为4点:查询文本切分策略、相似性度量算方法、爬虫自身性能、返回文本数的设置。
1.3 整体技术框架

2、爬虫设计
主要python包:
requests+BeautifulSoup+jparser+url2io
其中jparser、url2io都用于网页文本正文提取,url2io准确率高,但不稳定,解析错误时则调用jparser。
通过两者结合使用来提高正文提取的效果。
爬虫整体实现方法和代码放置于github:https://github.com/Neo-Luo/scrapy_baidu
3、查询文本切分策略
考虑到如下几个问题:
(1)百度搜索输入框中文字符的最大输入个数为:38。
(2)通用中文查重标准认为:连续重复字符数大于等于13属于抄袭。
(3)句意统一,字符串越长,百度搜索返回的结果往往和查询结果越匹配。
我们制定如下的查询文本切分策略:
对于查询文本,首先以“,;。!?”为切分符进行切分,得到切分后的字符串集合。
对于切分后的字符串,从前往后尽量组合,在组合后的字符串长度小于38的前提下,组合成的字符串长度越长越好。
例如,如果s[i+1]+s[i]>s[i]且s[i+1]+s[i]<38,则将s[i+1]、s[i]两者组合成新的字符串。
具体实现代码如下:
def split_search(query_all): query_array = re.split(u"[,;。!?]", query_all.decode('utf-8')) if(len(query_array[-1])<5): query_array.pop(-1) flag = len(query_array)-1 i = -1 while (i i += 1 if(i>flag-1): break elif(len(query_array[i])<38): if(len(query_array[i])+len(query_array[i+1])>38): continue else: query_array[i+1] = query_array[i] + query_array[i+1] query_array.pop(i) flag -= 1 i -= 1 else: continue return query_array4、文本相似性计算
4.1 计算粒度
对于查询文本和搜索结果文本,皆以“,;。!?”为切分符。
对于切分后的字符串,从前往后组合成长度大于13的字符串,也就是使每一个用于计算的字符串都满足长度大于13。
def split_content_all(query_all): query_array = re.split(r"[,;。!?]", query_all) flag = len(query_array)-1 for i in range(flag): if(i>flag-1): break elif(len(query_array[i])>=13): continue else: query_array[i+1] = query_array[i] + query_array[i+1] query_array.pop(i) flag -= 1 return query_array4.2 相似性度量算法
在介绍具体算法之前,我们先来了解一下有关copy-detection的知识。
copy-detection主要用于检测文件或网页中相同的内容,判定是否存在拷贝、抄袭等行为以及程度。
在下面的讨论中,我们将范围缩减到只考虑包含ASCII字符的文件,不考虑图片及视屏等内容。
通常情况下,我们认为用于copy-detection的算法应该满足以下要求:
1、无视空白符(Whitespace insensitivity)。
在比较文件内容的过程中,我们通常不希望被空格、制表符、标点符号等影响我们判定的结果,因为它们并不是我们感兴趣的内容。在不同的应用下,我们感兴趣的内容会有些不同,比如在程序代码文件中,变量名通常是我们不感兴趣的。
2、噪音抑制(Noise suppression)。
主要是指应该排除一些可以接受的拷贝,比如成语、谚语、免责声明等,这些也不是我们感兴趣的。比如在程序代码文件中,你或许希望排除一些教师给定标程中的内容。
3、位置无关性(Position independence)。
在完全拷贝一份文件后,简单的将文件内容调换一下位置,仍然属于抄袭行为。位置无关性就反映了这么一种性质,粗粒度的位置调换不会影响最终的判定。
更进一步说,从原文件中添加或者删除一段内容,不应该影响到其他部分的判断。
基于对问题的分析,我们选取了hash类算法(计算速度快)和字符串直接匹配算法(准确度高)进行了相应实验,下文将对各类算法的实现和实验结果进行阐述。
4.2.1 hash类算法
hash 算法的实质就是把数据映射成比较短的固定长度的散列值,从而提高存储效率或者是计算效率。
具体来说,Hash 算法就是把任意长度的输入,通过散列算法,变换成固定长度的输出。该输出就是散列值。
这种转换是一种压缩映射,散列值的空间一般远小于输入的空间。但是如果不同的数据通过hash 算法得到了相同的输出,这个就叫做碰撞,因此不可能从散列值来唯一确定输入值。
一个优秀的 hash 算法,满足:
正向快速:给定明文和 hash 算法,在有限时间和有限资源内能计算出 hash 值。
逆向困难:给定(若干) hash 值,在有限时间内很难(基本不可能)逆推出明文。
输入敏感:原始输入信息修改一点信息,产生的 hash 值看起来应该都有很大不同。
冲突避免:很难找到两段内容不同的明文,使得它们的 hash值一致(发生冲突)。即对于任意两个不同的数据块,其hash值相同的可能性极小;对于一个给定的数据块,找到和它hash值相同的数据块极为困难。
常见的hash算法包括如下几种:
winnowing算法
simHash类算法
minHash类算法
4.2.2 字符串直接匹配算法
常见的字符串直接匹配算法有很多,例如欧几里得距离、余弦距离、最长公共子序列、编辑距离(levenshtein距离)、Jaccard相似性系数等。
各类算法的实现代码参考github:https://github.com/Neo-Luo/TextSimilarity
4.2.3 实验结果
我们比较了上述各类算法的结果准确率、召回率以及时间复杂度,所得结果如下:
| 模型 | 准确度 | 召回率 | 时间复杂度 |
|---|---|---|---|
| winnowing | <60% | <60% | 低 |
| simHash | <60% | <60% | 低 |
| minHash | <60% | <60% | 低 |
| minHash-LSH Forest | 70%-90% | 70%-90% | 中 |
| 编辑距离 | >85% | >85% | 高 |
| Jaccard系数 | >85% | >85% | 高 |
上述结果中:
simHash和minHash采用的个人源码实现,由于对短文本进行hash,尽管提高了计算速度,但冲撞率较高,模型精度和准确率较低,并不适用于我们的问题情境。
minHash-LSH Forest采用的是python包datasketch实现的,通过利用多个hash函数以及LSH中的概率统计原理,降低了冲撞,模型效果较好,但计算速度有所减慢。
传统的字符串直接匹配算法在短文本相似性计算中,准确率较高,但计算速度慢。
结合现实需求,我们选取minHash-LSH Forest算法作为系统实现的算法。
4.3 整体相似度的评估
通过上述算法,我们可以得到查询文本中每一条字符串q u e r y S t r i queryStr_iqueryStri及其与开放互联网数据的重复度为s i m R a t e i simRate_isimRatei。
我们定义整个查询文本q u e r y S t r queryStrqueryStr
与开放互联网数据的重复度t o t a l S i m R a t e totalSimRatetotalSimRate为: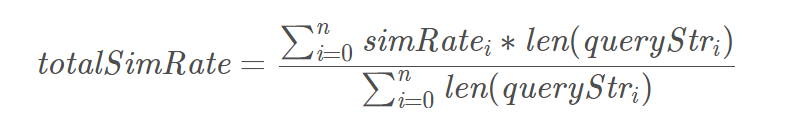
具体实现代码如下:
def cal_total_rate(final_res,query_all): score = 0 for item in final_res['detail']: score += final_res['detail'][item]['dist'] * \ len(final_res['detail'][item]['query_str']) final_res['total_rate'] = float(score) / float(len(query_all)) return final_res- EOF -
推荐阅读 点击标题可跳转1、算法题407:动态规划和滑动窗口解决最长重复子数组
2、算法题:重复子串
3、字符串:都来看看 KMP 的看家本领!
觉得本文有帮助?请分享给更多人
推荐关注「算法爱好者」,修炼编程内功

点赞和在看就是最大的支持❤️


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









