






本文会从以下几个方面来讲解以下Spark中的RDD持久化:
1、为什么要进行RDD持久化
2、RDD持久化原理
3、RDD持久化的使用场景
4、怎样使用RDD持久化
5、通过cache()和persist()源码讲解RDD持久化策略级别
6、RDD持久化策略选择
1、为什么要进行RDD持久化
在讲RDD持久化之前,先思考一个问题?
Spark主要是基于内存进行计算的,那么为什么我们对大量数据进行了很多的算子操作而内存不会爆掉?
在之前的文章中讲到Spark中有tranformation和action两类算子,tranformation算子具有lazy特性,只有action算子才会触发job的开始,从而去执行action算子之前定义的tranformation算子,从hdfs中读取数据等,计算完成之后,Spark会将内存中的数据清除,这样处理的好处是避免了OOM问题,但不好之处在于每次job都会从头执行一边,比如从hdfs上读取文件等,如果文件数据量很大,这个过程就会很耗性能。这个问题就涉及到本文要讲的RDD持久化特性,合理的使用RDD持久化对Spark的性能会有很大提升。
1.1 首先看下如果不进行RDD持久化会有哪些影响?
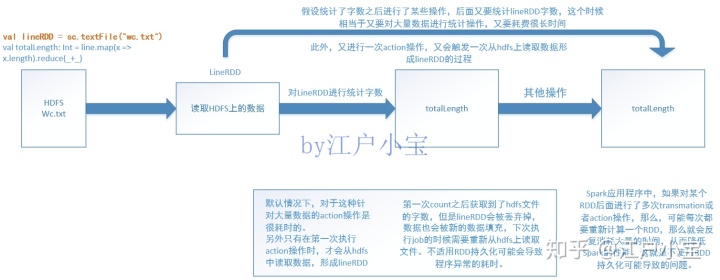
假设有一份文件,数据量很大,我们需要计算出这份文件的字数,功能实现其实很简单,利用下面的代码就可以实现
val lineRDD = sc.textFile("data/wc.txt")
val totalLength: Int = line.map(x => x.length).reduce(_+_)假设统计了文件字数之后我们进行了某些操作,后面又需要对lineRDD进行操作,看一下如果不使用RDD持久化会带来哪些问题。
默认情况下,针对大量数据的action操作是很耗时的。Spark应用程序中,如果对某个RDD后面进行了多次transmation或者action操作,那么,可能每次都要重新计算一个RDD,那么就会反复消耗大量的时间,从而降低Spark的性能。第一次统计之后获取到了hdfs文件的字数,但是lineRDD会被丢弃掉,数据也会被新的数据填充,下次执行job的时候需要重新从hdfs上读取文件,不使用RDD持久化可能会导致程序异常的耗时。
1.2 使用RDD持久化的好处
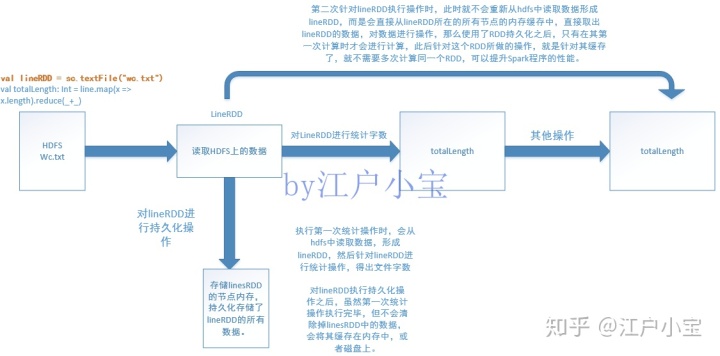
对lineRDD执行持久化操作之后,虽然第一次统计操作执行完毕,但不会清除掉linesRDD中的数据,会将其缓存在内存中,或者磁盘上。第二次针对lineRDD执行操作时,此时就不会重新从hdfs中读取数据形成lineRDD,而是会直接从lineRDD所在的所有节点的内存缓存中,直接取出lineRDD的数据,对数据进行操作,那么使用了RDD持久化之后,只有在其第一次计算时才会进行计算,此后针对这个RDD所做的操作,就是针对其缓存了,就不需要多次计算同一个RDD,可以提升Spark程序的性能。
2、RDD持久化原理
Spark中非常重要的一个功能特性就是可以将RDD持久化在内存中,当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内存中,并且在之后对该RDD的反复使用中,直接使用内存缓存的partition。这样的话,对于针对一个RDD反复执行多个操作的场景,就只要针对RDD计算一次即可,后面直接使用该RDD,而不用反复计算该RDD。
3、RDD持久化的使用场景
RDD持久化虽然可以提高性能,但会消耗内存空间,一般用在如下场景:
- 1、第一次加载大量的数据到RDD中
- 2、频繁的动态更新RDD Cache数据,不适合使用Spark Cache、Spark lineage
4、怎样使用RDD持久化
要持久化一个RDD,只要调用其cache()或者persist()方法即可。在该RDD第一次被计算出来时,就会直接缓存在每个节点中,而且Spark的持久化机制是自动容错的,如果持久化的RDD的任何pratition丢失了,Spark会自动通过其源RDD,重新计算该parititon。
5、通过cache()和persist()源码讲解RDD持久化策略级别
通过cache()和persist()的源码我们可以看出两者的区别以及RDD持久化级别
def cache(): this.type = persist()
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)cache()和persist()的区别在于,cahe()是persist()的一种简化方式,cache()的底层就是调用的persist()的无参版本,即persist(MEMORY_ONLY),将数据持久化到内存中,如果需要从内存中清除缓存,调用unpersist()方法即可。Spark在进行shuffle操作的时候也会进行数据的持久化,比如写入磁盘,主要是为了避免节点失败时,重新计算整个过程。
RDD持久化是可以手动选择不同的策略的,默认是持久化到内存中的。还可以持久化到磁盘上,使用序列化的方式持久化,对持久化的数据进行复用,只要在调用persist()方法时传入对应的StorageLevel即可。

6、RDD持久化策略选择
优先使用MEMORY_ONLY,如果可以缓存所有数据的化,那么就使用这种级别,纯内存速度最快,而且没有序列化,不需要消耗CPU进行反序列化操作。
如果MEMORY_ONLY策略无法存储所有的数据的化,使用MEMORY_ONLY_SER,将数据进行序列化存储,节约空间,纯内存操作速度块,只是需要消耗cpu进行反序列化
如果需要进行快速的失败恢复,选择带后缀为2的策略,进行数据的备份,这样节点在失败时不需要重新计算
能不使用DISK相关的策略就不使用,有时从磁盘读取的速度还不如重新计算来的快。















 8966
8966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









