







grouping sets 在一个 group by 查询中,根据不同的维度组合进行聚合,等价于将不同维度的 group by 结果集进行 union all
cube 根据 group by 的维度的所有组合进行聚合
rollup 是 cube 的子集,以最左侧的维度为主,从该维度进行层级聚合。
grouping sets
select order_id, departure_date, count(*) as cnt
from ord_test
group by order_id, departure_date
grouping sets (order_id,(order_id,departure_date)); ---- 等价于以下
group by order_id union all group by order_id,departure_date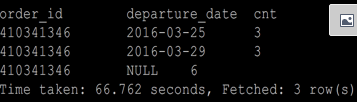
cube
select
order_id,
departure_date,
count(*) as cnt
from ord_test
group by order_id,
departure_date
with cube;
---- 等价于以下
select count(*) as cnt from ord_test
union all
group by order_id
union all
group by departure_date
union all
group by order_id,departure_date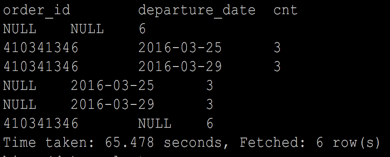
rollup
select order_id,
departure_date,
count(*) as cnt
from ord_test
group by order_id,
departure_date
with rollup;
---- 等价于以下
select count(*) as cnt from ord_test
union all
group by order_id
union all
group by order_id,departure_date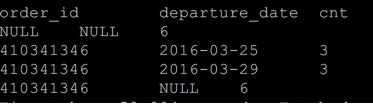
grouping__id
当使用多维聚合后,如何知道当前行统计是基于哪些维度的呢?这时就需要 grouping__id了
grouping__id 是 hive 生成的,标识维度组合的十进制数字。规则如下:
- 将 group by 后的所有字段 倒序 排列。
- 对于每个字段,如果该字段出现在了当前粒度中,则该字段位置赋值为1,否则为0,形成一个二进制数据。
- 将2中的二进制数转为十进制,即为当前粒度对应的 grouping__id值 。















 406
406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









