






匈牙利算法是基于Hall定理中充分性证明的思想【引用、真实性待查证】,它是部图匹配最常见的算法,该算法的核心是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。
交错树(alternating trees):不同于交错路径(好多地方都混淆了),是指rooted from未匹配点的所有路径都是交错路径的树。Root isY5

Definition 3.1([1]) 交错树是开始于$V$中一个未匹配点$r$($r\in V$),所有的连接线都从根节点向外发出,并且:
所有匹配边都是由$W$指向$V$,所有未匹配边都是有$V$指向$W$。
根节点是唯一一个未匹配点。
所有的叶子节点都是$V$集合的。
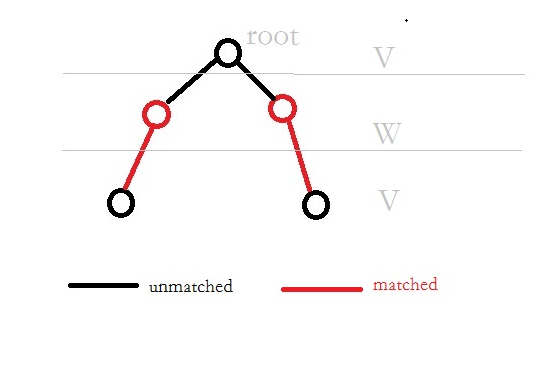
交错路径(alternating path):于P是图中的一条路,如果P中的边在匹配集合M和E-M集合之前切换,那么P就是一条交错路径。
(Y5-X6-Y6),(Y5-X4-Y4-X2-Y2-X1).
【1】理论比较规范的匈牙利算法的讲解说明:
【2】用比较诙谐幽默又易理解的方式讲解匈牙利算法本质的例子:
先看【2】容易抓住匈牙利算法的本质,【2】中作者说的就比较清楚,匈牙利算法最重要的理念就是“腾”(据我理解,这个‘腾’只适应于深度优先算法,广度优先则不然),然后通过【1】规范严谨算法。
以【1】中的图做例子:

自己在前面两篇博文的基础上,改写了C语言代码(如下)。
//Hungary算法
//数据输入格式
//第1行3个整数,V1,V2的节点数目n1,n2,G的边数m
//第2-m+1行,每行两个整数t1,t2,代表V1中编号为t1的点和V2中编号为t2的点之间有边相连
//输出格式:
//connect[a][i]:连接的变化情况
//最后的节点连接情况,即对应最大匹配的点的连接情况,以矩阵的形式表示
//1个整数ans,代表最大匹配数
#include
#include
int n1,n2,m,ans,dd;
int result[101]; //记录V2中的点匹配的点的编号
bool state [101]; //记录V2中的每个点是否被搜索过
bool data[101][101];//邻接矩阵 true代表有边相连
bool connect[101][101];//记录最后的匹配图
//
//init()函数是数据录入函数
void init() {
int t1,t2;
memset(data,0,sizeof(data));
memset(result,0,sizeof(result));
ans = 0;
scanf("%d%d%d",&n1,&n2,&m);
for (int i = 1; i <= m; i++) {
scanf("%d%d",&t1,&t2);
data[t1][t2] = true;
}
return;
}
bool find(int a) {
for (int i = 1; i <= n2; i++) {
if (data[a][i] == 1 && !state[i]) { //如果节点i与a相邻并且未被查找过
state[i] = true; //标记i为已查找过
//printf("%ld\n",find(result[i]));//输出
if (result[i] == 0 //如果i未在前一个匹配M中
|| find(result[i])) { //i在匹配M中,但是从与i相邻的节点出发可以有增广路//这里用的递归,关键是一个字就是“腾”,前面的匹配给后边的“腾”连接。
result[i] = a; //记录查找成功记录
for (dd = 1; dd <= n2; dd++){
connect[a][dd]=0;
}
connect[a][i]=1;//记录点集V2中i与V1中点集的连接情况,点i与点a连接
printf("%ld,%ld,%ld\n",connect[a][i],a,i);//输出与点i连接的V1中的点a
return true; //返回查找成功
}
}
}
return false;
}
int main() {
init();
for (int i = 1; i <= n1; i++) {
memset(state,0,sizeof(state)); //清空上次搜索时的标记
if (find(i)) ans++; //从节点i尝试扩展
}
//这部分是为了输出最后的分配情况
for (int x = 1; x <= n1; x++){
for (int y = 1; y<=n2; y++){
printf("%ld",connect[x][y]);
}
printf("\n");
}
/
printf("%d\n",ans);
return 0;
}
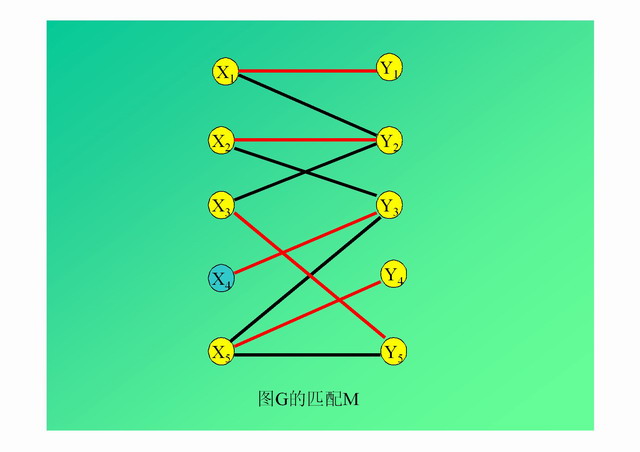
在图G的基础上代码运行输入形式(描述了节点之间的连接关系)为:
5 5 10
1 1
1 2
2 2
2 3
3 2
3 5
4 3
5 3
5 4
5 5
输出形式为:
1,1,1
1,2,2
1,2,3
1,3,2
1,3,5
1,2,2
1,4,3
1,5,4
10000
01000
00001
00100
00010
5
其中,前8行为算法运行过程中连接的变化情况,中间5行代表了算法运行结果,最大匹配所对应的连接情况以矩阵的形式表示,对应下图图G的匹配M,最后的数字5为匹配数量。
参考文献:
[1]Burkard R E, Çela E. Handbook of Combinatorial Optimization[M]. Springer US, 1999:75-149.















 1340
1340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









