







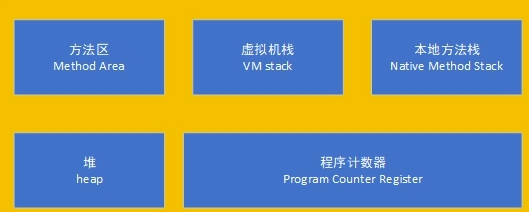
 1. 首先这是一个特别热门的面试考点,这个问题只要回答的全面基本上这一轮面试就过了2. JVM内存模型其中线程共享的和线程私有的两大模块,方法区,堆是共享的虚拟机栈,本地方法栈,程序计数器是私有的垃圾回收必然是再共享模块中进行的,方法区是加载类模板的这些一般不会被回收只有我们的堆(heap)是不停创建对象的,所以只有堆这一块涉及到垃圾回收3.堆(heap)JVM内存划分为堆内存和非堆内存...
1. 首先这是一个特别热门的面试考点,这个问题只要回答的全面基本上这一轮面试就过了2. JVM内存模型其中线程共享的和线程私有的两大模块,方法区,堆是共享的虚拟机栈,本地方法栈,程序计数器是私有的垃圾回收必然是再共享模块中进行的,方法区是加载类模板的这些一般不会被回收只有我们的堆(heap)是不停创建对象的,所以只有堆这一块涉及到垃圾回收3.堆(heap)JVM内存划分为堆内存和非堆内存...
1. 首先这是一个特别热门的面试考点,这个问题只要回答的全面基本上这一轮面试就过了
2. JVM内存模型
其中线程共享的和线程私有的两大模块,方法区,堆是共享的
虚拟机栈,本地方法栈,程序计数器是私有的
垃圾回收必然是再共享模块中进行的,方法区是加载类模板的这些一般不会被回收
只有我们的堆(heap)是不停创建对象的,所以只有堆这一块涉及到垃圾回收
3.堆(heap)

JVM内存划分为堆内存和非堆内存,堆内存分为年轻代(Young Generation)、老年代(Old Generation),非堆内存就一个永久代(Permanent Generation)。
年轻代又分为Eden和Survivor区。Survivor区由FromSpace和ToSpace组成。Eden区占大容量,Survivor两个区占小容量,默认比例是8:1:1。
堆内存用途:存放的是对象,垃圾收集器就是收集这些对象,然后根据GC算法回收。
非堆内存用途:永久代,也称为方法区,存储程序运行时长期存活的对象,比如类的元数据、方法、常量、属性等。
在JDK1.8版本废弃了永久代,替代的是元空间(MetaSpace),元空间与永久代上类似,都是方法区的实现,他们最大区别是:元空间并不在JVM中,而是使用本地内存。
元空间有注意有两个参数:
MetaspaceSize :初始化元空间大小,控制发生GC阈值
MaxMetaspaceSize : 限制元空间大小上限,防止异常占用过多物理内存
-Xms :设置初始分配大小,默认为物理内存的1/64.
-Xmx :设置最大分配内存,默认为物理内存的1/4.
Xmn :新生代分配内存大小。
-XX:+PrintCGDetails :输出详细GC处理日志。
垃圾回收算法:
1.标记清除
标记-清除算法将垃圾回收分为两个阶段:标记阶段和清除阶段。
在标记阶段首先通过根节点(GC Roots),标记所有从根节点开始的对象,未被标记的对象就是未被引用的垃圾对象。然后,在清除阶段,清除所有未被标记的对象。
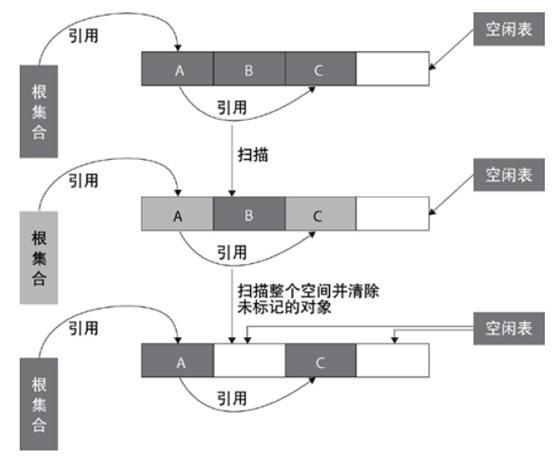
适用场合:
存活对象较多的情况下比较高效
适用于年老代(即旧生代)
缺点:
容易产生内存碎片,再来一个比较大的对象时(典型情况:该对象的大小大于空闲表中的每一块儿大小但是小于其中两块儿的和),会提前触发垃圾回收
扫描了整个空间两次(第一次:标记存活对象;第二次:清除没有标记的对象)
2.复制算法
从根集合节点进行扫描,标记出所有的存活对象,并将这些存活的对象复制到一块儿新的内存(图中下边的那一块儿内存)上去,之后将原来的那一块儿内存(图中上边的那一块儿内存)全部回收掉
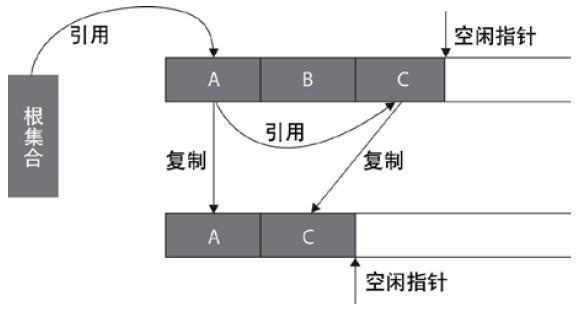
现在的商业虚拟机都采用这种收集算法来回收新生代。
适用场合:
存活对象较少的情况下比较高效
扫描了整个空间一次(标记存活对象并复制移动)
适用于年轻代(即新生代):基本上98%的对象是"朝生夕死"的,存活下来的会很少
缺点:
需要一块儿空的内存空间
需要复制移动对象
3.标记整理
复制算法的高效性是建立在存活对象少、垃圾对象多的前提下的。
这种情况在新生代经常发生,但是在老年代更常见的情况是大部分对象都是存活对象。如果依然使用复制算法,由于存活的对象较多,复制的成本也将很高。
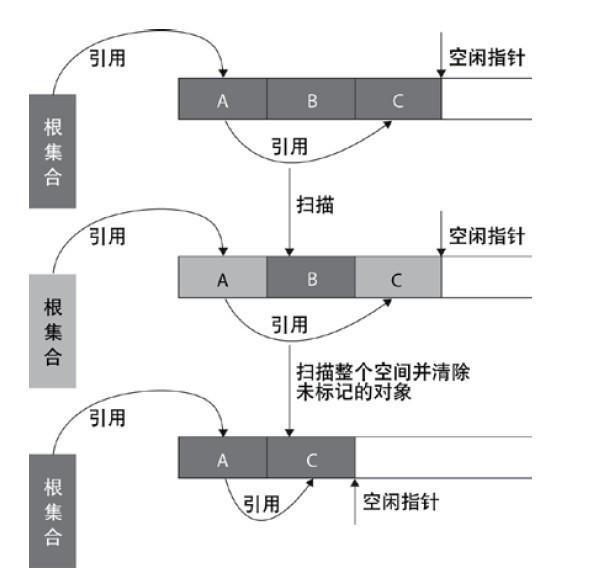
标记-压缩算法是一种老年代的回收算法,它在标记-清除算法的基础上做了一些优化。
首先也需要从根节点开始对所有可达对象做一次标记,但之后,它并不简单地清理未标记的对象,而是将所有的存活对象压缩到内存的一端。之后,清理边界外所有的空间。这种方法既避免了碎片的产生,又不需要两块相同的内存空间,因此,其性价比比较高。
4.分代收集算法
分代收集算法就是目前虚拟机使用的回收算法,它解决了标记整理不适用于老年代的问题,将内存分为各个年代。一般情况下将堆区划分为老年代(Tenured Generation)和新生代(Young Generation),在堆区之外还有一个代就是永久代(Permanet Generation)。
在不同年代使用不同的算法,从而使用最合适的算法,新生代存活率低,可以使用复制算法。而老年代对象存活率搞,没有额外空间对它进行分配担保,所以只能使用标记清除或者标记整理算法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 122
122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









