







数据库的基本操作1-数据查询
此处以普通用户hr/hr中的相关数据表进行分析
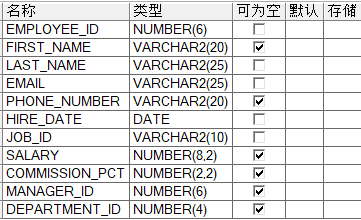
查询数据(基本查询)
1.1 查询(select .. form ..)
基本语法

简单查询(全部列与指定列)
选择全部列
--查询所有的列:select * from 表名;
select *
from employees 选择特定的列
--查询指定的列,不同的列之间用,号隔开:select [列名1,列名2...] from 表名;
select employee_id,first_name
from employees使用数学运算符

乘除的优先级高于加减
- 优先级相同时,按照从左至右运算
- 可以使用括号改变优先级
--使用数学运算符进行计算:(用列名代替运算,表示对应列的数据参与运算)
select employee_id,first_name,salary,salary+500
from employees空值(null)与对空值的处理
- 空值是无效的、是未指定的、是未知的、是不确定的
- 空值不是空格”” 也不是0
- 包含空值的数学表达式都是空值
--由于commission_pct列部分数据为空值,则其参与表达式计算得出的值也是空值
select employee_id,first_name,last_name,salary*(1+commission_pct)*12
from employees列的别名
- 重命名一个列(给一个列起别名)
- 便于计算
- 紧跟在列名之后,加入关键字’as’ 其中as关键字可以省略
--工资增加500后进行打印
select employee_id,first_name,last_name,salary,salary+500 as newSalary
from employees使用连接符(连接字符串或列)
连接符:
- 把“列与列之间”或者“列与字符之间”联系在一起
- 用’|| ’ 表示
- 可以’合成 ’列(用指定列合成指定的字符串形式)
--将名与姓之间以空格相连
select employee_id,first_name || ' ' || last_name as name,salary
from employees对字符串的处理
- 字符串可以是select列表中的一个字符、数字、或者日期
- 日期和字符只能出现在单引号中出现
- 每当返回一行时,字符串被输出一次
--对字符串的处理(合并相关列,打印一行数据作为新的列)
select first_name || ' is_a ' || last_name as sname,email,salary
from employees删除重复的行
--删除重复的行:distinct关键字
select distinct department_id
from employees1.2 过滤(Where)
语法

--查询department_id为30
select employee_id,first_name,last_name,department_id
from employees
where department_id=30处理字符串与日期
- 字符和日期要包含在单引号之内
- 字符大小写敏感 日期格式也是敏感的
- 默认日期格式是DD-MON-RR
--查询first_name = 'lex'的员工信息
--字符串严格区分大小写,如果是‘lex’则无相关员工信息
select employee_id,first_name,last_name
from employees
where first_name = 'Lex'1.3 比较运算
简单运算符
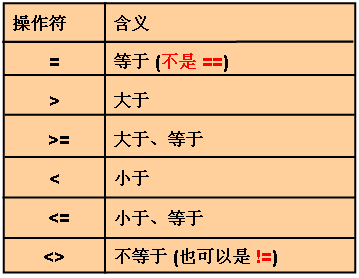
--比较运算符的应用
--查询员工的工资、小于等于3000的所有员工的具体信息
select employee_id,first_name,salary
from employees
where salary<=3000其他运算符

BETWEEN
--between...and... 表示数据在什么范围中之间
--查询工资在4000-7000之间的所有员工信息
select employee_id,first_name,salary
from employees
where salary between 4000 and 7000IN
--in关键字表示数据在指定的范围内(指定的内容中)
--查询员工部门号在90-100-110之内的所有员工的信息
select employee_id,first_name,department_id
from employees
where department_id in (90,100,110)LIKE
- 使用like运算是选择类似的值
- 选择条件可以包含数字和字符
- %代表零个或者多个字符(任意个字符)
- _带表一个字符
-- like 关键字表示选择类似的值
-- 下划线_表示单个字符、百分号%表示任意个字符
--查询first_name 包含an的所有的员工信息
select employee_id,first_name,last_name
from employees
where first_name like '%an%'
--查询第first_name以Da开头的所有员工信息
select employee_id,first_name,last_name
from employees
where first_name like 'Da%'
--查询第1个字符任意、第2个字符是oh、第3个字符任意的所有员工信息
select employee_id,first_name,last_name
from employees
where first_name like '_oh%'1.4 对空值(null)的处理
--对空值null的处理(判断是否为空值用is null进行判断)
--注意的是“=null”、“=‘ ’”均是不合理的判断为空的操作sql
--查询没有部门的员工
select employee_id,first_name||' '||last_name as name,department_id
from employees
where department_id is null
--查询公司boss(manager_id为空值的对应人员)
select employee_id,first_name||' '||last_name as name,manager_id
from employees
where manager_id is null1.5 逻辑运算

AND
-- and 要求两个条件同时满足(为真)
--查询工资大于10000且job_id包含MAN的所有员工
select employee_id,last_name || ' ' || first_name as name,salary,job_id
from employees
where salary>10000 and job_id like '%MAN%'OR
-- or 要求其中任意一个条件满足即可(为真)
--查询工资大于10000或者job_id包含MAN的所有员工
select employee_id,last_name || ' ' || first_name as name,salary,job_id
from employees
where salary>10000 or job_id like '%MAN%'NOT
-- not 取非
--查询员工的job_id不在AD_VP,FI_MGR,ST_MAN中的所有员工
select employee_id,first_name,last_name,job_id
from employees
where job_id not in ('AD_VP','FI_MGR','ST_MAN')1.6 优先级

- 可以使用括号改变优先级顺序,不需要死记硬背相关的比较级顺序,掌握最基本的即可
2.排序
2.1语法
- 使用oreder by 子句排序
- ASC 升序排序 (ASC是默认的排序方式,可以省略)
- DESC 降序排序
- Order by子句是在select语句的结尾处
- 排序规则:
- 可以按照select语句的别名排序
- 可以按照select语句中的列名的顺序排序
- 如果有多个列进行排序,则规则是先按照第一排序,如果第一列相同,则按照第二列排序,依次类推即可
--排序:使用rder by子句
--默认是升序排序asc、降序排序为desc
--按照雇佣日期进行升序排序
select employee_id,first_name,last_name,hire_date
from employees
order by hire_date
--按照工资高低进行降序排序
select employee_id,first_name,last_name,salary
from employees
order by salary desc2.2按别名排序
--按照年薪方式进行降序排序(此处直接为月工资*12,不考虑奖金)
select employee_id,first_name,last_name,(salary*12) as yearSal
from employees
order by yearSal desc2.3多个列排序
- 按照order by列表的顺序排序
- 可以使用不在select列表中的列排序
--按照部门编号进行升序排序,如果部门编号相同则按照工资进行降序排序
select employee_id,first_name,last_name,department_id,salary
from employees
order by department_id ,salary desc3.单行函数
3.1 单行函数说明
单行函数:
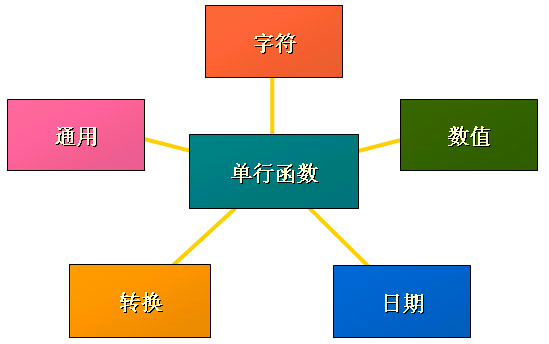
3.2 字符函数

大小写控制函数
- 这类函数用于改变字符的大小写

-- 此处的 dual 是一张万能表、虚表,能够提供任何数据
--大小写控制函数:LOWER小写、UPPER大写、INITCAP首字母大写
select LOWER('HAHAbIBU') from dual
select UPPER('hahabIBU') from dual
select INITCAP('haHAbIBU') from dual
select first_name
from employees
where LOWER(first_name) = 'lex'字符控制函数
- 这类函数用于控制字符

--7.2字符控制函数
/*
CONCAT(STR1,STR2):将STR2字符串数据拼接在STR1字符串之后
SUBSTR(STR,a,b):截取字符串STR从第a个字符开始往后截取b个字符(计数从1开始)
LENGTH(STR):取STR字符串的长度
INSTR(STR,CH):得到指定的CH(字符或是字符串)在STR中的位置,不存在则返回0
LPAD(STR,i,CH):在字符串STR左侧用字符CH填充字符串(总共位数为i)
RPAD(STR,i,CH):在字符串STR右侧用字符CH填充字符串(总共位数为i)
TRIM('H' FROM 'HelloWorld'):去除字符串首尾的空格或首尾的单个字符
replace(str,ch1,ch2):以ch2替换str中的ch1(ch1、ch2可为字符或者是字符串)
*/
/*
使用字符控制函数完成下述操作
1.将first_name与last_name进行拼接后作为sname输出
2.将job_id的长度作为len输出
3.获取字符a在last_name出现的位置后作为结果输出
4.在first_name左侧填充字符‘*’,总的位数为10位后输出
5.选择的条件是从job_id的第4个位置开始往后截取3个字符的结果为大写的‘rep’
*/
select employee_id,concat(first_name,last_name) as sname,
length(job_id) as len,instr(last_name,'a'),
lpad(first_name,10,'*'),job_id
from employees
where substr(job_id,4,3)=upper('rep');
--trim:去除字符串首尾的空格、也可去除指定的首部或者尾部的字符
select ' Hello World '
from dual
select trim(' Hello World ')
from dual
--截取掉的部分只能是一个字符
select trim('H' from 'Hello')
from dual
select trim('o' from 'Hello')
from dual
--replace:用给定字符(字符串)替换指定字符串的指定字符(字符串)
--如果字符串中没有指定字符则视为无效替换,返回原有的字符串
select replace('abcd','b','x')
from dual
select replace('abcd','s','x')
from dual
select replace('abcd','bc','xx')
from dual3.3 数字函数
- ROUND: 四舍五入
例:ROUND(45.926, 2) ,结果45.93
- TRUNC: 截断
例:TRUNC(45.926, 2) ,结果45.92
- MOD: 求余
例:MOD(1600, 300) ,结果100
/*
round(num,i):将数字num进行四舍五入,保留i位小数
trunc(num):将小数点之后的内容截断舍弃
trunc(num,i):小数点之前(i为负整数)或之后(i为正整数)第|i|位之后的内容 均以0记
mod(num1,num2):将num1对num2求余
*/
select round(36.973,2),round(36.966,2)
from dual --36.97 36.97
select trunc(36.973,2),trunc(36.973,-2),trunc(362.973,-2)
from dual --36.97 00.000-->0 300.000-->300
select mod(1000,300)
from dual --1003.4 日期
- Oracle 中的日期型数据实际含有两个值:日期和时间
- 默认的日期格式是 DD-MON-RR
根据操作系统的不同,需要使用不同的内容,如果是英文的系统使用DD-MON-RR
如果是中文的,可以使用汉字的年月日
日期的数学运算
- 在日期上加上或减去一个数字结果仍为日期
- 两个日期相减返回日期之间相差的天数
- 可以用数字除24来向日期中加上或减去小时
--获取系统当前的时间(日期)
select sysdate
from dual
--计算80号部门所有员工从入职到现在工作了多少周,按照工作时间进行降序排序
select employee_id,concat(last_name,first_name) as sname,department_id,
trunc((sysdate-hire_date)/8,2) as weeks,hire_date
from employees
where department_id = 80
order by weeks desc 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1091
1091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









