







 本文展示了如何使用Python的selenium和requests模块爬取豆瓣网站中关于意大利留学的小组标题和URL。首先,通过selenium模拟浏览器滚动和点击"显示更多",抓取所有相关数据;其次,使用requests发送GET请求,根据请求参数变化获取不同页面内容。最终,爬取到的数据保存到CSV文件中。
本文展示了如何使用Python的selenium和requests模块爬取豆瓣网站中关于意大利留学的小组标题和URL。首先,通过selenium模拟浏览器滚动和点击"显示更多",抓取所有相关数据;其次,使用requests发送GET请求,根据请求参数变化获取不同页面内容。最终,爬取到的数据保存到CSV文件中。
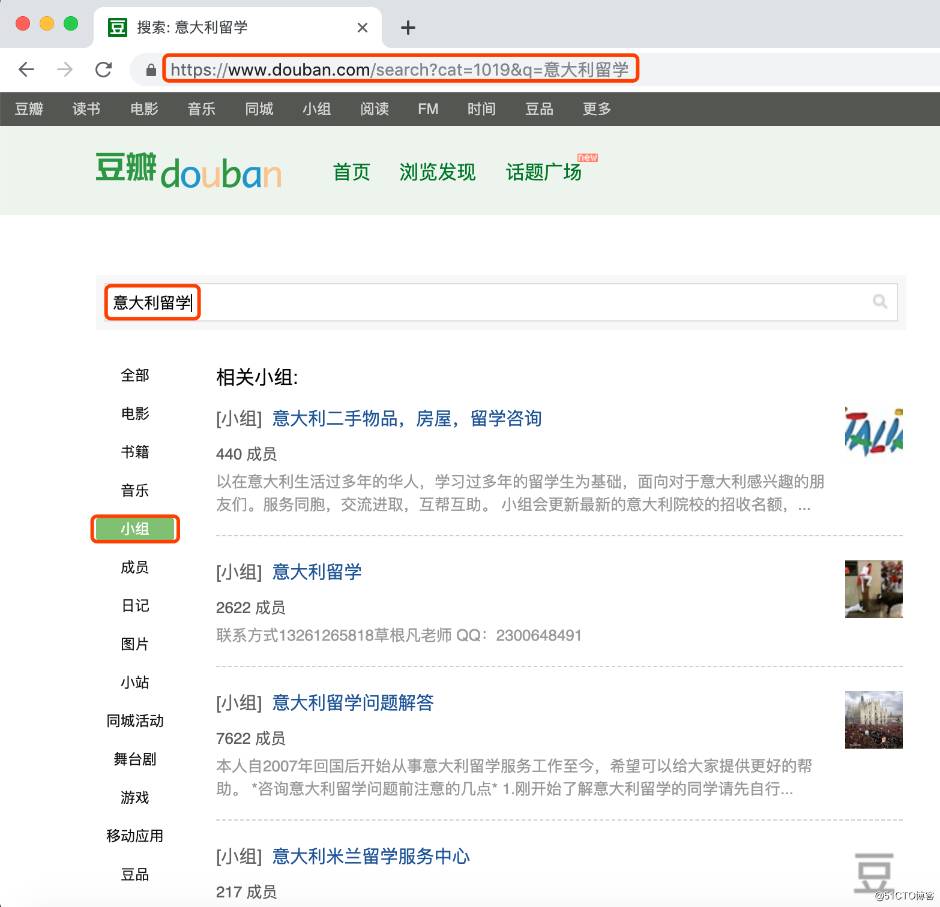
如上图,当前我想要爬取豆瓣的小组中,涉及到意大利留学内容的全部的小组标题和对应的 URL。这里利用 Python 脚本,分别使用两种方式爬取我须要的内容。两个脚本分别以下:html
使用 selenium 模块爬取
# -*- coding: utf-8 -*-
# python3.6
import csv
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class DouBan:
def __init__(self, search_field):
self.search_filed = search_field
self.url = 'https://www.douban.com/search?cat=1019&q={}'.format(self.search_filed)
self.result_data = {}
def get_data(self):
driver = webdriver.Chrome()
driver.get(self.url)
wait = WebDriverWait(driver, timeout=2, poll_frequency=0.5)
# 若是不使用向url添加搜索字段的方式,也能够使用如下两行注释代码的这种方式,让selenium自动输入内容进行搜索
# driver.find_element_by_xpath("//input[@placeholder='搜索你感兴趣的内容和人']").send_keys('意大利留学'.decode('utf-8
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









