







寻找第K大数是一个非常经典的算法问题,在面试题中自己也遇到问过,网上也有很多博客讲了很多算法。但是,我看到的很多文章都只介绍到快排思路寻找第k大数,这个算法的平均时间复杂度是 O ( n ) O(n) O(n)的,但在最坏情况下的时间复杂度是 O ( n 2 ) O(n^2) O(n2)的,这个博客介绍的算法基于分治思想,使得算法在最坏情况下的时间复杂度为 O ( n ) O(n) O(n),当然这个算法过程还挺复杂的,中间的处理导致系数很高,其实际表现不一定有快排思路的好,仅做一种拓展!!
需要的预备内容
对于寻找第k大数,最直观的想法是我直接对这个数组进行一次排序,那么这个递增排序好的数组的第k个值就是第k大数,现在根据排序算法它的总体复杂度会是 O ( n l o g n ) O(nlogn) O(nlogn)的,这篇博客不再会讲到这些算法,一些前面的内容可以参考https://blog.csdn.net/orangefly0214/article/details/86527462
这个博客包括了一些基本算法,其中基于快排的那个算法非常重要,面试问到一般写那个算法就不再有问题了。
此外,希望大家先要了解以下分治的思想以及复杂度分析时递推方程的表达和求解,这里不再赘述
寻找第k大数的分治算法
问题:给定数组S,S的长度n以及正整数k,求第k大的数。
根据分治的思想,我们肯定希望将原来的数组划分成子问题,子问题满足某些性质,方便我们删掉某些不可能是第k大的数。
算法的主要思想是:以S中的某个元素
m
∗
m^*
m∗作为标准将S划分成两个子数组
S
1
S_1
S1和
S
2
S_2
S2,其中
S
1
S_1
S1的元素均比
m
∗
m^*
m∗小,
S
2
S_2
S2的元素均比
m
∗
m^*
m∗大。设
S
1
S_1
S1中元素的个数为
∣
S
1
∣
|S_1|
∣S1∣,如果
k
≤
∣
S
1
∣
k \leq|S_1|
k≤∣S1∣,那么原问题就归约在
∣
S
1
∣
|S_1|
∣S1∣中寻找第
k
k
k大的子问题,如果
k
=
∣
S
1
∣
+
1
k = |S_1|+1
k=∣S1∣+1,那么这个
m
∗
m^*
m∗就是我们要找的第
k
k
k大元素,如果
k
>
∣
S
1
∣
+
1
k > |S_1|+1
k>∣S1∣+1,那么原问题就归约在
∣
S
2
∣
|S_2|
∣S2∣中寻找第
k
′
k'
k′大的子问题,其中
k
′
=
k
−
∣
S
1
∣
−
1
k'=k-|S_1|-1
k′=k−∣S1∣−1,那么问题变成了如何确定
m
∗
m^*
m∗。
这里,寻找
m
∗
m^*
m∗的算法复杂度不能太高,若实际已经达到
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn),那不如直接使用排序算法了,因此寻找
m
∗
m^*
m∗的算法应该是O(n)的,这里我们采用分支思想。先将S分组,每5个元素一组,共分成
⌈
n
/
5
⌉
\lceil n/5 \rceil
⌈n/5⌉个组。在每组中寻找一个本组中位数(注:一组中只有5个数,因此这里寻找每一个中位数都是
O
(
1
)
O(1)
O(1)的),然后把这
⌈
n
/
5
⌉
\lceil n/5 \rceil
⌈n/5⌉个中位数放到集合M中,最后在M中递归地调用选择算法选出该集合的一个中位数,这个中位数就是
m
∗
m^*
m∗。这样,这个M的问题规模只有原来的1/5。其算法的伪代码如下:

这里的第4、5步还不能直接理解,我们画个图如下:
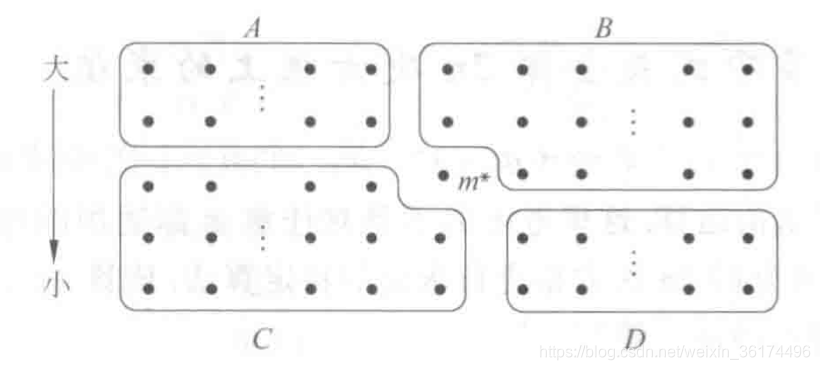
这里的结果是由第3步得到的,那我们每一列都是有序的,且这里将每一组的中位数从小到大排起来了,因此
m
∗
m^*
m∗左边的中位数是小于
m
∗
m^*
m∗的,且这些中位数下面的值都是小于这些中位数的,因此C集合中所有值都小于
m
∗
m^*
m∗,同理B中所有值都大于
m
∗
m^*
m∗,A、D两个集合的元素无法判断,要通过第5步进行划分。
至此,算法介绍就结束了。最后还差一个问题,整个算法的时间复杂度是什么样的?
设原问题是
W
(
n
)
W(n)
W(n)的,首先第3步的子问题中只有n/5个数,该子问题是W(n/5)的,第二个子问题在最后两步,我们要选择
S
1
S_1
S1和
S
2
S_2
S2两个子集中的一个作为子问题,那么这两个集合的大小是多大呢?
我们不妨假设n是5的倍数,n/5是奇数,这样有
n
/
5
=
2
r
+
1
n/5=2r+1
n/5=2r+1。其中A和D集合里都是2r个数,B和C集合中都是3r+2个数,B一定在
S
2
S_2
S2集合中,C一定在
S
1
S_1
S1集合中,考虑最坏情况,A和D都在一个集合中,且这个集合被选成了子问题,那么这个最坏情况下子问题的规模是
3
r
+
2
+
2
r
+
2
r
=
7
r
+
2
<
7
10
n
3r+2+2r+2r = 7r+2<\frac{7}{10}n
3r+2+2r+2r=7r+2<107n
而剩下其他部分找
m
∗
m^*
m∗的过程都是
O
(
n
)
O(n)
O(n)的,这样就可以写出递推方程为:
W
(
n
)
≤
W
(
n
5
)
+
W
(
7
n
10
)
+
t
n
W(n) \leq W(\frac{n}{5})+W(\frac{7n}{10})+tn
W(n)≤W(5n)+W(107n)+tn
求解这个递推方程就可以得到最坏情况下复杂度是
O
(
n
)
O(n)
O(n)的了(求解过程略,可以用递归树)
一些小问题
算法的介绍就是这样。我感觉比较绕的点就在于A、B、C、D四个集合是怎么来的,大小关系是怎么样的那个地方。还有可以思考的点
(1) 算法的空间复杂度是多少?
O
(
n
)
O(n)
O(n),因为需要引入集合M,注意相对的那些
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)的排序很多空间复杂度都是
O
(
1
)
O(1)
O(1),因此基于排序的话寻找第k大的算法也会是
O
(
1
)
O(1)
O(1)的,这也正印证那句“空间换时间”。
(2) 我们知道快排的时间复杂度在最坏情况下是
O
(
n
2
)
O(n^2)
O(n2)的,能否使快排的时间复杂度在最坏情况下也是
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)?
这个问题面试被问过一次,问题关键在于理解为啥快排最坏情况下是
O
(
n
2
)
O(n^2)
O(n2)的。因为我们在数组中选一个数遍历得到这个数位置时,我们每次选到的这个数都可能在头或尾,这样复杂度就是
O
(
n
2
)
O(n^2)
O(n2)的。因此我们可以考虑调用上面的Select算法,使得快排每一次找的值都是整个数组的中位数,这样整个快排的时间复杂度就都保持
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)。
当然实际情况肯定不会这样做,因为Select算法的系数是很大的,用该算法处理快排大概率使算法效率降低。
(3)为什么这里将S分组的时候是5个元素一组,3个、7个不行吗?
不同的元素数会改变A、B、C、D四个集合的情况,从而会导致不一样的递推方程。可以自己试试,最后用3个是不行的,7个可以。
一个小算法题
在LeetCode上遇到一道很经典的题—【面试题 17.10. 主要元素】
https://leetcode-cn.com/problems/find-majority-element-lcci/
数组中占比超过一半的元素称之为主要元素。给你一个整数数组,找出其中的主要元素。
若没有,返回 -1 。请设计时间复杂度为 O(N) 、空间复杂度为 O(1) 的解决方案。
示例 1:
输入:[1,2,5,9,5,9,5,5,5]
输出:5
最开始想写这个博客就是因为在LeetCode遇到了这道题,想起我们当年学算法课其中考试就有一题这个,当时不要求空间复杂度,但限定了分治算法。
参考答案就是调用上面寻找第k大的算法,寻找整个数组的中位数,在用这个中位数遍历一遍数组(如果存在主要元素,那么中位数的值一定是主要元素的值),就可以判断是否存在主要元素了。
当然不限制空间复杂度的话可以直接用哈希表计数可以判断。在限制空间复杂度的时候有一个很有意思的算法,遇到过很多次了,每一次再遇到都会觉得不太容易能想到,具体可以参考LeetCode的题解:https://leetcode-cn.com/problems/find-majority-element-lcci/solution/zhu-yao-yuan-su-by-leetcode-solution-xr1p/
总结
算法参考屈婉玲老师的《算法设计与分析》(第2版),关于分治,里面还有一些更深入的算法,比如快速傅里叶变换和最近邻点对等等。码字不易,重新整理一遍对自己的理解也有很大帮助。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









