






Linux环境下启动和关闭Hadoop服务,Spark服务,开启集群的命令
- 激活虚拟环境:conda activate pyspark
- 启动Hadoop服务:cd /usr/local/hadoop-3.1.4/sbin/
./start-all.sh
其中/usr/local/hadoop-3.1.4/目录是你安装hadoop所在的目录位置
hadoop-3.1.4是下载hadoop的名字
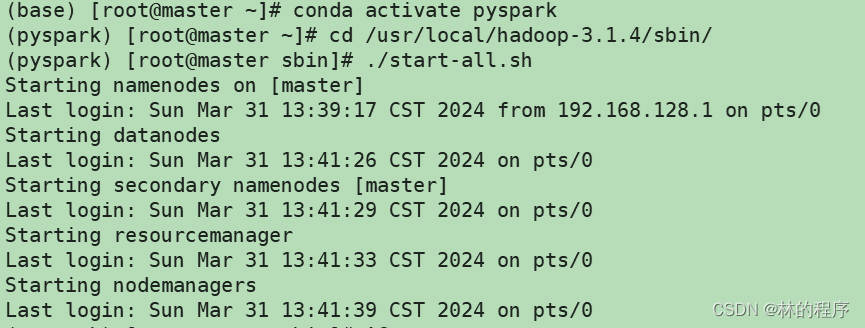
- 启动Spark服务:cd /usr/local/spark-3.2.1-bin-hadoop2.7/sbin
./start-all.sh
其中/usr/local/spark-3.2.1-bin-hadoop2.7/目录是你安装spark所在的目录位置
spark-3.2.1-bin-hadoop2.7是下载spark的名字

4.如果不关闭服务而直接关机虚拟机会导致下次使用出现问题,因此我们在打开服务之后不需要使用了应该用命令关闭服务
5.关闭Hadoop服务:cd /usr/local/hadoop-3.1.4/sbin/
./stop-all.sh
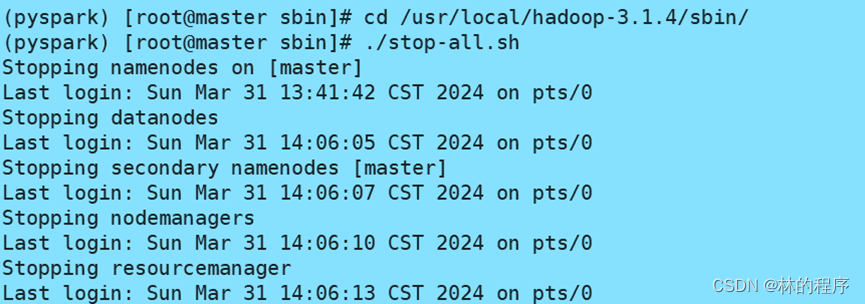
6.关闭spark服务:cd /usr/local/spark-3.2.1-bin-hadoop2.7/sbin
./stop-all.sh
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









