







时间:2019.4.3
地点:武汉
状态:离职在家
今天天气很好,阳光照射到绿叶上,一片兴兴向荣。不谈未来职业规划,不论工作面试准备,抛去这些让人疲惫的东西,突然想回归到纯粹知识的本质之中。
问题的开端:
复兴的深度学习让人们试图用计算机模拟人类的感知,认知,决策和自我学习能力。计算机能处理的东西只有数字,所以我们第一步是要把现实世界的东西用数字尽可能的描述出来。比如:一张图可以表示成三维(长,寛,通道数(RGB)),而对于文字而言,如何用数字描述一段文本场景下的字,词,句子,甚至是整幅篇章,这是nlp的一个热门研究领域。word-embedding乃方法之一。
想法的起源:
举个例子作为引子:如何定义“人”?《马克思恩格斯选集》中说道:“人的本质是一切社会关系的总和”。人脱离了社会关系无法体现其意义,同理,词(字等类似)也可以参照这个思路,即:使用词的上下文来表示其含义(基于一种分布假说理论,上下文相似的词,其语义也相似)。
emmm,于是,现在问题变成了,我们需要定义一种词表示模型来描述其上下文(即描述词的本身)
(1)基于矩阵的分布表示
LSA,GLOVE等。
(2)基于聚类的分布表示
略
(3)基于神经网络的分布表示
我们来重点讨论基于神经网络的分布表示。代表算法:word2vec(skip-gram,cbow),elmo,gpt,bert。
相较于前者,这类算法的最大优势:可以用来表达复杂的上下文。(本质区别:不在统计词频,而是用模型拟合的方式逼近真实的分布)
其实,基于NN的所有方法都是在训练语言模型(LM)的同时,顺便得到词向量的。
语言模型:
那么什么是语言模型任呢?

语言模型通常构建为字符串s的概率分布p(s),这里的p(s)实际上反映的是s作为一个句子出现的概率。
这里的概率指的是组成字符串的这个组合,在训练语料中出现的似然,与句子是否合乎语法无关。假设训练语料来自于人类的语言,那么可以认为这个概率是的是一句话是否是人话的概率。
对于一个由T个词按顺序构成的句子,p(s)实际上求解的是字符串
的联合概率,利用贝叶斯公式,链式分解如下:
从上面可以看到,一个统计语言模型可以表示成,给定前面的的词,求后面一个词出现的条件概率。
如何求解上述问题呢?
(1)自由参数数目:
假定字符串中字符全部来自与大小为V的词典,上述例子中我们需要计算所有的条件概率,对于所有的条件概率,这里的w都有V种取值,那么实际上这个模型的自由参数数目量级是V^6,6为字符串的长度。
从上面可以看出,模型的自由参数是随着字符串长度的增加而指数级暴增的,这使我们几乎不可能正确的估计出这些参数。
(2)数据稀疏性:
从上面可以看到,每一个w都具有V种取值,这样构造出了非常多的词对,但实际中训练语料是不会出现这么多种组合的,那么依据最大似然估计,最终得到的概率实际是很可能趋近于0。
为了解决传统语言模型的问题,提出n-gram语言模型与神经网络语言模型
n-gram语言模型:
重点-引入了马尔科夫假设,即:随意一个词出现的概率只与它前面出现的有限的n个词有关。其他计算类似,
n=1,一元语言模型
n=2,一阶马尔科夫链,此时自由参数数量级是V^2
n=3,即一个词的出现仅与它前面的两个词有关,叫三元语言模型,也叫二阶马尔科夫链,此时自由参数数量级是V^3
N-gram语言模型的求解跟传统统计语言模型一致,都是求解每一个条件概率的值,简单计算N元语法在语料中出现的频率,然后归一化
我们在传统统计语言模型提出了两个问题:自由参数数目和数据稀疏,上述N-gram只是解决了第一个问题,而平滑化就是为了解决第二个问题。
假设有一个词组在训练语料中没有出现过,那么它的频次就为0,但实际上能不能认为它出现的概率为0呢?显然不可以,我们无法保证训练语料的完备性。那么,解决的方法是什么?如果我们默认每一个词组都出现1次呢,无论词组出现的频次是多少,都往上加1,这就能够解决概率为0的问题了。
上述的方法就是加1平滑,也称为拉普拉斯平滑。
n-gram缺陷:
- 无法建模更远的关系。
- 无法建模出词之间的相似度。
- 训练语料里面有些 n 元组没有出现过,其对应的条件概率就是 0,导致计算一整句话的概率为 0。解决这个问题有两种常用方法: 平滑法和回退法。
神经网络语言模型:

学习任务是输入某个句中单词 前面句子的t-1个单词,要求网络正确预测单词Bert,即最大化:
前面任意单词 用Onehot编码作为原始单词输入,之后乘以矩阵Q后获得向量
,每个单词的
拼接,上接隐层,然后接softmax去预测后面应该后续接哪个单词。这个
是什么?这其实就是单词对应的Word Embedding值,那个矩阵Q包含V行,V代表词典大小,每一行内容代表对应单词的Word embedding值。只不过Q的内容也是网络参数,需要学习获得,训练刚开始用随机值初始化矩阵Q,当这个网络训练好之后,矩阵Q的内容被正确赋值,每一行代表一个单词对应的Word embedding值。通过这个网络学习语言模型任务,这个网络不仅自己能够根据上文预测后接单词是什么,同时获得一个副产品,就是那个矩阵Q,即单词的Word Embedding。
公式如下:
输入层:

隐层:

输出层:
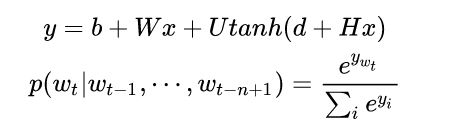
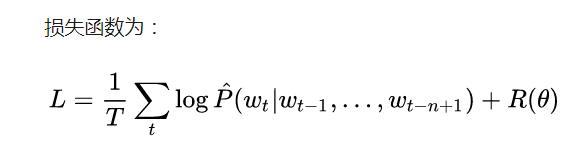
接下篇见word2vec
















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











