






C++性能优化(十) —— JeMalloc
一、JeMalloc简介
1、JeMalloc简介
JeMalloc 是一款内存分配器,最大的优点在于多线程情况下的高性能以及内存碎片的减少。
GitHub地址:
https://github.com/jemalloc/jemalloc
2、JeMalloc安装
JeMalloc源码下载:
git clone https://github.com/jemalloc/jemalloc.git
构建工具生成:
autogen.sh
编译选项配置:
configure
编译:
make -j4
安装:
make install
二、JeMalloc架构
1、JeMalloc架构简介
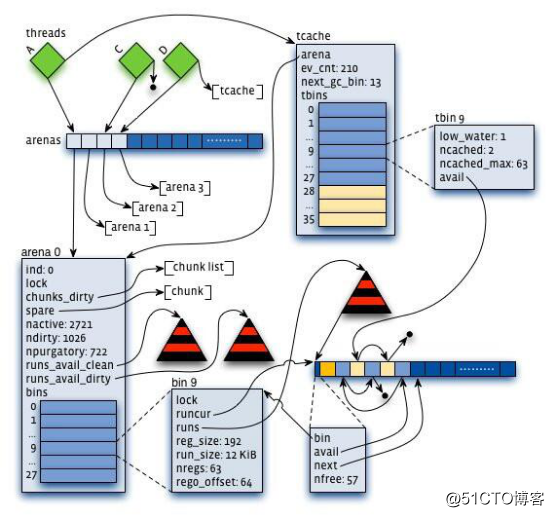
JeMalloc将内存分成多个相同大小的chunk,数据存储在chunks中;每个chunk分为多个run,run负责请求、分配相应大小的内存并记录空闲和使用的regions的大小。
2、Arena
Arena是JeMalloc的核心分配管理区域,对于多核系统,会默认分配4x逻辑CPU的Arena,线程采取轮询的方式来选择相应的Arena来进行内存分配。
每个arena内都会包含对应的管理信息,记录arena的分配情况。arena都有专属的chunks, 每个chunk的头部都记录chunk的分配信息。在使用某一个chunk的时候,会把chunk分割成多个run,并记录到bin中。不同size class的run属于不同的bin,bin内部使用红黑树来维护空闲的run,run内部使用bitmap来记录分配状态。
JeMalloc使用Buddy allocation 和 Slab allocation 组合作为内存分配算法,使用Buddy allocation将Chunk划分为不同大小的 run,使用 Slab allocation 将run划分为固定大小的 region,大部分内存分配直接查找对应的 run,从中分配空闲的 region,释放则标记region为空闲。
run被释放后会和空闲的、相邻的run进行合并;当合并为整个 chunk 时,若发现有相邻的空闲 chunk,也会进行合并。
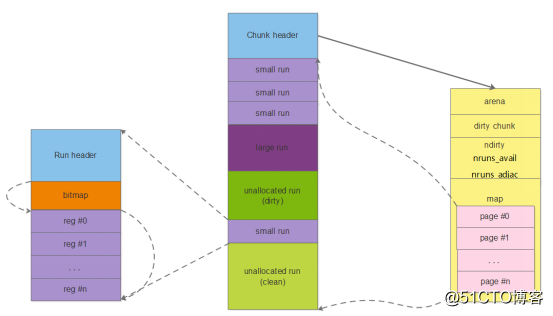
3、Chunk
Chunk是JeMalloc进行内存分配的单位,默认大小4MB。Chunk以Page(默认为4KB)为单位进行管理,每个Chunk的前6个Page用于存储后面其它Page的状态,比如是否待分配还是已经分配;而后面其它Page则用于进行实际的分配。
4、Bin
JeMalloc 中 small size classes 使用 slab 算法分配,会有多种不同大小的run,相同大小的run由bin 进行管理。
run是分配的执行者, 而分配的调度者是bin,bin负责记录当前arena中某一个size class范围内所有non-full run的使用情况。当有分配请求时,arena查找相应size class的bin,找出可用于分配的run,再由run分配region。由于只有small region分配需要run,因此bin也只对应small size class。
在arena中, 不同bin管理不同size大小的run,在任意时刻, bin中会针对当前size保存一个run用于内存分配。
5、Run
Run是chunk的一块内存区域,大小是Page的整数倍,由bin进行管理,比如8字节的bin对应的run就只有1个page,可以从里面选取一个8字节的块进行分配。
small classes 从 run 中使用 slab 算法分配,每个 run 对应一块连续的内存,大小为 page size 倍数,划分为相同大小的 region,分配时从run 中分配一个空闲 region,释放时标记region为空闲,重复使用。
run中采用bitmap记录分配区域的状态,bitmap能够快速计算出第一块空闲区域,且能很好的保证已分配区域的紧凑型。
6、TCache
TCache是线程的私有缓存空间,在分配内存时首先从tcache中分配,避免加锁;当TCache没有空闲空间时才会进入一般的分配流程。
每个TCache内部有一个arena,arena内部包含tbin数组来缓存不同大小的内存块,但没有run。
三、JeMalloc内存分配
1、JeMalloc内存分配
JeMalloc基于申请内存的大小把内存分配分为三个等级:small、large、huge。
Small objects的size以8字节、16字节、32字节等分隔开的,小于Page大小。
Large objects的size以Page为单位, 等差间隔排列,小于chunk(4MB)的大小。
Huge objects的大小是chunk大小的整数倍。
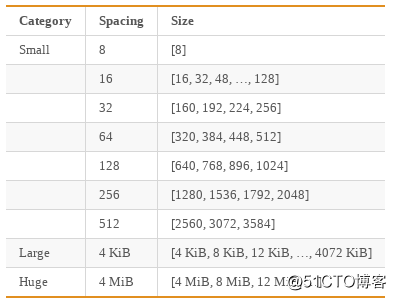
JeMalloc通过将内存划分成大小相同的chunk进行管理,chunk的大小为2的k次方,大于Page大小。Chunk起始地址与chunk大小的整数倍对齐,可以通过指针操作在常量时间内找到分配small/large objects的元数据,在对数时间内定位到分配huge objects的元数据。为了获得更好的线程扩展性,JeMalloc采用多个arenas来管理内存,减少了多线程间的锁竞争。每个线程独立管理自己的内存arena,负责small和large的内存分配,线程按第一次分配small或者large内存请求的顺序Round-Robin地选择arena。从某个arena分配的内存块,在释放时一定会回到原arena。JeMalloc引入线程缓存来解决线程间的同步问题,通过对small和large对象的缓存,实现通常情况下内存的快速申请和释放。
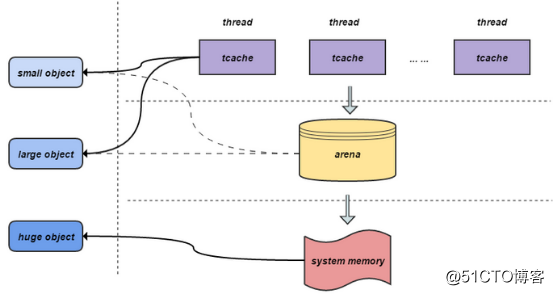
2、small内存分配
如果请求内存size不大于arena的最小的bin,那么通过线程对应的tcache来进行分配。
small objects分配流程如下:
(1)查找对应 size classes 的 bin
(2)从 bin 中获取未满的run。
(3)从 arena 中获取空闲run。
(4)从 run 中返回一个空闲 region。
3、large内存分配
如果请求内存size大于arena的最小的bin,同时不大于tcache能缓存的最大块,也会通过线程对应的tcache来进行分配,但方式不同。
如果tcache对应的tbin里有缓存块,直接分配;如果没有,从chunk里直接找一块相应的page整数倍大小的空间进行分配;
4、Huge内存分配
如果请求分配内存大于chunk(4MB)大小,直接通过mmap进行分配。
四、多线程支持
1、JeMalloc多线程支持
JeMalloc对于多线程内存分配与单线程相同,每个线程从 Arena 中分配内存,但多线程间需要同步和竞争,因此提高多线程内存分配性能方法如下:
(1)减少锁竞争。缩小临界区,使用更细粒度锁。
(2)避免锁竞争。线程间不共享数据,使用局部变量、线程特有数据(tsd)、线程局部存储(tls)等。
2、Arena选择
JeMalloc会创建多个Arena,每个线程由一个Arena 负责。JeMalloc默认创建4x逻辑CPU个Arena。
arena->nthreads 记录负责的线程数量。
每个线程分配时会首先调用arena_choose选择一个arena来负责线程的内存分配。线程选择 arena 的逻辑如下:
(1)如果有空闲的(nthreads==0)已创建arena,则选择空闲arena。
(2)若还有未创建的arena,则选择新创建一个arena。
(3)选择负载最低的arena (nthreads 最小)。
3、线程锁
线程锁尽量使用 spinlock,减少线程间的上下文切换。Linux操作系统可以在编译时通过定义JEMALLOC_OSSPIN宏可以指定使用自选锁。
为了缩小临界区,arena 中提供多个细粒度锁管理不同部分:
(1)arenas_lock: arena 的初始化、分配等
(2)arena->lock: run 和 chunk 的管理
(3)arena->huge_mtx: huge object 的管理
(4)bin->lock: bin 中的操作
4、tsd
当选择完arena后,会将arena绑定到tsd中,直接从tsd中获取arena。
tsd用于保存每个线程本地数据,主要arena和tcache,避免锁竞争。tsd_t中的数据会在第一次访问时延迟初始化,tsd 中各元素使用宏生成对应的 get/set 函数来获取/设置,在线程退出时,会调用相应的 cleanup 函数清理。
5、tcache
tcache 用于 small object和 large object的分配,避免多线程同步。
tcache 使用slab内存分配算法分配内存:
(1)tcache中有多种bin,每个bin管理一个size class。
(2)当分配时,从对应bin中返回一个cache slot。
(3)当释放时,将cache slot返回给对应的bin。
6、线程退出
线程退出时,会调用 tsd_cleanup() 对 tsd 中数据进行清理:
(1)arena,降低arena负载(arena->nthreads--)
(2)tcache,调用tcache_bin_flush_small/large释放 tcache->tbins[]所有元素,释放tcache。
当从一个线程分配的内存由另一个线程释放时,内存还是由原先arena来管理,通过chunk的extent_node_t来获取对应的arena。
五、JeMalloc使用指南
1、JeMalloc库简介
JeMalloc提供了静态库libjemalloc.a和动态库libjemalloc.so,默认安装在/usr/local/lib目录。
2、JeMalloc动态方式
通过-ljemalloc将JeMalloc链接到应用程序。
通过LD_PRELOAD预载入JeMalloc库可以不用重新编译应用程序即可使用JeMalloc。
LD_PRELOAD="/usr/lib/libjemalloc.so"
3、JeMalloc静态方式
在编译选项的最后加入/usr/local/lib/libjemalloc.a链接静态库。
4、JeMalloc生效
jemalloc利用malloc的hook来对代码中的malloc进行替换。
JEMALLOC_EXPORT void (*__free_hook)(void *ptr) = je_free;
JEMALLOC_EXPORT void *(*__malloc_hook)(size_t size) = je_malloc;
JEMALLOC_EXPORT void *(*__realloc_hook)(void *ptr, size_t size) = je_realloc;
5、JeMalloc测试
malloc.cpp:
#include
#include
#include
#include
#include
#define MAX_OBJECT_NUMBER (1024)
#define MAX_MEMORY_SIZE (1024*100)
struct BufferUnit{
int size;
char* data;
};
struct BufferUnit buffer_units[MAX_OBJECT_NUMBER];
void MallocBuffer(int buffer_size) {
for(int i=0; i
if (NULL != buffer_units[i].data) continue;
buffer_units[i].data = (char*)malloc(buffer_size);
if (NULL == buffer_units[i].data) continue;
memset(buffer_units[i].data, 0x01, buffer_size);
buffer_units[i].size = buffer_size;
}
}
void FreeHalfBuffer(bool left_half_flag) {
int half_index = MAX_OBJECT_NUMBER / 2;
int min_index = 0;
int max_index = MAX_OBJECT_NUMBER-1;
if (left_half_flag)
max_index = half_index;
else
min_index = half_index;
for(int i=min_index; i<=max_index; ++i) {
if (NULL == buffer_units[i].data) continue;
free(buffer_units[i].data);
buffer_units[i].data = NULL;
buffer_units[i].size = 0;
}
}
int main() {
memset(&buffer_units, 0x00, sizeof(buffer_units));
int decrease_buffer_size = MAX_MEMORY_SIZE;
bool left_half_flag = false;
time_t start_time = time(0);
while(1) {
MallocBuffer(decrease_buffer_size);
FreeHalfBuffer(left_half_flag);
left_half_flag = !left_half_flag;
--decrease_buffer_size;
if (0 == decrease_buffer_size) break;
}
FreeHalfBuffer(left_half_flag);
time_t end_time = time(0);
long elapsed_time = difftime(end_time, start_time);
printf("Used %ld seconds. \n", elapsed_time);
return 1;
}
使用TCMalloc编译链接:
g++ malloc.cpp -o test -ljemalloc
执行test,耗时558秒。
使用默认GLibc编译链接:
g++ malloc.cpp -o test
执行test,耗时744秒。














 9187
9187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









