







(由Python大本营付费下载自视觉中国)
作者 | ayuliao
出自 | hackpython (ID:hackpython)
简介 大脑是人类目前所知的最复杂的器官,为了很好的了解大脑这个器官,我们做了很多努力,核磁共振成像 (Magnetic Resonance Image,MRI) 技术就是其中的重要突破,通过 MRI 的方式,我们可以获得大脑的一些数据。 近年来,随着机器学习的兴起,医学数据与机器学习结合使用的情况越来越多,而要有效的使用好医学数据,其前提就是处理好这些数据,本文内容会重点介绍如何使用 Python 来处理与分析这些脑成像数据,不会涉及过多医学知识。 1 sMRI 与 fMRI 脑成像相关的数据可以去 SPM 网站中下载,SPM 的含义是统计参数映射 (Statistical Paramtric Mapping),MRI 生成的数据其实就是一种参数映射数据,当然,更加方便的是在工作公众号中回复 data3 获得相应的数据与 jupyter 代码文件。 下载后,其中有 4 个文件,其中 README 开头的为描述文件,fM00223 为功能性核磁共振 (funciton MRI,fMRI) 成像数据,sM00223 为结构性核磁共振 (structural MRI, sMRI) 成像数据。通过描述文件可知,这些数据是一个人躺在 MRI 机器上听「双音节词」时大脑的成像数据。 为了方便理解后面数据处理的内容,有必要理解 sMRI 与 fMRI 是什么以及两者的差异。 2 结构性核磁共振 (sMRI) 因为人的体内存有大量的水分子,而水分子中还有氢原子,sMRI 其实就是利用氢原子来成像,这意味着人身体中的内脏、软组织等含有高水分与脂肪的器官会被清楚的扫描出来,而大脑就是这样的一个器官,通过 sMRI 可以清晰的看到大脑中的密集结构与大量细节,但 sMRI 的成像无法观察到大脑的运动情况,即无法判断那些部位目前是比较活跃的,只能给出大脑的结构细节。 如下图,科学家利用 sMRI 对人体腹腔进行成像,从图可以看出,腹腔的结构很明显。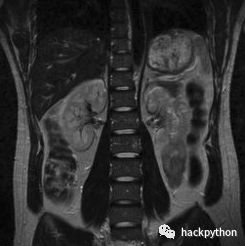
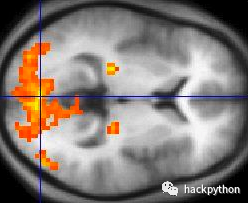 但从图中可以看出,大脑的细节几乎看不清晰,所以目前常规的方式是使用 sMRI 对大脑结构进行成像,而 fMRI 对大脑活跃区域进行成像。
4 sMRI 数据可视化处理
通常,神经影像文件都会以相应的规律将数据存储在固定文件格式的文件中,我们可以通过 NiBabel 库来读 / 写常见的神经影像文件中的数据。
sMRI 对应的数据在 sM00223 文件夹下,进入文件夹可以发现有两种不同文件格式的数据,分别是.img 与.hdr,这其实是医学影像领域常见的格式,主要用于「分析」,其中,.img 作为数据文件,包含二进制的图像资料,而.hdr 作为头文件,包含图像的元数据,但这两种格式现在逐渐被.nifti 格式代替,这是因为.hdr 头文件难以完全真实反映元数据。
但从图中可以看出,大脑的细节几乎看不清晰,所以目前常规的方式是使用 sMRI 对大脑结构进行成像,而 fMRI 对大脑活跃区域进行成像。
4 sMRI 数据可视化处理
通常,神经影像文件都会以相应的规律将数据存储在固定文件格式的文件中,我们可以通过 NiBabel 库来读 / 写常见的神经影像文件中的数据。
sMRI 对应的数据在 sM00223 文件夹下,进入文件夹可以发现有两种不同文件格式的数据,分别是.img 与.hdr,这其实是医学影像领域常见的格式,主要用于「分析」,其中,.img 作为数据文件,包含二进制的图像资料,而.hdr 作为头文件,包含图像的元数据,但这两种格式现在逐渐被.nifti 格式代替,这是因为.hdr 头文件难以完全真实反映元数据。
import nibabel# sM0223对应的文件data_path = './fMRI_data/sM00223/'files = os.listdir(data_path)# 读取其中的数据data_all = []for data_file in files: if data_file[-3:] == 'hdr': data = nibabel.load(data_path + data_file).get_data()# 打印数据维数print(data.shape)# -------结果(256, 256, 54, 1)体素:类似像素,像素表示的是二维图像的最小单位,而体素则用于三维成像空间。
为了方面可视化每个切片的数据,可以简单处理一下数据:import numpy as npdata = np.rot90(data.squeeze(), 1)print(data.shape)# -------结果(256, 256, 54)import matplotlib.pyplot as plt
# 创建 6 个子图,不清楚其中概念,可以看本公众号关于Matplotlib的文章
fig, ax = plt.subplots(1, 6, figsize=[18, 3])
n = 0
slice = 0
for _ in range(6):
ax[n].imshow(data[:, :, slice], 'gray')
ax[n].set_xticks([])
ax[n].set_yticks([])
ax[n].set_title('Slice number: {}'.format(slice), color='r')
n += 1
slice += 10
fig.subplots_adjust(wspace=0, hspace=0)
plt.show()
 这就是通过 sMRI 数据绘制出的大脑结构图了,其中第 0 层切片是最低的一个 (接近脖子位置),而第 50 层切片是最高的一个 (接近头顶),在第 20 层,可以看具有眼睛的切片。
5 fMRI 数据可视化处理
阅读 README.txt 可知 fM00223 数据集中,每张图像的大小为 64x64 个体素,采集的片数为 64 以及采集的卷数为 96。知道了这些信息,就可以对 fM00223 数据集中的数据进行重构。
打开 fM00223 文件夹,可以发现确实正好有 96 个 Hdr 文件,这意味着每个文件包含了一个卷的所有片。
这就是通过 sMRI 数据绘制出的大脑结构图了,其中第 0 层切片是最低的一个 (接近脖子位置),而第 50 层切片是最高的一个 (接近头顶),在第 20 层,可以看具有眼睛的切片。
5 fMRI 数据可视化处理
阅读 README.txt 可知 fM00223 数据集中,每张图像的大小为 64x64 个体素,采集的片数为 64 以及采集的卷数为 96。知道了这些信息,就可以对 fM00223 数据集中的数据进行重构。
打开 fM00223 文件夹,可以发现确实正好有 96 个 Hdr 文件,这意味着每个文件包含了一个卷的所有片。
# fMRI数据的基本信息x_size = 64y_size = 64n_slice = 64n_volumes = 96# 获得所有文件data_path = './fMRI_data/fM00223/'files = os.listdir(data_path)# 读取数据并进行重塑data_all = []for data_file in files: if data_file[-3:] == 'hdr': data = nibabel.load(data_path + data_file).get_data() # 将所有数据添加到list中,从而多了一个维度:时间维度 data_all.append(data.reshape(x_size, y_size, n_slice))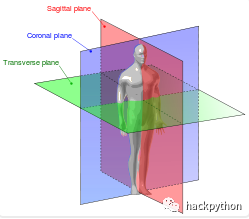 ◆ 冠状面为左,右方向将人体纵切为前后两部分的断面
◆ 横切面指横向水平切割的平面
◆ 矢状面是指将躯体纵断为左右两部分的解剖平面
看一下下面的代码:
◆ 冠状面为左,右方向将人体纵切为前后两部分的断面
◆ 横切面指横向水平切割的平面
◆ 矢状面是指将躯体纵断为左右两部分的解剖平面
看一下下面的代码:
# 创建 3x6 的子图,大小为 18x11
fig, ax = plt.subplots(3, 6, figsize=[18, 11])
# 组织数据以冠状平面进行可视化,第四维度为时间维度,这里取第一个时间点
coronal = np.transpose(data_all, [1, 3, 2, 0])
coronal = np.rot90(coronal, 1)
# 组织数据以横切平面进行可视化
transversal = np.transpose(data_all, [2, 1, 3, 0])
transversal = np.rot90(transversal, 2)
# 组织数据以矢状平面进行可视化
sagittal = np.transpose(data_all, [2, 3, 1, 0])
sagittal = np.rot90(sagittal, 1)
# 可视化不同平面
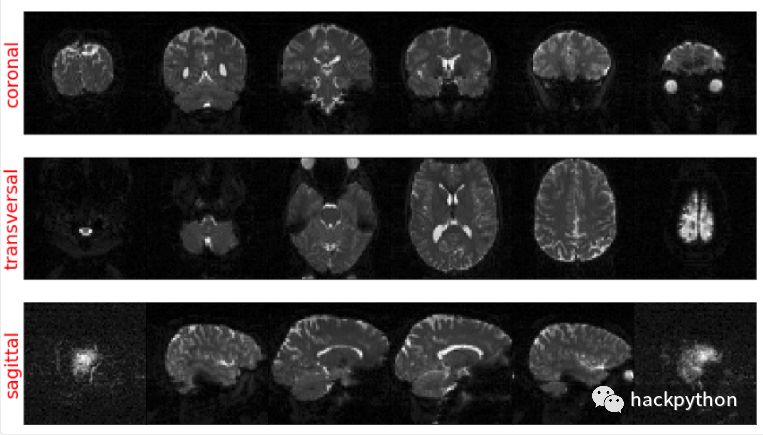
n = 10
# 对每个切片的6个切面进行操作
for i in range(6):
ax[0][i].imshow(coronal[:, :, n, 0], cmap='gray')
ax[0][i].set_xticks([])
ax[0][i].set_yticks([])
if i == 0:
ax[0][i].set_ylabel('coronal', fontsize=25, color='r')
n += 10
n = 5
for i in range(6):
ax[1][i].imshow(transversal[:, :, n, 0], cmap='gray')
ax[1][i].set_xticks([])
ax[1][i].set_yticks([])
if i == 0:
ax[1][i].set_ylabel('transversal', fontsize=25, color='r')
n += 10
n = 5
for i in range(6):
ax[2][i].imshow(sagittal[:, :, n, 0], cmap='gray')
ax[2][i].set_xticks([])
ax[2][i].set_yticks([])
if i == 0:
ax[2][i].set_ylabel('sagittal', fontsize=25, color='r')
n += 10
fig.subplots_adjust(wspace=0, hspace=0)
plt.show()
 尾
参考:
https://medium.com/coinmonks/visualizing-brain-imaging-data-fmri-with-python-e1d0358d9dba
(*本文为Python大本营转载文章,转载请联系原作者)
尾
参考:
https://medium.com/coinmonks/visualizing-brain-imaging-data-fmri-with-python-e1d0358d9dba
(*本文为Python大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
 推荐阅读
推荐阅读
周杰伦的《说好不哭》,20万点评Python来分析
Python微信远程控制摄像头-拍摄女朋友坐电脑前聊天时表情
5大必知的图算法,附Python代码实现
吐血整理!140种Python标准库、第三方库和外部工具都有了
如何用爬虫技术帮助孩子秒到心仪的幼儿园(基础篇)
Python传奇:30年崛起之路
2019年最新华为、BAT、美团、头条、滴滴面试题目及答案汇总
阿里巴巴杨群:高并发场景下Python的性能挑战
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢














 2966
2966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









