







 本文介绍了在处理大量数据时,如何通过改进查询方式提高效率。传统的遍历List方法在数据量大时效率低下,文章提出了一种新方法,利用哈希表对数据进行预处理和归类,从而实现快速定位指定数据。通过对比,新方法在查询耗时上有显著优势,尤其适用于需要频繁根据特定条件提取数据的场景。
本文介绍了在处理大量数据时,如何通过改进查询方式提高效率。传统的遍历List方法在数据量大时效率低下,文章提出了一种新方法,利用哈希表对数据进行预处理和归类,从而实现快速定位指定数据。通过对比,新方法在查询耗时上有显著优势,尤其适用于需要频繁根据特定条件提取数据的场景。
时间:2017/5/15
作者:李国君
题目:快速查询List中指定的数据
背景:当List中保存了大量的数据时,用传统的方法去遍历指定的数据肯定会效率低下,有一个方法就是类似于数据库查询那样,根据索引直接提取数据。
项目中遇到的软件卡顿的现象,其中一部分原因是因为数据量大的原因,所以有必要提高数据查询的速度。
这里先展示一下模拟的的方法:假设List集合中有500000个点,每个点都有他的属性值xIndex(x坐标),yIndex(y坐标),text(描述),相当于10000*50的矩阵(10000列,50行),
(1,1) (xIndex,yIndex)
(2,1)
(3,1)
(。。。,。。。)
(1,2)
(2,2)
(3,2)
(。。。,。。。)
(1,3)
(2,3)
(3,3)
(。。。,。。。)
(。。。,。。。)
(。。。,。。。)
(。。。,。。。)
(10000,50)
然后,当我们知道某一xIdex后,想要提取满足当前xIdex的所有行的数据(text属性值),先看效果:
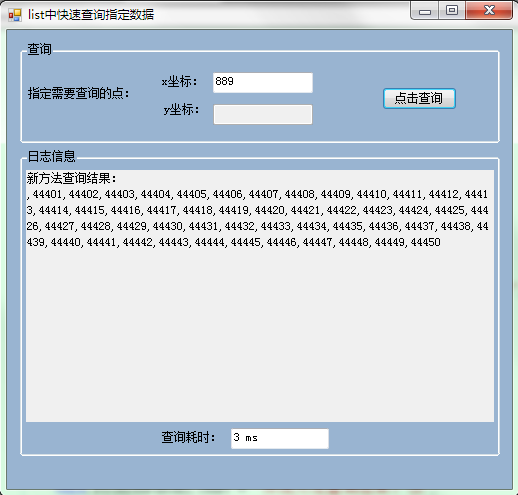
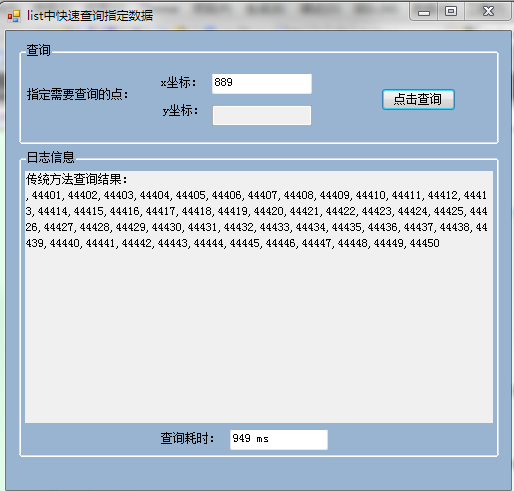


从查询耗时对比可以看出鲜明的对比。
方法介绍:
1.传统的方法就是直接遍历List集合:
//传统遍历
var objPoints = from b in listPoints where b.xIndex == Convert.ToInt32(this.tbX.Text.Trim().ToString()) select b;
foreach (var item in objPoints)
{
showPoints(item); //显示当前点的text属性值;
}
这种遍历在数据量较少时很好用,简单明了,可是当数据量较大时,它的效率就会大打折扣,原因在于我们遍历了所有的数据,对我们没有用的数据也会逐个遍历,所以效率会降低。
2.新方法是先将所有点的进行“归类”,将相同xIdex的点进行归类,归类的方法如下:
hsTemp.Clear();//清空哈希表
int Tem
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1033
1033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









