






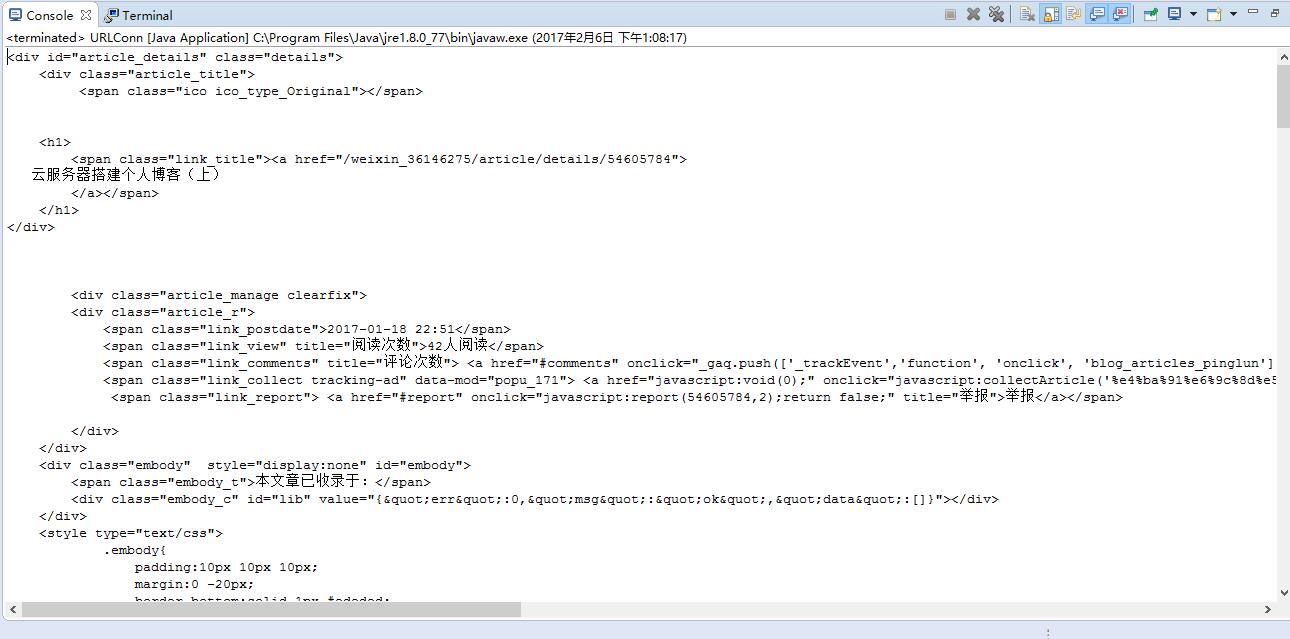
本文实现抓取链接网页内容:【http://blog.csdn.net/weixin_36146275/article/details/54605784】此链接是博主的博客,用来做个例子。
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.Scanner;
public class URLConn {
/**
* 获取网页链接中的所有内容
* @return
*/
public static String getContentFromUrl(){
String content = "";
try {
//传入网页访问地址
String address = "http://blog.csdn.net/weixin_36146275/article/details/54605784";
URL url = new URL(address);
URLConnection conn = url.openConnection();
//添加一行,解决"403服务器拒绝访问"错误
conn.setRequestProperty("User-Agent", "Mozilla/31.0 (compatible; MSIE 10.0; Windows NT; DigExt)");
//获取网页输入流
InputStream is = conn.getInputStream();
//设置流的编码格式
Scanner s = new Scanner(is , "UTF-8");
//一行一行拼接流信息
while(s.hasNextLine()){
content += s.nextLine()+"\n";
}
//关闭Scanner、InputStream
s.close();
is.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return content;
}
/**
* 计算截取网页内容起始位置,并截取。
* @param content
* @return
*/
public static String getSPFromContent(String content){
String sp = "";
//开始位置
int beginIdex = content.indexOf("<div id=\"article_details\" class=\"details\">");
//结束位置
int endIndex = content.indexOf("<div id=\"suggest\"");
sp = content.substring(beginIdex, endIndex);
return sp;
}
public static void main(String[] args) {
String content = getContentFromUrl();
String sp = getSPFromContent(content);
System.out.println(sp);
}
}
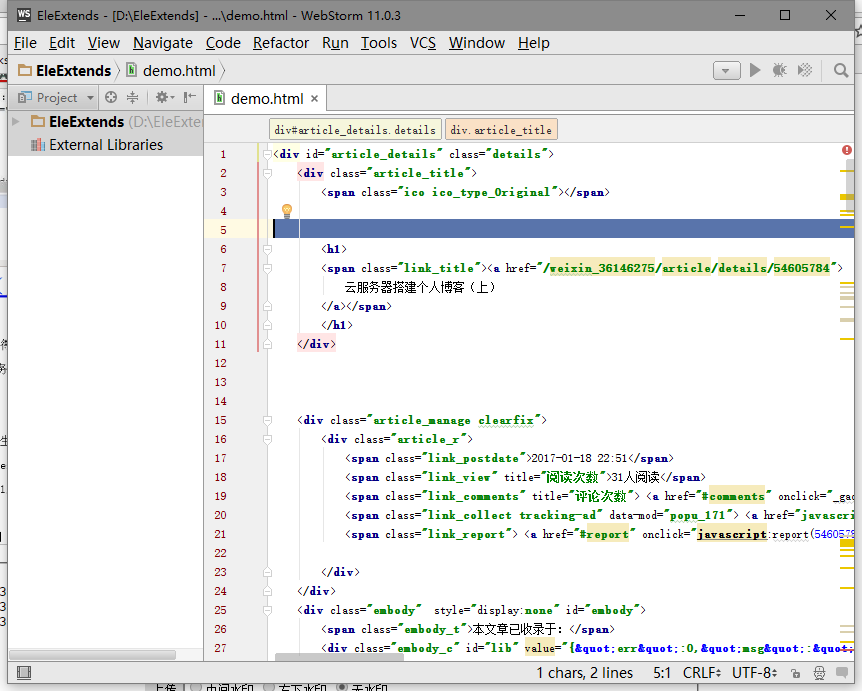
使用html编辑工具打开就看到正常的网页了
















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









