







1. 概述
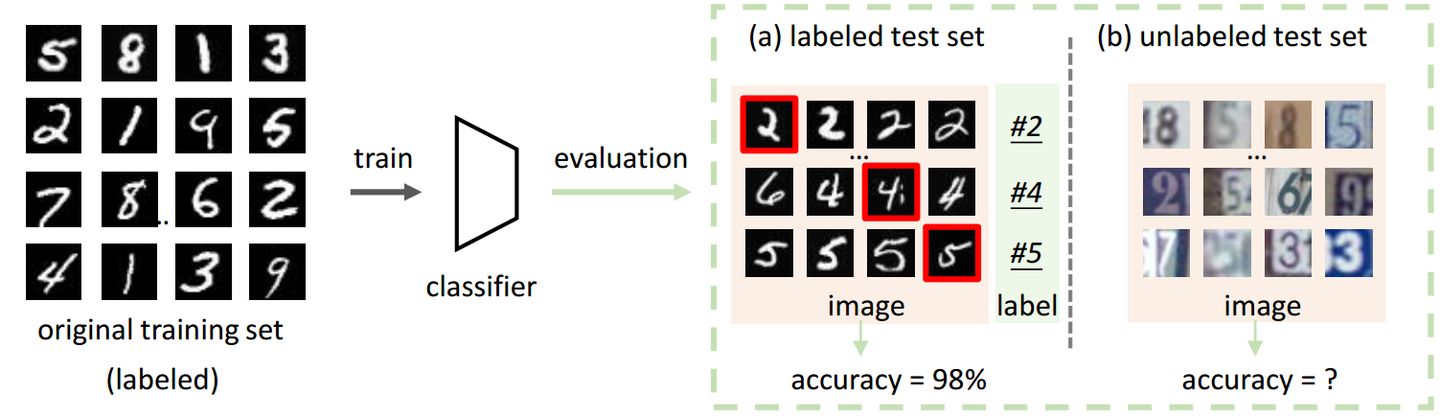
为了评估一个模型在计算机视觉任务(例如目标识别)上的表现,我们通常需要一个有标注且训练不可见的测试集合。大多数情况下,我们都默认这个带标注测试集合的存在(比如各种常用的数据benchmarks)。然而,在许多实际场景中,数据的标注往往很难获取(成本、标注难度等等),进而使得我们难以快速了解模型的性能。那么,测试集没有标签,我们可以拿来测试模型吗?
我们重点研究自动模型评估(AutoEval)这一重要的且尚未开发的问题。具体来说,给定带标签的训练集和分类器,我们需要估计出分类器在未标记的测试数据集上的分类准确性。围绕这一问题,我们从数据分布差异角度提出解决方案。方法的出发点是:测试集合和训练集合数据分布差异越大,那么分类器在测试集合上的准确率就会越低。为此,我们采用回归模型来估计分类器的性能。回归器的输入为一个测试集与数据分布差异相关的特征(如均值和协方差),输出为分类器在其上的准确率。我们发现回归器可以较为准确地预测分类器在不同测试集合上的表现,进而能很好地帮助我们理解分类器在不同测试场景下的性能表型。
Are Labels Necessary for Classifier Accuracy Evaluation?arxiv.org2. 自动模型评估
该问题的主旨
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2339
2339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









