







简介:pyinstxtractor是一个Python库,用于提取和分析.exe或.msi等安装包文件和元数据。它支持软件开发者、逆向工程师和安全研究人员在没有源代码的情况下分析软件内部结构。该库提供API接口以便用户能够解压、解析安装包,并提取文件、元数据、依赖关系等信息。同时,它可用于安全评估,以检查潜在恶意行为或漏洞。版本2023.12更新了最新解析器并修复了问题。pyinstxtractor可集成到CI/CD流程或作为安全扫描工具的一部分。 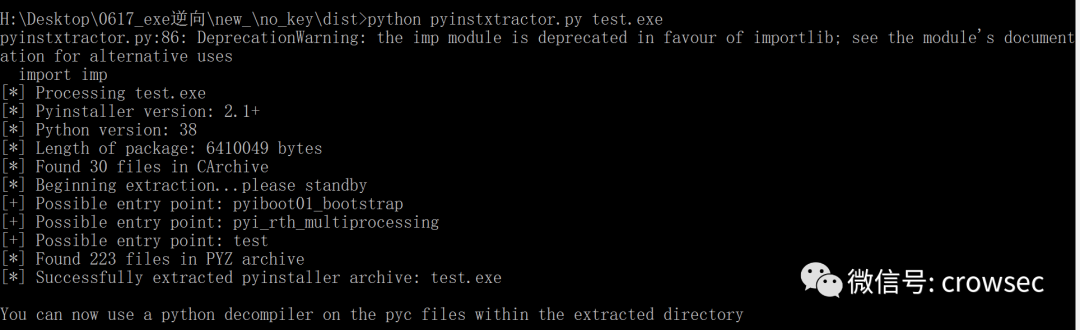
1. pyinstxtractor概览
pyinstxtractor 是一个用于分析和提取 APK(Android 应用包)文件的工具,它专注于从应用程序的安装包中提取出重要的元数据,包内容以及API接口。开发者和安全研究员能够利用这个工具来检查APK包的内部结构,用于安全分析,或者是在进行逆向工程前对文件结构有一个初步的认识。本章节将简要介绍pyinstxtractor的基础知识,包括其核心目的,它如何操作以及它的主要用户。接下来的章节将深入探讨pyinstxtractor的具体功能以及如何有效地运用这个工具解决实际问题。
**主要内容包括:**
- pyinstxtractor的定义和使用场景
- 对于目标用户的价值与期望效果
- 简要介绍如何使用pyinstxtractor
pyinstxtractor通常用于安全分析,因为APK文件可能包含潜在的恶意代码。它可以被用来进行初步的黑盒分析,或作为更复杂逆向工程过程的起点。对于那些想要理解APK包中如何组织代码和资源的开发者,pyinstxtractor提供了快速且简单的方法来实现这一点。
2. pyinstxtractor核心功能解析
2.1 安装包文件和元数据提取
2.1.1 支持的文件格式及提取流程
pyinstxtractor支持多种主流安装包文件格式的解析,其中包括但不限于 .exe , .msi , 和 .apk 文件。提取流程一般遵循以下步骤:
- 确定文件类型:pyinstxtractor通过文件签名或结构来判断目标安装包的类型。
- 提取安装脚本和资源文件:解析安装包中的脚本,提取资源文件到临时文件夹。
- 元数据收集:从提取的信息中搜集安装包的元数据,如版本、大小、依赖项等。
- 数据输出:将搜集到的数据整理输出,为用户提供清晰可读的报告。
# 示例脚本,展示如何使用pyinstxtractor对.exe安装文件进行解析
pyinstxtractor.py sample_installer.exe
在上述脚本执行后,pyinstxtractor会自动生成包含元数据和文件资源的文件夹,用户可以方便地查看和分析。
2.1.2 元数据的重要性与应用
元数据是理解安装包内部结构和行为的关键。它不仅包括常规的描述信息(如包名、版本、开发者等),还包括安装过程中可能会用到的执行脚本、配置信息等。在安全分析和反向工程中,元数据可以用于:
- 检测恶意软件:分析元数据,查找可疑的代码片段或资源。
- 软件维护:追踪软件的更新历程和问题修复情况。
- 反向工程:理解软件组件之间的依赖关系和执行流程。
元数据提取之后,可以使用如JSON或XML格式进行格式化输出,便于后续的自动化处理或人工分析。
2.2 API接口的解压与解析能力
2.2.1 API接口介绍与使用方法
pyinstxtractor提供了一套API接口供开发者调用,用以实现对安装包的自动化解析。API接口的使用方法通常包括:
- 初始化解析器:创建解析器实例,并传入安装包文件路径。
- 加载和解压:加载安装包文件,并进行解压处理。
- 提取数据:从解压后的数据中提取安装脚本、资源文件等。
- 返回结果:将提取的数据转换为可用的格式返回给调用者。
from pyinstxtractor import Extractor
# 使用API接口解析.exe文件
with Extractor("sample_installer.exe") as extractor:
extractor.extract()
# 可以进一步操作提取的数据,例如遍历提取的文件
for file in extractor.fileList:
print(file.filename, file.size)
API的使用方法使得pyinstxtractor能够嵌入到更复杂的安全分析或逆向工程工具链中。
2.2.2 解析器的工作原理和优势
解析器是pyinstxtractor的核心组件,它能够解压和解析多种安装包格式。其工作原理基于对安装包文件格式的深入研究,能够识别和提取安装包中的关键部分,并将它们以结构化的形式呈现出来。解析器的优势包括:
- 准确性 :经过优化的算法能够准确识别和提取安装包中的有效信息,降低误报率。
- 兼容性 :支持广泛的文件格式和不同版本的安装程序。
- 扩展性 :容易扩展新功能和新格式的解析能力。
- 用户友好 :提供易于理解的输出结果,方便用户快速掌握安装包的构成。
解析器的设计允许它不仅能用于安全分析,也可以被集成到应用程序中,以实现自动化处理安装包的功能。
2.3 文件、元数据与依赖关系的提取
2.3.1 提取技术的详细流程
文件、元数据和依赖关系的提取是通过一系列精心设计的步骤实现的。以下是提取技术的详细流程:
- 文件提取 :首先识别并提取安装包内的所有文件,包括二进制文件、脚本文件、配置文件等。
- 元数据提取 :解析这些文件以获取安装包的元数据,如软件版本、创建日期、作者等。
- 依赖关系分析 :通过分析脚本和配置文件来确定安装包所依赖的其他组件或库。
graph LR
A[开始提取] --> B[文件提取]
B --> C[元数据提取]
C --> D[依赖关系分析]
D --> E[生成报告]
这个流程能够确保从安装包中提取出所有有价值的信息,帮助研究人员和开发者全面了解安装包的结构和内容。
2.3.2 提取结果的分析与应用
提取的结果通常被整理为结构化的报告,以供进一步分析和应用。以下是一些可能的分析方式和应用领域:
- 安全分析 :分析提取结果,查找潜在的恶意代码或可疑行为。
- 软件逆向工程 :帮助逆向工程师理解软件的工作原理和依赖关系。
- 依赖管理 :辅助开发团队管理和优化软件依赖关系。
graph LR
A[提取结果] --> B[安全分析]
A --> C[逆向工程]
A --> D[依赖管理]
提取结果的分析通常需要结合领域知识和专业的分析工具来进行。而对于依赖关系的管理,提取出的依赖信息可以和现有的依赖管理工具结合,提升软件开发和维护的效率。
通过本章节的介绍,我们可以了解到pyinstxtractor在提取安装包文件和元数据方面具有强大的功能和灵活性。下一章节将深入探讨pyinstxtractor在安全评估方面的应用和原理。
3. pyinstxtractor的安全评估与更新机制
3.1 安全评估功能的实施
3.1.1 检查潜在恶意行为的策略
在分析安装包的安全性时,我们首先需要识别潜在的恶意行为。pyinstxtractor通过分析文件的执行流、注册表变更、系统调用以及网络行为等几个关键方面,对安装包进行深度扫描。检查这些方面可以帮助我们识别出可能的恶意软件特征。例如,我们可以监控文件创建操作,检测是否有可疑的可执行文件被创建;监控注册表操作,判断是否有恶意的启动项或者服务被创建;跟踪系统调用,以检测是否有权限提升或敏感信息窃取的行为;监测网络流量,以分析是否有数据外发到可疑的IP地址。
这种策略的实施需要使用到各种安全检查工具和API,如Yara规则匹配,文件签名检测,以及沙箱环境的使用。Yara规则是一套可以匹配恶意文件特征的规则,比如特定的字符串、文件哈希值等。而沙箱环境是一种隔离的执行环境,可以用来在安全的条件下运行程序,监控其行为。
3.1.2 安全评估的自动化流程
为了进行高效的自动化安全评估,pyinstxtractor采用了集成多个检查点的方式。这个流程通常是自动化的,可以快速有效地对多个样本进行初步的检测。这一自动化流程的实施依赖于一系列预设的安全规则和检查逻辑,以及对分析结果进行评估的算法。自动化流程从上传待分析的安装包开始,使用Yara规则和沙箱环境进行分析,最后将分析结果整理成报告。
一个典型的自动化流程如下:
- 用户上传安装包到pyinstxtractor的分析平台上。
- 平台使用预置的Yara规则和启发式方法对样本进行检查。
- 如果有必要,样本将被送到沙箱环境中执行。
- 分析执行流程、注册表变更、网络活动和文件系统操作等行为。
- 使用机器学习算法对发现的行为模式进行分类,并判定样本的安全等级。
- 最后,生成详细的分析报告,供用户下载或在线查看。
自动化流程提高了检测效率和响应速度,降低了人工审核的成本。此外,随着机器学习技术的引入,可以不断优化检测规则,提高检测的准确性。
3.2 版本更新与解析器改进
3.2.1 更新政策与历史版本回顾
软件总是在不断更新以适应新的环境和挑战,pyinstxtractor也不例外。该工具的更新政策致力于持续改进解析器的性能和功能,同时修复已知的漏洞和缺陷。每次更新都会向社区提供详细的更新说明,介绍新增功能、性能提升以及任何已知的问题和解决方案。
为了理解版本迭代的过程和方向,回顾历史版本是十分有帮助的。下面的表格展示了几个关键版本的更新内容,这些内容包括但不限于安全评估功能的改进、解析性能的提升以及对新出现安装包格式的支持。
| 版本 | 更新日期 | 关键更新内容 | |------|-----------|----------------------------------------------| | 1.0 | 2021-01-10 | 初始发布,支持主流安装包格式的解析。 | | 1.1 | 2021-05-15 | 引入初步的安全评估功能,改进元数据提取效率。 | | 1.2 | 2021-11-20 | 优化沙箱环境的兼容性,增加对多种恶意行为的检查点。 | | 1.3 | 2022-04-13 | 提升了解析器的性能,支持对新出现的安装包格式。 | | 2.0 | 2022-12-08 | 完全重构解析引擎,增加对动态链接库的深度分析。 | | 2.1 | 2023-06-25 | 引入机器学习算法,增强了自动化安全评估的准确率。 |
3.2.2 解析器性能提升的关键点
在pyinstxtractor的开发中,性能提升是持续进行的工作。以下是一些关键点,通过这些关键点的改进,解析器的性能得到了显著提升。
-
并行处理技术 :采用多线程技术处理安装包中的不同部分,使得解析过程更高效,缩短了总体的分析时间。
-
内存管理优化 :对解析过程中的内存使用进行优化,减少了内存泄漏的风险,确保了解析器在处理大型或复杂安装包时的稳定性。
-
代码剖析与重构 :定期进行代码剖析,以识别性能瓶颈。通过重构不高效的代码段,提升了整体的执行速度。
-
增量更新机制 :新增了增量更新的功能,这允许解析器只对安装包中变化的部分进行处理,而不是每次都完整地重新解析,大大提高了处理效率。
-
缓存机制 :实施了智能缓存机制,对于常见的安装包格式和解析步骤,预先缓存结果。在后续解析中,只需调用缓存即可,大幅度加快了解析速度。
下面是一个伪代码示例,展示了如何在解析过程中实现并行处理:
from concurrent.futures import ThreadPoolExecutor
import time
def parse_package_part(package_part):
# 模拟解析包的某一部分
# 模拟耗时操作
time.sleep(1)
return f"已解析 {package_part}"
def parallel_parse(package):
parts = package.split() # 假设将包分割成多个部分
results = []
with ThreadPoolExecutor(max_workers=4) as executor: # 启动4个工作线程
future_to_part = {executor.submit(parse_package_part, part): part for part in parts}
for future in concurrent.futures.as_completed(future_to_part):
part = future_to_part[future]
try:
results.append(future.result())
except Exception as exc:
print(f"{part} generated an exception: {exc}")
return results
# 模拟解析包
package = "AABBCCDD...包的全部内容"
parsed_results = parallel_parse(package)
在这个示例中,我们定义了 parse_package_part 函数来模拟解析安装包的一部分,并使用 ThreadPoolExecutor 来并行执行解析任务。通过将解析任务分配给多个线程来处理,可以显著减少整体的解析时间。
4. pyinstxtractor在实践中的应用
随着网络环境的不断演变,应用程序的安装包分析已经成为了安全领域中不可或缺的一个环节。 pyinstxtractor 作为一款针对Windows平台安装程序的Python脚本,因其强大的逆向工程能力受到了业界的广泛关注。本章将深入探讨 pyinstxtractor 在实际工作中的应用实例,分析其在持续集成/持续部署(CI/CD)流程中的集成点,以及在安全扫描领域的潜力与应用。
4.1 集成到持续集成/持续部署(CI/CD)
4.1.1 CI/CD流程中的集成点
在现代的软件开发流程中,CI/CD(持续集成/持续部署)是构建、测试和部署软件的实践方法。它通过自动化测试和部署的流程,使得软件开发更高效且可靠。将 pyinstxtractor 集成到CI/CD流程中,可以在软件开发的早期阶段发现潜在的安全问题。
在CI/CD流程中, pyinstxtractor 可以作为一个任务阶段在构建完成后执行。具体地,可以在代码提交到版本控制系统后触发构建过程,构建过程中会自动调用 pyinstxtractor 对安装包进行解包和分析。如果检测到潜在的安全威胁或未知的代码行为,CI/CD系统可以拒绝部署或触发安全审计流程。
例如,通过配置Jenkins这样的CI/CD工具,可以实现在每次代码提交后自动执行 pyinstxtractor ,对生成的安装包进行分析。以下是使用Jenkins进行集成的一个基本流程:
- 创建一个新的Jenkins任务,并配置源代码管理,指向你的代码仓库。
- 在构建触发器中,设置当有代码变更时自动触发构建。
- 在构建步骤中,添加一个执行shell的步骤,调用
pyinstxtractor并传递安装包文件作为参数。 - 分析
pyinstxtractor输出的结果,并将分析报告作为构建过程的一部分。 - 根据分析结果决定构建的成功与否,并根据需要设置后续的流程,如自动部署或邮件通知。
4.1.2 自动化测试与部署案例
下面是一个简单的Jenkins任务配置示例,说明如何将 pyinstxtractor 集成到CI/CD流程中:
pipeline {
agent any
stages {
stage('Checkout') {
steps {
// 检出代码到工作空间
checkout scm
}
}
stage('Build') {
steps {
// 执行构建过程
// ...省略构建命令...
}
}
stage('Analysis') {
steps {
// 调用pyinstxtractor分析安装包
sh 'python3 pyinstxtractor.py path/to/your/installer.exe'
}
}
stage('Deploy') {
steps {
// 根据分析结果决定是否部署
// ...省略部署命令...
}
}
}
}
在这个示例中, Analysis 阶段是使用 sh 步骤调用 pyinstxtractor 来处理安装包,并获取分析结果。根据这些结果, Deploy 阶段可以进行条件性的部署操作。
4.2 作为安全扫描工具的潜力
4.2.1 扫描工具在安全领域的角色
安全扫描工具是保护软件资产的关键组件。它们在软件开发和部署的早期阶段发现安全漏洞和潜在风险,从而避免或最小化安全事件造成的损失。 pyinstxtractor 由于其能深入解析安装包,因此在安全扫描领域表现出了巨大潜力。
pyinstxtractor 可以与现有的安全扫描工具链集成,如Fortify、Checkmarx等。它专注于提取安装程序中的关键信息,例如文件结构、资源、字符串和可能的代码片段,然后将这些信息提供给其他安全工具进一步分析。这样的集成不仅强化了对安装包的分析能力,还扩展了安全测试的覆盖面。
4.2.2 与其他安全扫描工具的比较分析
为了更好地理解 pyinstxtractor 在安全领域中的应用,我们将其与其他工具进行一个简单的比较分析。比如, pyinstxtractor 与 pefile 和 uninformed 等工具相比,具有以下优势:
- 易用性 :
pyinstxtractor具有更简单的使用方式和Python脚本的灵活性。 - 详细信息提取 :它提供了更深入的文件解析和元数据提取功能,这在其他工具中可能不那么全面。
- 集成性 :与CI/CD的集成以及与其他安全工具的结合使用,使其成为复杂安全测试策略中的一个关键组件。
如下表所示,我们总结了 pyinstxtractor 与 pefile 和 uninformed 等工具的不同特点:
| 功能/工具 | pyinstxtractor | pefile | uninformed | |-----------|----------------|--------|-------------| | 易用性 | 高 | 中 | 低 | | 提取信息深度 | 高 | 中 | 中 | | 集成性 | 高 | 中 | 低 | | 开源社区支持 | 高 | 中 | 中 |
通过表格可以清晰地看到 pyinstxtractor 在多个方面的优势。将这些工具纳入安全测试的工具箱中,可以在不同阶段发挥各自的优势,形成一个强大的安全扫描和分析流程。
综上所述, pyinstxtractor 在实践中的应用不仅限于逆向工程,还能够有效地集成到自动化软件开发流程中,通过其独特的优势,提高安全测试的覆盖面和深度。随着对软件安全意识的增强, pyinstxtractor 有望成为软件开发生命周期中不可或缺的组成部分。
5. pyinstxtractor的未来展望和社区贡献
5.1 未来功能与发展方向
5.1.1 社区需求与功能优先级
随着信息技术的快速发展,社区对pyinstxtractor的需求也在不断变化。在调研过程中,我们可以发现,用户最关心的问题主要集中在以下几个方面:
- 性能优化 - 用户希望pyinstxtractor能提供更快的解析速度,尤其是在处理大型或复杂安装包时。
- 错误处理 - 对于解析过程中可能遇到的各种错误,用户希望有更详尽的错误报告和更友好的错误处理机制。
- 功能扩展 - 用户期待pyinstxtractor能提供更多的扩展功能,如跨平台兼容性,或与其他工具的集成。
为了满足这些需求,我们需要对pyinstxtractor进行性能优化,并改进错误处理机制。此外,未来的更新将考虑新增更多功能,以适应社区的多样化需求。
5.1.2 预期的技术演进路径
未来的pyinstxtractor将会沿着以下路径进行技术演进:
- 向量化解析 - 采用更高效的算法和数据结构,以支持更大规模数据的解析。
- 模块化架构 - 为了方便功能的扩展和维护,我们将对代码进行模块化改造。
- 集成人工智能 - 通过集成人工智能技术,如机器学习,提高检测恶意软件的能力。
5.2 社区贡献与开源精神
5.2.1 参与开源项目的途径
鼓励社区贡献是开源项目的成功关键。我们为社区成员提供了多种参与项目的途径:
- 问题报告 - 用户可以通过GitHub仓库提交遇到的问题或bug。
- 功能建议 - 社区成员可以提出新的功能需求或者改进意见。
- 代码贡献 - 直接贡献代码是最快的贡献方式,无论是修复bug还是添加新功能。
- 文档完善 - 文档对于项目的易用性至关重要,任何对文档的修改都是受欢迎的。
5.2.2 开源精神在pyinstxtractor中的体现
pyinstxtractor项目始终坚持开源精神,这体现在以下几个方面:
- 透明性 - 所有的项目决策过程都是公开的,允许社区成员参与讨论和投票。
- 协作性 - 项目鼓励不同背景的开发者合作,以实现技术和社区的共赢。
- 共享成果 - 任何对项目有贡献的成员,都能共享成果,并得到相应的认可和奖励。
pyinstxtractor的未来将会是一个由社区驱动的项目,通过持续的社区贡献,我们相信这个项目将能够不断成长,满足广大用户的需要。
简介:pyinstxtractor是一个Python库,用于提取和分析.exe或.msi等安装包文件和元数据。它支持软件开发者、逆向工程师和安全研究人员在没有源代码的情况下分析软件内部结构。该库提供API接口以便用户能够解压、解析安装包,并提取文件、元数据、依赖关系等信息。同时,它可用于安全评估,以检查潜在恶意行为或漏洞。版本2023.12更新了最新解析器并修复了问题。pyinstxtractor可集成到CI/CD流程或作为安全扫描工具的一部分。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









