







SQL语句优化
- 尽量避免在字段开头模糊查询,会导致数据库引擎放弃索引进行全表扫描
- 尽量避免使用 in 和 not in,会导致引擎走全表扫描,可以用exist和notexist
- 尽量避免使用 or,会导致数据库引擎放弃索引进行全表扫描,可以用 union 代替 or
- 尽量避免进行 null 值的判断,会导致数据库引擎放弃索引进行全表扫描,可以给字段添加默认值 ,对默认值进行判断
- 尽量避免在 where 条件中等号的左侧进行表达式、函数操作,会导致数据库引擎放弃索引进行全表扫描
- 当数据量大时,避免使用 where 1=1 的条件;通常为了方便拼装查询条件,我们会默认使用该条件,数据库引擎会放弃索引进行全表扫描。
-
避免使用<>或者!=等判断条件。如确实业务需要,使用到不等于符号,需要在重新评估索引建立,避免在此字段上建立索引,改由查询条件中其他索引字段代替。
-
where 条件仅包含复合索引非前置列;例如:复合(联合)索引包含 key_part1,key_part2,key_part3 三列,但 SQL 语句没有包含索引前置列"key_part1",按照 MySQL 联合索引的最左匹配原则,不会走联合索引。
-
隐式类型转换造成不使用索引;如 SQL 语句由于索引对列类型为 varchar,但给定的值为数值,涉及隐式类型转换,造成不能正确走索引。
-
order by 条件要与 where 中条件一致,否则 order by 不会利用索引进行排序
-- 不走age索引 SELECT * FROM t order by age; -- 走age索引 SELECT * FROM t where age > 0 order by age; -
多表关联查询时,小表在前,大表在后
-
调整 Where 字句中的连接顺序;MySQL 采用从左往右,自上而下的顺序解析 where 子句。根据这个原理,应将过滤数据多的条件往前放,最快速度缩小结果集。
-
优化limit分页;在使用limit分页操作的时候,例如limit10000,20,这时MySQL需要查询10020条记录然后只返回最后20条数据,前面10000条数据都会被抛弃,这样的代价非常高,优化此类查询利用表的覆盖索引,从索引中就能获取数据列
举个例子:val为普通经索引select * from test where val=4 limit 300000,5查询到索引叶子节点数据。
- 根据叶子节点上的主键值去聚簇索引上查询需要的全部字段值。
需要查询300005次索引节点,查询300005次聚簇索引的数据,最后再将结果过滤掉前300000条,取出最后5条。MySQL耗费了大量随机I/O在查询聚簇索引的数据上,而有300000次随机I/O查询到的数据是不会出现在结果集当中的。
最大id查询法
举个例子,查询第一页的时候是limit 0,10 查询到的最后一条id是10,那么下一页的查询只需要查询id大于10的19条数据即可。

BETWEEN … AND

这两种方式也只能适用于自增主键,并且id没有断裂,否者不推荐这种方式,我们发现使用BETWEEN AND的时候查询出来11条记录,也就是说BETWEEN AND包含了两边的边间条件。使用的时候需要特别注意一下。
limit id

延迟关联
延迟关联,他让mysql扫描尽可能少的记录,获取到需要访问的记录后再根据关联列回到远表查询需要的所有列

索引优化
- 当使用索引列进行查询的时候尽量不要使用表达式,把计算放到业务层而不是数据库层。
--推荐 select uid,age,uname from t_user where uid=1; --不推荐 select uid,age,uname from t_user where uid+9=10; - 尽量使用主键查询,而不是其他索引,因为主键查询不会触发回表查询
- 有时候需要索引很长的字符串,这会让索引变的大且慢,通常情况下可以使用某个列开始的部分字符串,这样大大的节约索引空间,从而提高索引效率,但这会降低索引的选择性
- 使用索引扫描排序
- 范围列可以用到索引;范围条件是:<、<=、>、>=、between。范围列可以用到索引,但是范围列后面的列无法用到索引,索引最多用于一个范围列。
- 更新十分频繁,数据区分度不高的字段上不宜建立索引
- 创建索引的列,不允许为null,可能会得到不符合预期的结果
-
当需要进行表连接的时候,最好不要超过三张表,如果需要join的字段,数据类型必须一
-
能使用limit的时候尽量使用limit
缓存优化
关系型数据库已经非常成熟,但是并不是完美的,仍然有以下缺点:
-
关系型数据库存储的是行记录,无法存储数据结构。
-
关系型数据库的Schema扩展非常不方便。
关系型数据库的Schema是强约束,无法操作不存在的列。当要扩展列时,需要先执行DDL操作。
-
关系型数据库在大数据场景下I/O较高。 如果对关系型数据库的表进行统计的时候,I/O会非常的高。即使只是统计几列的数据,它也会把行中所有列的数据加载到内存当中。
-
关系型数据库的全文搜索功能比较弱。 关系型数据库的全文搜索只能用Like进行扫描,性能低。
常见的NoSQL方案分为以下几类:
- K-V存储:解决关系型数据库无法存储数据结构的问题,如Redis。
- 文档型数据库:解决关系型数据库强Schema的问题,如MongoDB。
- 列式数据库:解决大数据场景下I/O较高的问题,如HBASE。
- 全文搜索引擎:解决关系型数据库全文搜索功能弱的问题,如ES。
架构优化
读写分离
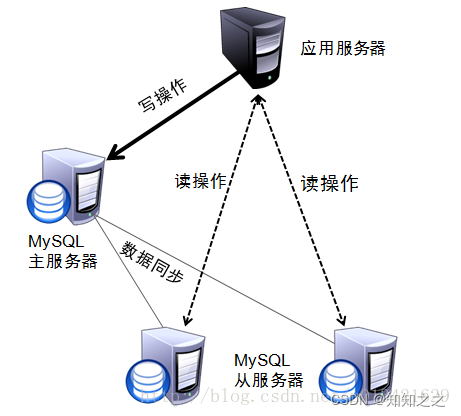
读写分离的基本实现
- 数据库服务器搭建集群模式,一主一从或一主多从。
- 数据库主机负责写,数据库从机负责读。
- 数据库主机通过复制将数据同步到从机,每个数据库服务器都保存所有的数据。
- 业务将写操作发送到数据库主机,将读操作发送到数据库从机。
需要注意的是:这里的是“主从集群”,而不是“主备集群”。“主从集群”的从机是需要负责读操作的。而“主备集群”的备机只是提供数据备份功能,不对外提供服务。
读写分离会引入二个设计复杂度:主从复制延迟和分配机制
主从复制延迟
主从复制延迟带来的问题是:如果业务服务器在数据写入主机后立即进行读取,读操作读取的是从机的数据,由于主从复制延迟,主机还没有把数据复制到从机。此时就无法读取到最新的数据,业务可能就会发生错误。常见的场景就是在注册成功后,马上登录却提示未注册。
解决主从复制延迟问题的方法:
-
写操作后的读操作指定发给数据库主服务器。
这种方式和业务进行强绑定,对业务的侵入和影响比较大。
-
读从机失败后再从主机读取。
这是常见的二次读取,与业务无绑定,只需要设计底层的API即可。但是如果有大量的二次读取的话,会极大的增加主机的压力。
-
关键业务的读写操作全部指向数据库主服务器,非关键业务采用读写分离。
分配机制
将读写操作分离,然后访问不同的数据库机器,主要有二种实现方式:程序代码封装和中间件封装。
- 程序代码封装
程序代码封装是指在代码层次抽象出一个中间层,实现读写操作分离和数据库连接管理。例如通过Hibernate的封装,就可以实现读写分离。基本架构如下:
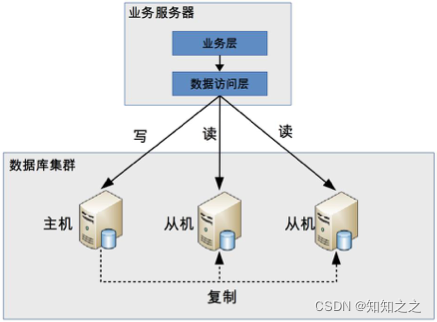
程序代码封装有以下几个特点:
- 实现简单
- 每个编程语言需要实现一次,无法通用。如果一个系统包含多个语言,则需要重复编写。
- 故障情况下,如果主从发生切换后,则可能所有系统需要修改配置变重启生效。
- 中间件封装
中间件封装是指独立出一套系统,实现读写分离和数据库连接管理。中间件对业务提供SQL兼容协议,业务端无须进行读写分离操作。对于业务服务器来说,访问中间件和访问数据库服务器是无区别的。其实中间件对于业务方来说就相当于数据库。
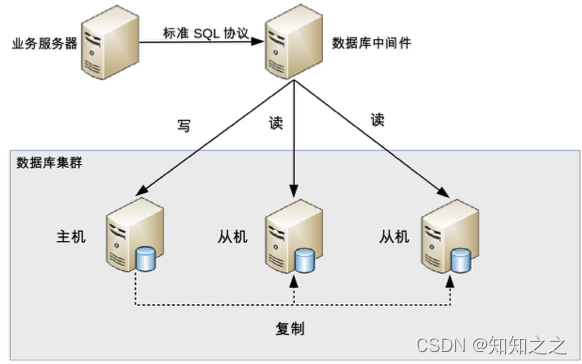
中间件封装的优点在于:
- 支持多语言
- 支持完整的sql语法和数据库服务器协议。
- 中间件不执行真正的sql,但是所有的sql操作都需要经过中间件。所以中间件的性能要求很高。
- 数据库主从切换到业务服务器无感知,数据库中间件可以探测数据库服务器的主从状态。
分库分表
读写分离分散了数据库的读写压力,但并没有降低数据库的存储压力。当数据量达到上亿的时候,单台数据库就会成为瓶颈。
- 单表数据量太大的话,读写性能会很差。增加索引,索引也会很大。
- 数据库文件太大的话,备份和恢复都要花费很多时间。
- 数据库文件太大,极端情况下,丢失数据的风险变高。
所以单个数据库服务器存储的数据量不能太大,所以需要将存储分配到多台数据库服务器上。常见的方式有二种:分库,分表。
分库
分库是批将数据按模块将数据分配到不同的数据库服务器上。如对于电商网站来说,可以把用户、订单、商品模块数据分别放到不同的数据库服务器上,而不是放在单一的服务器上。
分库降低了存储和访问压力,但是也引进了一些新的复杂度。
join操作
分库后对于不同的库之间的数据无法进行Join操作。本来在同一个数据库的数据,二张表的数据只需要进行Join即可,但分库后这二个表在不同的库,需要进行多次查询。
那么,为了解决关联查询的问题,我们可以想一些别的办法。例如:
- 字段冗余设计:这是一种反范式的设计,也是空间换时间的典例,它是将需要多次用到的数据分布到多张表中,避免了 JOIN 查询
- 数据组装:也就是多次查询,将多次查询的数据组装在一起构成整体数据
- 拆分查询:注意,这里所说的查询指的是前端发起的查询请求,即前端把复杂查询(多表)拆分成多次简单查询(单表)
- 大数据工具支持:例如将业务数据同步到数据中心,通过大数据工具进行Join操作
事务问题
原先在同一个库里,可以在同一个事务里进行修改,分库后,表在不同的库里,无法在同一个库里进行修改。
 https://blog.csdn.net/weixin_35973945/article/details/124042368?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_35973945/article/details/124042368?spm=1001.2014.3001.5501成本问题。原先在一个库里,只需要一台服务器即可,分库后,需要3台服务器。
分表
分库后,将不同的数据存储在不同的数据服务器上,但是随着业务的发展,单表的规模也会达到单台服务器的处理瓶颈。此时就需要对表进行拆分了。
单表拆分有二种方式:垂直拆分和水平拆分。
- 从上往下切就是垂直拆分。比如把一个用户表的id,name,age拆分一张表,而id,desc,nickname拆成另外一张表。
- 从左往右切就是水平拆分。比如对于用户表,把用户ID从1-999999拆成一张表,把用户ID从1000000-1999999拆成另一张表。
根据业务的需求,我们可以对表进行多次拆分,如多次垂直拆分和水平拆分。并不是只固定只能拆分一次。
单表进行切分后,是否需要放在不同的数据库服务器上,可以根据实际的拆分效果来确定。如果带来了很大的性能提升,则没必要放在不同的数据库服务器上。但是如果单表拆分后依然无法满足性能的要求,那就不得不考虑分库的作法。
虽然分表减轻了存储压力和带来了性能的提升,但和分库一样,仍然会带来一些复杂库问题。
建议
不建议在一遇到性能瓶颈时就采用分库分表方式,可以选做以下的尝试:
- 做硬件优化。如增加内存(如果可行的),机械硬盘更换成固态硬盘。
- 先做数据库服务器的调优,比如增加索引。
- 引入缓存。如redis。
- 程序与数据库的表的优化,重构。如减少不必要的查询,额外的数据冗余。
- 如上方式都不能提升性能,在考虑分库分表,并且要有预估性。


















 3311
3311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









