






B树和B+树的区别
1,B树的叶子节点和内节点存在的都是数据行的所有信息,B+树的内节点值存放键(索引)信息,数据都在叶子节点上。
2,由于B树键和值的所有信息,所以每页的存储的数据行相对较少,随数据发展,该树发成为一个高瘦的树;相反,B+树的内节点只存放键值,所以会成为一个矮胖的树。所以就搜索而言,B+树的效率比B树的效率要高。
3,B树的查询效率和所查的键在B树种的位置有关;而B+树的复杂度对于某个B+树来说是固定的。
4,B树整体而言相对B+树可以节省存储空间,但是插入删除的复杂度明显增加,而且性能不平衡(有时很快能找到合适位置,有时需要消耗大量的IO)。而B+树是一种很好的折中方案。查询过程稳定,插入删除操作一般最多也是进行一次分裂(合适的位置的节点存储慢了,需要分裂)。
5,B树种所有的数据只存储一次。B+树种除了叶子节点存储所有数据以外,还需要内节点存储键的数据。所以在占用空间方面,B+树的方式比B树占用空间要多一些,但是B+树的方式提升了整体性能。
索引的设计
影响计算机任务的三个因素:内存、处理器和磁盘的速度。
磁盘的性能与读写顺序有关,顺序读写比随机读写要快得多。
索引设计存储方式:
1,将磁盘空间或文件划分未许多大小相同的块或页,每个块可以存储多个行。
2,在一个块内,数据通过链表或者数组的方式来进行组织管理。
3,在一个块内,所有的数据也是按照键值排序的,可以通过经典的二分查找快速定位到相应的数据行。
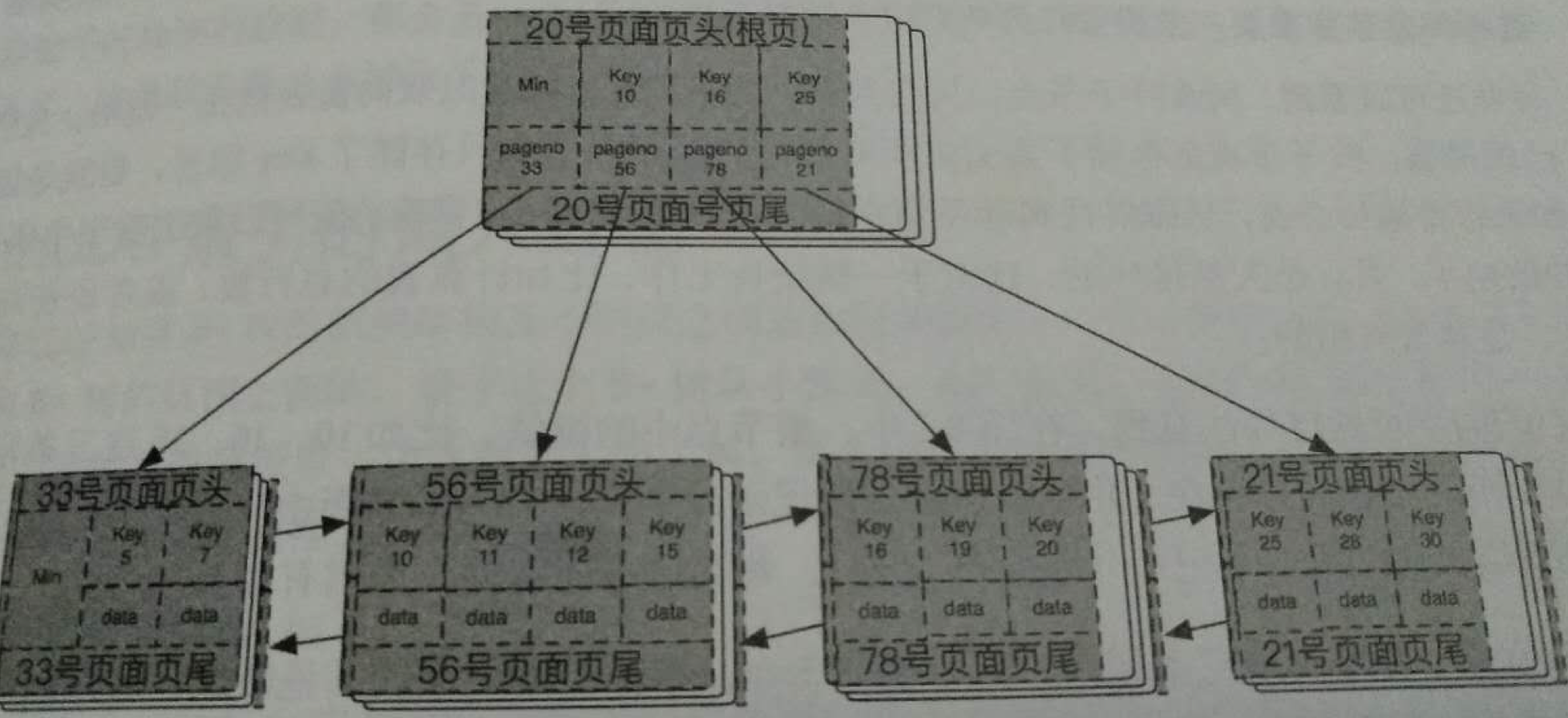
4,通过块来承载数据,通过B+树来组织不同的块之间的关系。
5,通过内节点的键值和一个位置信息、内节点和下层节点或者叶子节点的指针,可以很方便的找到该内节点的子节点。
聚集索引和二级索引
存储所有数据的索引成为聚集索引,聚集索引的顺序是按照主键(可以是Rowid或者自增ID或者用户设置的其他主键)排序。
回表,二级索引上的数据列不能全部覆盖锁需要的查询,这就需要通过二级索引的指针查找到聚集索引。
聚集索引的结构:
索引结构:[主键列][TRXID][ROLLPTR][其他建表时创建的非主键列]
参与记录比较的列:主键列
内节点Key列:[主键列]+pageno指针
注意:上面所说的主键,若用户有定义主键就是指用户定义的主键;否则是系统给的不可见的主键(Rowid)
二级索引的结构
索引结构:[索引列][主键列]
参与记录和比较的列:[索引列][主键列]
内节点的key列:[索引列][主键列]+pageno
神奇的B+树网络















 752
752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









