






4.3 启动及验证
1)格式化HDFS文件系统
在"Master.Hadoop"上使用普通用户hadoop进行操作。(备注:只需一次,下次启动不再需要格式化,只需 start-all.sh)
hadoop namenode -format
某些书上和网上的某些资料中用下面命令执行。

我们在看好多文档包括有些书上,按照他们的hadoop环境变量进行配置后,并立即使其生效,但是执行发现没有找见"bin/hadoop"这个命令。

其实我们会发现我们的环境变量配置的是"$HADOOP_HOME/bin",我们已经把bin包含进入了,所以执行时,加上"bin"反而找不到该命令,除非我们的hadoop坏境变量如下设置。
# set hadoop path
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH :$HADOOP_HOME:$HADOOP_HOME/bin
这样就能直接使用"bin/hadoop"也可以直接使用"hadoop",现在不管哪种情况,hadoop命令都能找见了。我们也没有必要重新在设置hadoop环境变量了,只需要记住执行Hadoop命令时不需要在前面加"bin"就可以了。

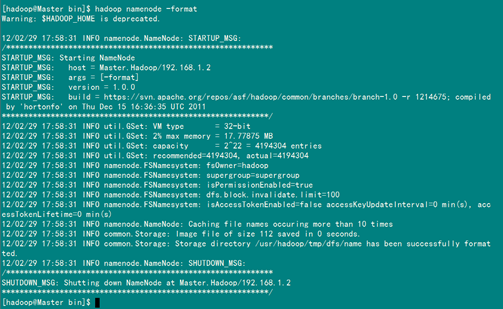
从上图中知道我们已经成功格式话了,但是美中不足就是出现了一个警告,从网上的得知这个警告并不影响hadoop执行,但是也有办法解决,详情看后面的"常见问题FAQ"。
2)启动hadoop
在启动前关闭集群中所有机器的防火墙,不然会出现datanode开后又自动关闭。
service iptables stop
使用下面命令启动。
start-all.sh

执行结果如下:

可以通过以下启动日志看出,首先启动namenode 接着启动datanode1,datanode2,…,然后启动secondarynamenode。再启动jobtracker,然后启动tasktracker1,tasktracker2,…。
启动 hadoop成功后,在 Master 中的 tmp 文件夹中生成了 dfs 文件夹,在Slave 中的 tmp 文件夹中均生成了 dfs 文件夹和 mapred 文件夹。
查看Master中"/usr/hadoop/tmp"文件夹内容

查看Slave1中"/usr/hadoop/tmp"文件夹内容。

3)验证hadoop
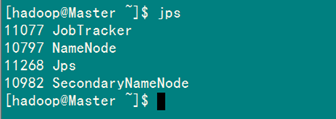
(1)验证方法一:用"jps"命令
在Master上用 Java自带的小工具jps查看进程。
在Slave1上用jps查看进程。
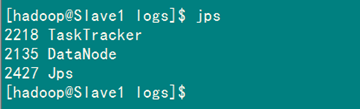
如果在查看Slave机器中发现"DataNode"和"TaskTracker"没有起来时,先查看一下日志的,如果是"namespaceID"不一致问题,采用"常见问题FAQ6.2"进行解决,如果是"No route to host"问题,采用"常见问题FAQ6.3"进行解决。
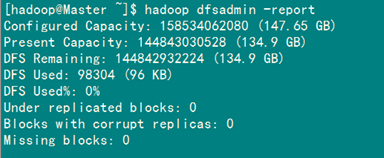
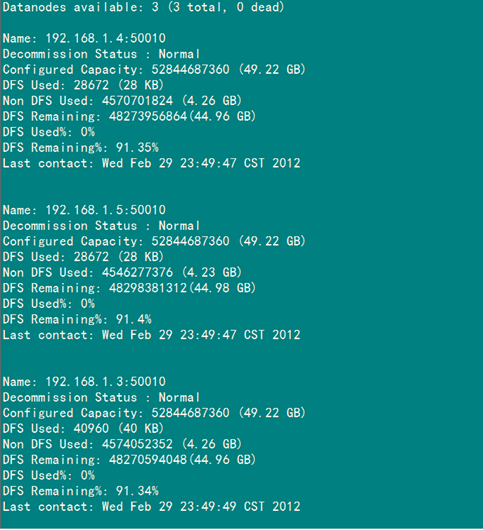
(2)验证方式二:用"hadoop dfsadmin -report"
用这个命令可以查看Hadoop集群的状态。
Master服务器的状态:
Slave服务器的状态
















 3594
3594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









