







olami开放平台sdk除了支持语音识别功能外,更强大的在于支持语义理解功能,在Android平台和iOS平台都有示例demo供大家下载。
在web端,基于JavaScript用olami开放平台sdk也可以实现语音识别语义理解。本文就实现了这样一个小程序,web客户端本地用麦克风录音,录音的数据用speex压缩,然后跨域向服务器发送请求,返回识别的语音和语义字符串并显示。
先上图:
如下图刚载入的时候,未录音前界面

点击开始录音button后

一句话说完自动检测尾音结束标志然后压缩上传给服务器进行识别
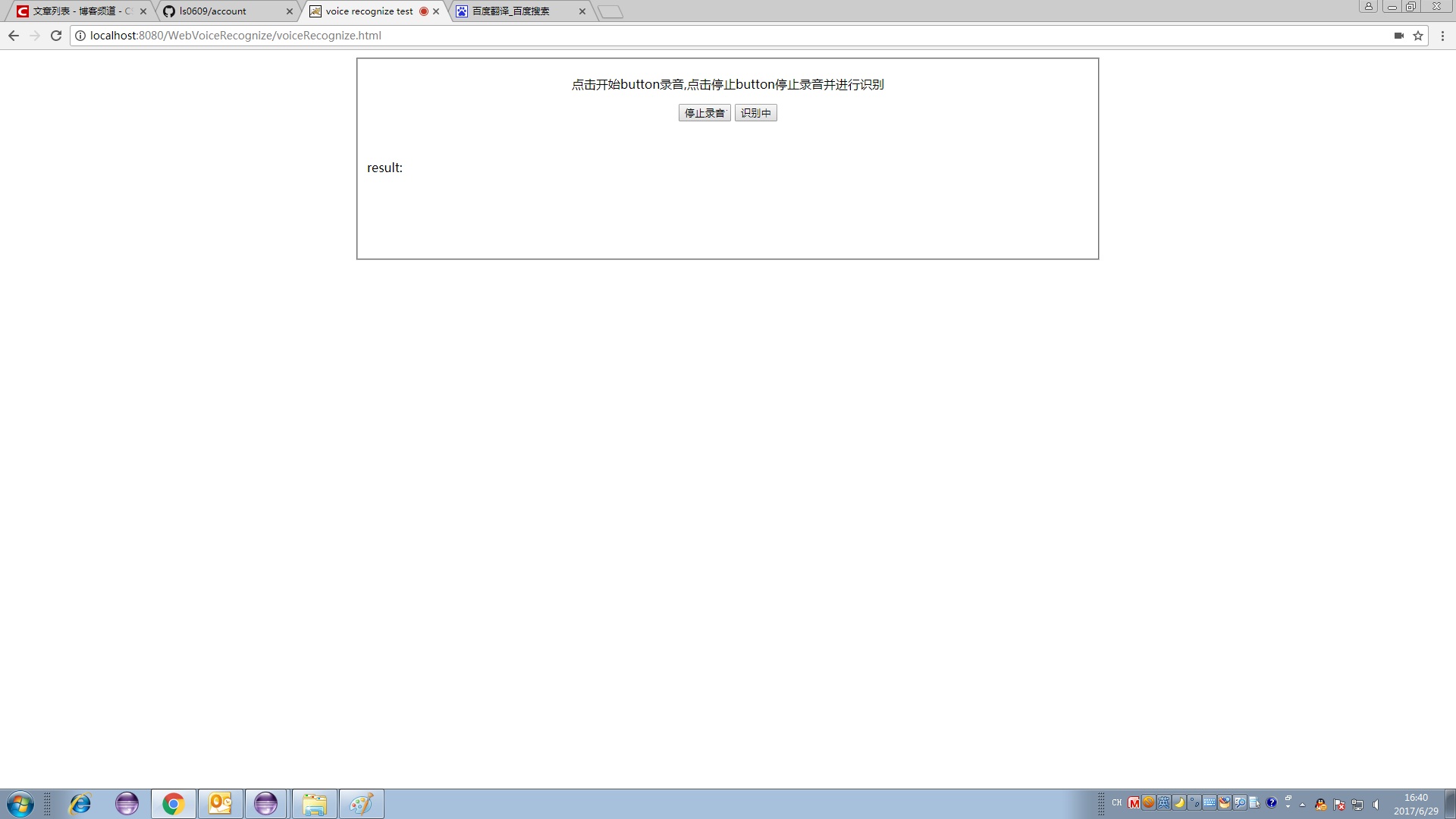
将从服务器获取的识别结果显示到界面上

本例中说的语音是:“我要听三国演义这本书”,用的是android平台听书app建立的语法。返回的json字串如下:
{
“data”: {
“asr”: {
“result”:“我要听三国演义这本书”,
“speech_status”: 0,
“final”: true,
“status”: 0
},
“nli”: [
{
“desc_obj”: {
“result”:“正在努力搜索中,请稍等”,
“status”: 0
},
“semantic”: [
{
“app”: “musiccontrol”,
“input”:“我要听三国演义这本书”,
“slots”: [
{
“name”: “songname”,
“value”:“三国演义”
}
],
“modifier”
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 319
319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









