






场景:
有这么个需求:设计开发一个评论系统,要求用户可以评论文章以及相互回复,无层级数限制。
这个需求开发人员基本都遇到过,可以先回忆或考虑这个数据表如何设计!
定义:
存在递归关系的数据很常见,数据常会像树或者以层级方式组织。在树形结构中,实例被称为节点(node),每个节
点有多个子节点和一个父节点,最上面的节点叫根(root)节点,它没有父节点,最底层的没有子节点的节点叫叶
(leaf), 中间的节点简单地称为非叶(nonleaf)节点。
评论数据就是一种树形结构数据,评论的子节点就是它的回复。其他的树形结构数据像职员与经理的关系,菜单等等很多;
方案:以下所有方案中暂不考虑外键约束,数据库是MYSQL!
邻接表
这个可能是最常见的解决方案,直接添加parent_id字段,引用同一张表中的其他回复。表结构如下
CREATE TABLE `Comments` (
`comment_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '评论ID',
`parent_id` int(11) NOT NULL DEFAULT '0' COMMENT '评论的父ID',
`article_id` int(11) NOT NULL DEFAULT '0' COMMENT '文章ID',
`comment` varchar(200) DEFAULT '' COMMENT '评论内容',
PRIMARY KEY (`comment_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='简化的评论表';
邻接表总是依赖父节点,看看它的优缺点:
无法完成树操作中最普通的有一项,查询一个节点的所有后代;
要用一条简单的sql检索一个很长的回复分支还是很困难的;
也可先获取文章的所有评论,在程序的栈内存中处理整合,但数据量,访问量都大,每次有人访问都要做一次数据处理也不切实际;
增加叶子节点操作是非常方便的;
删除节点会变得比较复杂:考虑数据完整性,删除一棵子树,不得不考虑处理其所有的后代节点;
上述这种方案可被叫做:‘单纯的数‘ 反模式!
要合理的使用反模式:邻接表设计的优势在于能快速地获取一个给定节点的直接父节点,也很容易插入新节点。如果这样的需求就是你的应用程序的需求,那使用邻接表就可以很好地工作!
下面再看看其他的方案:
路径枚举
路径枚举的设计通过将所有的祖先的信息联合成一个字符串,并保存为每个节点的一个属性:
CREATE TABLE `Comments` (
`comment_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '评论ID',
`path` varchar(1000) NOT NULL DEFAULT '0' COMMENT '路径:eg: 1/2/4',
`article_id` int(11) NOT NULL DEFAULT '0' COMMENT '文章ID',
`comment` varchar(200) DEFAULT '' COMMENT '评论内容',
PRIMARY KEY (`comment_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='简化的评论表';

来看看该方案有没有解决邻接表的问题,
1. 通过比较每个节点的路径来查询一个节点的祖先:例如查找comment_id 为4的所有的祖先的sql:
SELECT * from Comments AS c where '1/3/4/' like CONCAT(c.path,'%');
2. 查询一个节点的所有后台:例如 comment_id 为 1 的所有后台:
SELECT * from Comments AS c where c.path like CONCAT('1/','%');
3. 插入节点:只需一份父节点的路径即可;comment_id是自动生成,需要先插入再修改;
该方案的缺点:数据库不能确保路径的格式总是正确或者路径中的节点确实存在,需应用程序的逻辑代码来维护,且验证字符串的正确性的开销很大;再者,无论将varcharde的长度设定为多大,依旧存在长度限制,因而不能支持树结构的无限扩展。
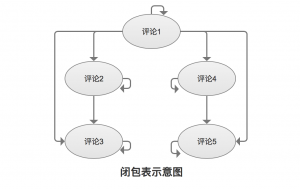
闭包表
闭包表记录树中所有节点间的关系,而不仅仅只有那些直接的父子关系,是一个简单而优雅的分级存储解决方案。
该方案不再使用Comments表来存储树的结构,而是将树中任何具有祖先-后代关系的节点对都存储在新表中,即使两个节点不是直接的父子关系,同时,还增加一行指向节点自己,表结构如下:
CREATE TABLE `Comments` (
`comment_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '评论ID',
`article_id` int(11) NOT NULL DEFAULT '0' COMMENT '文章ID',
`comment` varchar(200) DEFAULT '' COMMENT '评论内容',
PRIMARY KEY (`comment_id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8 COMMENT='简化的评论表';
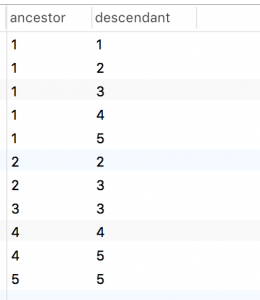
CREATE TABLE `TreePaths` (
`ancestor` int(11) NOT NULL DEFAULT '0' COMMENT '祖先',
`descendant` int(11) NOT NULL DEFAULT '0' COMMENT '后代'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
下面看看相关操作
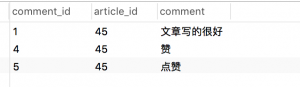
1. 搜索祖先:搜索评论5的祖先:
SELECT c.* from Comments as c JOIN TreePaths as t on c.`comment_id` = t.ancestor WHERE t.descendant=5;
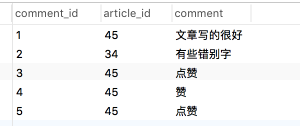
2. 搜索后台:搜索评论1的后代:
SELECT c.* from Comments as c JOIN TreePaths as t on c.`comment_id` = t.descendant WHERE t.ancestor=1;
3. 插入子节点:
例如评论5新增一个子节点,应首先插入一条自己到自己的关系,然后搜索TreePaths表中后代是评论5的所有节点,增加这些节点和新节点的’祖先-后代‘关系。
TreePaths表可以继续优化:增加path_length字段表示祖先与后代的层级数等等;
综述
以上列举了三个方案,没种设计都各有优劣,如何选择设计依赖于应用程序中的哪种操作最需要性能上的优化:
邻接表是最方面的设计,并且很多开发中都了解它;
路径枚举能够很直观地展示出祖先与后代之间的路径,但同时由于它不能确保引用完整性,使得这个设计十分脆弱,
闭包表示通用的设计,它要求一个张额外的表来存储关系,使用空间换时间的方案减少操作过程中冗余的计算所造成的消耗。
当然还有其他的设计方案,没有最好的方案,只有最适合某个应用需求的方案,欢迎多多交流!















 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









