










命名实体识别问题可以看做是一个序列标注问题,传统的机器学习算法有三种方法做序列标注,分别是隐马尔科夫(HMM)模型,最大熵模型和条件随机场(CRF)模型。
https://blog.csdn.net/Losteng/article/details/51037927
HMM模型将标注看做马尔科夫链,一阶马尔科夫链针对相邻标注的关系进行建模,其中每个标记对应一个概率函数。HM是一种生成模型,定义了联合概率分布,其中x和y分别表示观察序列和相对应的标注序列的随机变量。为了能够定义这种联合概率分布,生成模型需要枚举出所有可能的观察序列,这在实际运算过程中很困难,因为我们需要将观察序列的元素看做是彼此孤立的个体即假设每个元素彼此独立,任何时刻的观察结果只依赖于改时刻的状态。
HMM模型的这个假设前提在较小的数据集上是合适的,但实际上在大量真实语料中观察序列更多的是以一种多重的交互特征形式表现,观察元素之间广泛存在长程相关性。在命名实体识别任务中,由于实体本身结构所具有的复杂性,利用简单的特征函数往往无法覆盖所有的特性,这时HMM的假设前提使得它无法使用复杂特征(无法使用多于一个标记的特征)。
最大熵模型可以使用任意的复杂相关特征,在性能上最大熵分类器超过了Byaes分类器。但是,作为一种分类器模型,这两种方法有一个共同的缺点:每个词都是单独进行分类的,标记之间的关系无法得到充分利用,具有马尔科夫链的HMM模型可以建立标记之间的马尔科夫关联性,这是最大熵模型所没有的。
最大熵模型的优点:首先,最大上统计模型获得的是所有满足约束条件的模型中信息熵极大的模型;其次,最大上统计模型可以灵活的设置约束条件,通过约束条件的多少可以调节模型对于未知数据的适应度和对已知数据的拟合程度;再次,它还能自然地解决统计模型中参数平滑的问题。
最大熵的不足:首先,最大熵统计模型中二值化特征只是记录特征是否出现,而文本分类需要知道特征的强度,因此,它在分类方法中不是最优的;其次,由于算法收敛速度较慢,所以导致最大熵统计模型的计算代价较大,时空开销大;再次,数据稀疏问题比较严重。
最大熵马尔科夫模型:把HMM模型和maximum-entropy模型的优点集合成一个生成模型,这个模型允许状态转移概率依赖于序列中彼此之间非独立的特征,从而将上下文信息引入到模型的学习和识别过程中,提高了识别的精确度,召回率也大大的提高。
CRF模型:首先,CRF在给定了观察序列的情况下,对整个的序列的联合概率有一个统一的指数模型,而且其损失函数是凸的。其次,CRF相比较改进的HMM模型可以更好更多的利用待识别文本中所提供的上下文信息以得到更好的实验结果。CRF中中文组块识别方面有效,并避免了严格独立性假设和数学归纳偏置问题。CRF模型应用到中文命名实体识别中,并根据中文的特点,定义了多种特征模板。并且有测试结果表明,在采用相同特征集合的条件下,CRF模型较其他概率模型有更好的性能表现。再次,词性标注主要面临类词消歧以及未知词标注的难题,传统HMM方法不易融合新特征,而最大熵马尔科夫模型存在标注偏置问题。相比之下,CRF模型易于融合新的特征,并能解决标注偏置问题。
CRF具有很强的推理能力,并且能够使用复杂、有重叠性和非独立的特征进行训练和推理,能够充分地利用上下文信息作为特征,还可以任意地添加其他外部特征,使得模型能够获得地信息非常丰富。同时,CRF解决了最大熵模型中地‘label bias’问题。CRF与最大熵模型本质区别是:最大熵模型在每个状态都有一个概率模型,在每个状态转移时都要进行归一化。如果某个状态只有一个后续状态,那么该状态到后续状态地跳转概率为1.这样,不管输入为任何内容,它都向后续状态跳转。而CRF是在所有地状态上建立一个统一的概率模型,这样在进行归一化时,即使某个状态只有一个后续状态,它到该后续状态地跳转概率也不为1,从而解决了’label bias’问题。因此,理论上讲,CRF非常适用于中文地词性标注。
CRF的优点:首先,CRF模型由于自身在结合多种特征方面的优势和避免了标记偏置问题;其次,CRF的性能更好,CRF的特征融合能力比较强,对于实例较小的时间类ME来说,CRF的识别效果明显高于ME的识别结果。
CRF的缺点:
首先,通过对基于CRF的结合多种特征的方法识别英语命名实体的分析,发现在使用CRF方法中,特征的选择和优化是影响结果的关键因素,特征选择问题的好与坏,直接决定了系统性能的高低。其次,训练模型的时间比ME更长,且获得的模型很大,在一般的PC机上无法运行。
深度学习模型效果比较好的是双向LSTM+CRF。
(1)为什么使用Bi_LSTM? 为了使特征提取自动化。当使用CRF++工具来进行命名实体识别时,需要自定义模板(或者使用默认的模板)。
(2)为什么我们不直接把所有的地点,常见姓名和组织名保存成一个列表呢?是因为有很多实体,例如姓名和组织名是人为构造的,而怎么构造,没有先验知识。所以,需要能够从句子中提取出上下文信息的工具。
(3)模型介绍
模型分为3部分:
1.词表示。使用紧密(dense)向量表示每个词,加载预训练好的词向量(glove,word2vec,senna等)。也将从单个字(单个字母)中提取一些含义。为什么也需要单个字呢?因为很多实体没有预训练好的向量,而且开头是大写字母会对识别出实体有用。
2.上下文单词表示。对上下文中的每个词,需要有一个有意义的向量表示,使用LSTM来获取上下文中单词的向量表示。
3.解码。当我们有每个词的向量表示后,来进行实体标签的预测。
词向量表示
对于每个词,需要构建一个向量来获取这个词的意思以及对实体识别有用的一些特征,这个向量由Glove训练的词向量和从字母提取出的特征的向量堆叠而成。
一种选择是使用手动提取的特征,例如单词是否是大写字母开头等,另一种更好的选择是使用某种神经网络来自动提取特征。在这里,对单词字母使用Bi_LSTM,当然也可以使用其他循环神经网络,或者对单个字母或n-gram使用cnn.
组成一个单词的每个字母都由一个向量表示(注意区分大小写),对每个字母使用Bi-LSTM,并将最后状态堆叠起来获得一个固定长度的向量。直觉上,这个向量获取了这个词的形态,然后将词向量和字母向量合并,获得这个词最终的向量表示。
tensorflow处理批量的词和数据,因此需要将句子填充到相同的长度,定义2个placeholder:
# shape = (batch size, max length of sentence in batch)
word_ids = tf.placeholder(tf.int32, shape=[None, None])
# shape = (batch size)
sequence_lengths = tf.placeholder(tf.int32, shape=[None])
使用tensorflow内置的函数来加载词向量。假设embeddings是保存这Glove向量的数组,那么embeddings[i]就是第i个单词的词向量。
L = tf.Variable(embeddings, dtype=tf.float32, trainable=False)
# shape = (batch, sentence, word_vector_size)
pretrained_embeddings = tf.nn.embedding_lookup(L, word_ids)
接下来构建单个字母的标书,对词也需要填充到相同的长度,定义2个placeholder:
# shape = (batch size, max length of sentence, max length of word)
char_ids = tf.placeholder(tf.int32, shape=[None, None, None])
# shape = (batch_size, max_length of sentence)
word_lengths = tf.placeholder(tf.int32, shape=[None, None])
为什么到处都使用None?为什么我们需要使用None?
这取决于我们如何填充,在这里,选择动态填充,例如在一个batch中,将batch中的句子填充到这个batch的最大长度。因此,句子长度和词的长度取决于这个batch。
接下来构造字母向量(character embeddings)。我们没有预训练的字母向量,使用tf.get_variable来初始化一个矩阵。然后改变这个4维tensor形状来满足bidirectional_dynamic_rnn的输入要求。
sequence_length这个参数使我们确保我们获得的最后状态是有效的最后状态(因为batch中句子的实际长度不一样)。
# 1. get character embeddings
K = tf.get_variable(name="char_embeddings", dtype=tf.float32,
shape=[nchars, dim_char])
# shape = (batch, sentence, word, dim of char embeddings)
char_embeddings = tf.nn.embedding_lookup(K, char_ids)
# 2. put the time dimension on axis=1 for dynamic_rnn
s = tf.shape(char_embeddings) # store old shape
# shape = (batch x sentence, word, dim of char embeddings)
char_embeddings = tf.reshape(char_embeddings, shape=[-1, s[-2], s[-1]])
word_lengths = tf.reshape(self.word_lengths, shape=[-1])
#3 bi lstm on chars
cell_fw = tf.contrib.rnn.LSTMCell(char_hidden_size,state_is_tuple=True)
cell_bw = tf.contrib.rnn.LSTMCell(char_hidden_size,state_is_tuple=True)
_,((_,outout_fw),(_,output_bw)) = tf.nn.bdirectional_dynamic_rnn(cell_fw,cell_bw,char_embeddings,sequence_length=word_lengths,dtype=tf.float32)
#shape = (batch * sentence, 2*char_hidden_size)
output = tf.concat([output_fw,output_bw],axis=1)
#shape = (batch,sentence,2*char_hidden_size)
char_rep = tf.reshape(output,shape = [-1, s[1], 2*char_hidden_size])
#shape = (batch,sentence,2*char_hidden_size+word_vector_size))
word_embeddings = tf.concat([pretrained_embeddings, char_rep], axis=1)
上下文单词表示
当我们得到词最终的向量表示后,对词向量的序列进行LSTM或Bi_LSTM.
使用每个时间的隐藏状态,而不仅仅是最终状态。输入m个词向量,获得m个隐藏状态的向量,然而词向量只是包含词级别的信息,而隐藏状态的向量考虑了上下文。
cell_fw = tf.contrib.rnn.LSTMCell(hidden_size)
cell_bw = tf.contrib.rnn.LSTMCell(hidden_size)
(output_fw, output_bw), _ = tf.nn.bidirectional_dynamic_rnn(cell_fw,
cell_bw, word_embeddings, sequence_length=sequence_lengths,
dtype=tf.float32)
context_rep = tf.concat([output_fw, output_bw], axis=-1)
解码
在解码阶段计算标签得分,使用每个词对应的隐藏状态向量来做最后预测,可以使用一个全连接神经网络来获取每个实体标签的得分。
其中s[i]可以理解为词w对应标签i的得分。
W = tf.get_variable("W", shape=[2*self.config.hidden_size, self.config.ntags],
dtype=tf.float32)
b = tf.get_variable("b", shape=[self.config.ntags], dtype=tf.float32,
initializer=tf.zeros_initializer())
ntime_steps = tf.shape(context_rep)[1]
context_rep_flat = tf.reshape(context_rep, [-1, 2*hidden_size])
pred = tf.matmul(context_rep_flat, W) + b
scores = tf.reshape(pred, [-1, ntime_steps, ntags])
对标签得分进行解码,有两个选择。不管哪个选择,都会计算标签序列的概率并找到概率最大的序列。
1.softmax:将得分转化为代表这个单词属于某个类别标签)的概率,概率和为1。最后,标签序列的概率是每个位置标签概率的乘积。
2.线性CRF:softmax方法是做局部选择,换句话,即使Bi_LSTM产生的h中包含了一些上下文信息,但是标签决策仍然是局部的,没有利用周围的标签来帮助决策。
线性CRF定义了全局得分C:
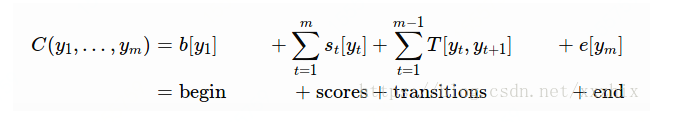
其中,T是ntags * ntags的转换矩阵,e,b是ntags维的向量,表示某个标签作为开头和结尾的成本。T包含了标签决策内的线性依赖关系,下一个标签依赖上一个标签。举例如下:

如果单看每个位置的得分,标签序列PER-PER-LOC的得分(10+4+11)比PER-O-LOC的得分(10+3+11)高,但如果考虑标签之间的依赖关系,PER-O-LOC的得分(31)高于PER-PER-LOC的得分(26),而Pierre loves Paris的标签序列是PER-O-LOC。
要实现CRF计算得分,需要做2件事:
1.找到得分最高的标签序列
2.计算所有标签序列的概率分布?
要找到得分最高的标签序列,不可能计算所有的
n
t
a
g
s
m
ntags^m
ntagsm个标签得分,并甚至将每个标签得分标准化为概率,其中m是句子的长度。使用动态方法找到得分最高的序列,假设有从t+1,…,m的序列得分,那么从t,…,m的序列得分是:

每个循环步骤的复杂度是O(ntags*ntags),共m步,则总的复杂度是O(ntags*ntags*m),对于一个10个词的句子来说,复杂度从
n
t
a
g
s
1
0
ntags^10
ntags10,下降到ntags*ntags*10
线性链CRF的最后一步是对所有可能序列的得分执行softmax,从而得到给定序列的概率。
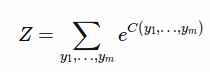 所有可能序列得分的和。
所有可能序列得分的和。
Z
t
(
y
t
)
Z_t(y_t)
Zt(yt)是在时间t,标签为
y
t
y_t
yt的所有序列得分的和。(为什么定义这个值?为了对Z进行递归计算,减少计算量)

则给定标签序列的概率是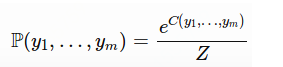
使用交叉熵损失函数作为目标函数进行训练,交叉熵损失定以为:

以下代码计算损失并返回转移矩阵T,计算CRF的对数概率只需要一行代码:
# shape = (batch, sentence)
labels = tf.placeholder(tf.int32, shape=[None, None], name="labels")
log_likelihood, transition_params = tf.contrib.crf.crf_log_likelihood(
scores, labels, sequence_lengths)
loss = tf.reduce_mean(-log_likelihood)
直接使用softmax后计算损失时,要注意padding,使用tf.sequence_mask来将序列长度转换成是否向量。
losses = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=scores, labels=labels)
# shape = (batch, sentence, nclasses)
mask = tf.sequence_mask(sequence_lengths)
# apply mask
losses = tf.boolean_mask(losses, mask)
loss = tf.reduce_mean(losses)
之后定义训练操作:
optimizer = tf.train.AdamOptimizer(self.lr)
train_op = optimizer.minimize(self.loss)
当训练好模型之后,如何使用模型进行预测?
当直接使用softmax时,最好的序列就是在每个时间点选择最高得分的标签,用以下代码实现:
labels_pred = tf.cast(tf.argmax(self.logits, axis=-1), tf.int32)
当使用CRF时,需要动态编程,但也只需要一行代码:
# shape = (sentence, nclasses)
score = ...
viterbi_sequence, viterbi_score = tf.contrib.crf.viterbi_decode(
score, transition_params)
补充一个问题:
为什么LSTM之后可以接CRF?
当没有使用深度学习提取特征之前,输入CRF的是自定义的特征,满足特征,则得分为1,不满足,则得分为0.CRF可以看作当前位置的特征得分和标签转移的特征得分的得分和,然后选整个序列得分高的。
直接把LSTM输出的拼接起来的词向量和句向量拼接起来应该如何理解?
从LSTM输出的向量相当于定义在节点上的特征函数,也就是上文中的 ,就是看当前词对标签结果的影响。但LSTM每个位置输出的向量的维度和标签个数一般是不一样的,标签个数远远小于输出向量的维度。
,就是看当前词对标签结果的影响。但LSTM每个位置输出的向量的维度和标签个数一般是不一样的,标签个数远远小于输出向量的维度。
在CRF解码时,tf.contrib.crf.veterbi_decode()是需要另外传入transition_params参数的,就是底层的神经网络没有学习到转移的特征函数。
https://blog.csdn.net/xxzhix/article/details/81514040















 5037
5037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









