






一:查看当前表有哪些索引?
Sql Server : sp_helpindex 表名
My Sql : show index from 表名 show keys from 表名
二:创建索引
普通索引:
Sql Server And My Sql
CREATE INDEX stu_name_index ON 表名 (字段)
联合索引:
My Sql :create index 索引名 on storecodeinfo (字段,字段)
删除索引
Sql Server and MySql
DROP INDEX 索引名 ON 表
索引类型
Sql Server:
唯一索引 unique : 不允许两行有相同的索引值
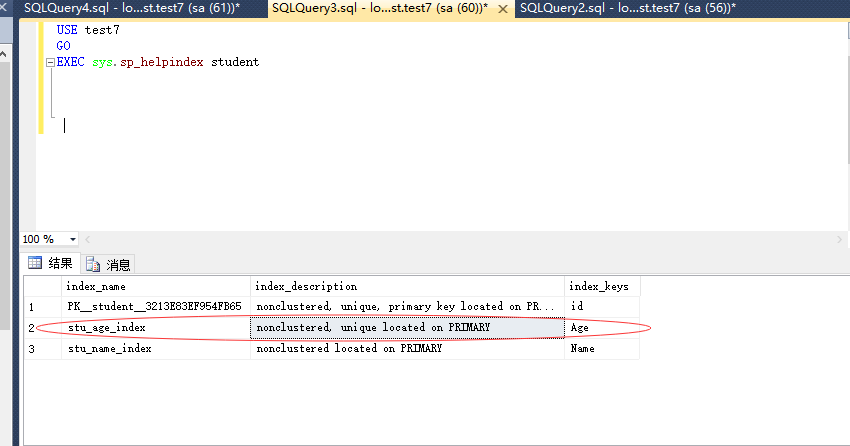
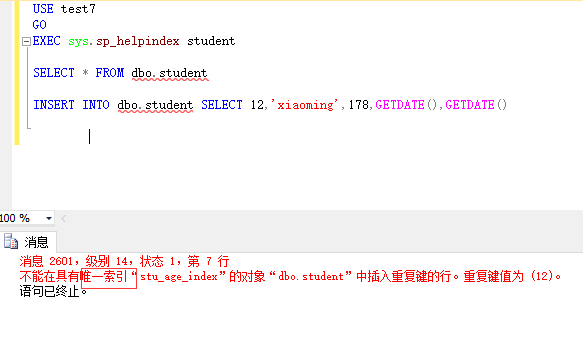
聚集索引(Clustered):表中各行的物理顺序与键值的逻辑(索引)顺序相同,每个表只能有一个聚集索引。
表中主键默认的是聚集索引,也可以将主键设置为非聚集索引
CREATE TABLE person(
id INT IDENTITY NOT NULL,
Age INT NOT NULL,
CONSTRAINT pk_person PRIMARY KEY NONCLUSTERED (id)
)//将主键设置为非聚集索引

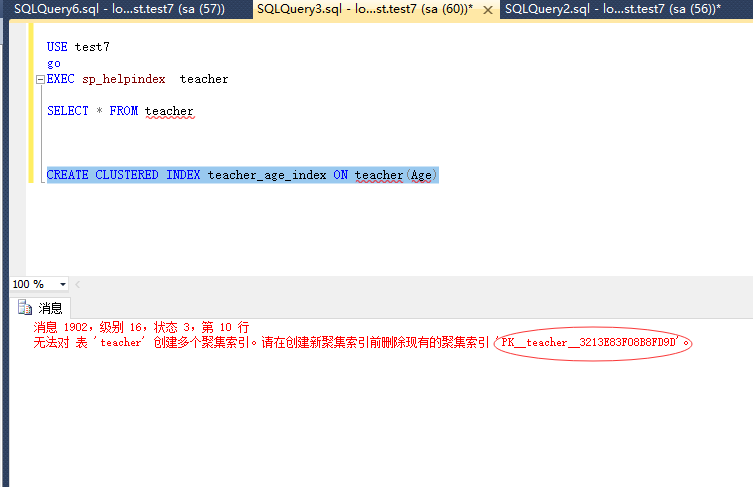
非聚集索引
按照查询快慢排序
[Table Scan] 表扫描(最慢),对表记录逐行进行检查
[Clustered Index Scan] 聚集索引扫描(较慢),按聚集索引对记录逐行进行检查
[Index Scan] 索引扫描(普通),根据索引滤出部分数据在进行逐行检查
[Index Seek] 索引查找(较快),根据索引定位记录所在位置再取出记录
[Clustered Index Seek] 聚集索引查找(最快),直接根据聚集索引获取记录
复合索引
当查询条件比较多的时候需要对where 后面条件创建索引来提高查询速度。
注意一点:查询的时候尽量按照复合索引中的顺序来做条件查询,高选择性的列放入到最左边,最多能包含16个字段
代码如下
//首先创建一张表
CREATE TABLE Teacher(
Id INT PRIMARY KEY IDENTITY NOT NULL,
Age INT NOT NULL,
Name NVARCHAR(50) NOT NULL,
Height INT NOT NULL,
CreateTime DATETIME DEFAULT GETDATE(),
ModifyTime DATETIME NOT NULL
)//随机插入10万2条数据
DECLARE @Id INT,@Name NVARCHAR(50),@Height INT
SET @Id=1SET @Name='xiaoming'SET @Height=165WHILE @Id<100000BEGIN
INSERT INTO dbo.Teacher
( Age ,
Name ,
Height
)
VALUES (CASE WHEN @Id>120 THEN 120 ELSE @Id END, -- Age - intCAST(@Id AS NVARCHAR(50))+@Name, -- Name - nvarchar(50)
CASE WHEN (CAST(@Id AS INT)+@Height)>250 THEN 250 ELSE CAST(@Id AS INT)+@Height END
)
SET @Id=@Id+1END
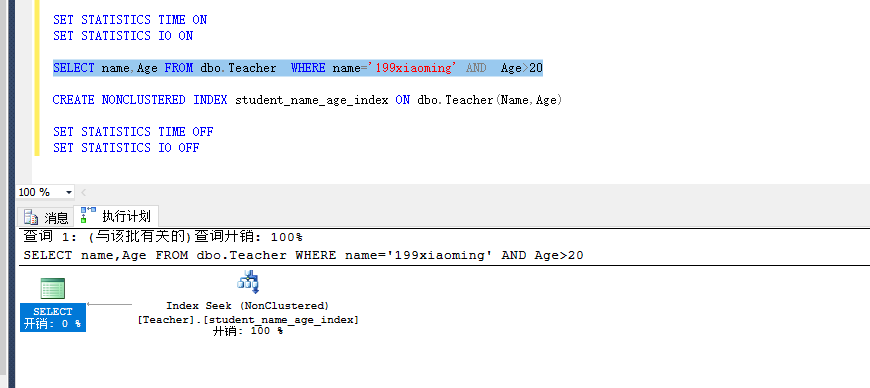
查询姓名为 199xiaoming 年龄 大于30岁
第一种情况:没有创建任何索引
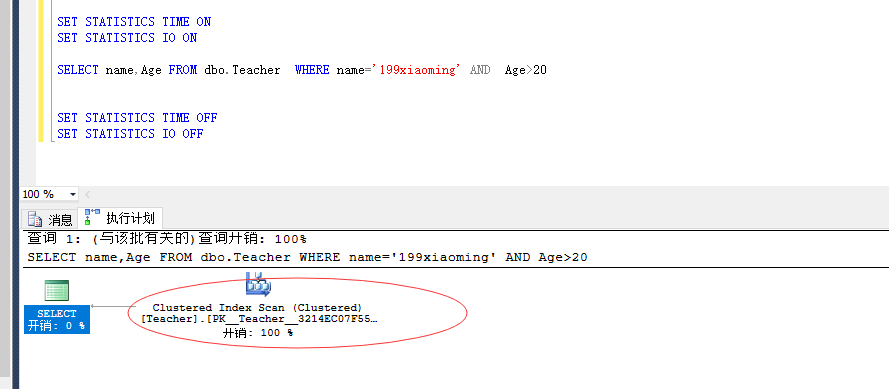
SELECT name,Age FROM dbo.Teacher WHERE name='199xiaoming' AND Age>20结果是:聚集索引扫描
第二种情况:创建复合索引
CREATE NONCLUSTERED INDEX student_name_age_index ON dbo.Teacher(Name,Age)
结果是:非聚集索引查找
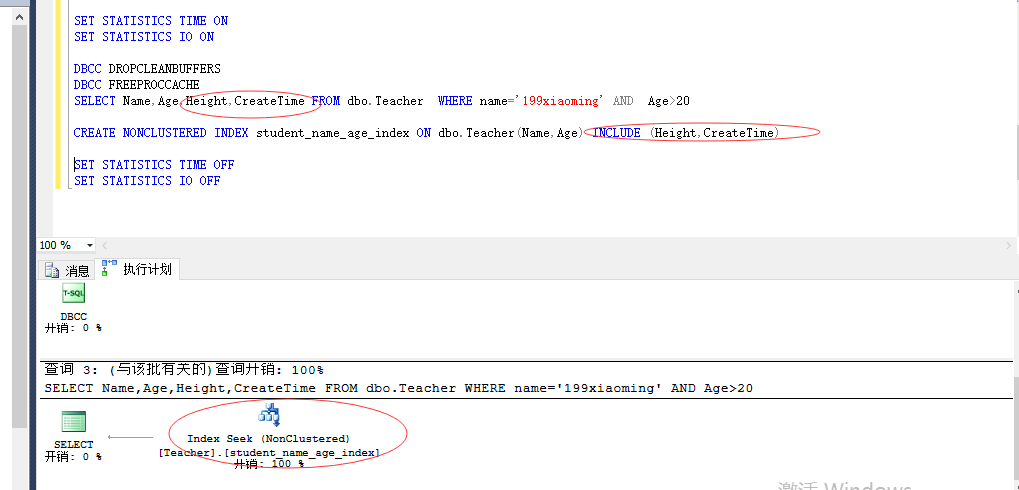
覆盖索引
注意:1.只有非聚集索引才能建立覆盖索引
2.不能在Include 中添加别名,别名不能重复
3. where后面的条件查询的字段作为索引的键列,而需要返回的字段就作为索引包含的非键列。
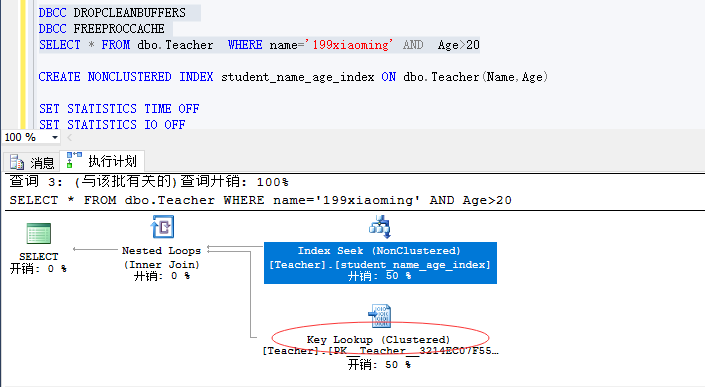
比如返回的列或查询条件中的列只部分包含在使用的非聚集索引,就需要一个查找(lookup)来检索其他字段来满足请求,对于有聚集索引的表来说会走键查找,非聚集索引会走书签查询,堆表会走RID查找,说了就是你使用的sql查询条件和select返回的列没有完全包含在索引列中时就会发生书签查找,为了优化当前查询,需要将当前的列被索引覆盖。
如下图所示:没有将返回的列包含在索引中,sql server 走 键查找和索引查找
优化如下:















 1478
1478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









