







1.SELECT --group by 子句

group by子句按照指定的列column_name对表数据进行分组
group by 后面跟的列也叫分组特性列
使用group by后,能选择的列 通常只能包括分组特性列和聚合函数
聚合函数 ???
1.按照班号分组,列出学生表中的班号 (注意:按照班号进行分组,班号就不会有重复值)
select cno from stugroup bycno;cno分组特性列

2.按照班号分组,列出学生表中的班号,还要列出学生姓名
select sname,cno from stu group by cno;
查询报错
注意:学生有20人,姓名一共20行记录,班号分组去重后有4行记录,20行无法与4行拼接在一起
使用group by后,能选择的列通常只能包括分组特性列和聚合函数
除非用group_concat字符串聚合函数把每个班的学生姓名变成字符串,每个班一行:
select cno,group_concat(sname) from stu group by cno;

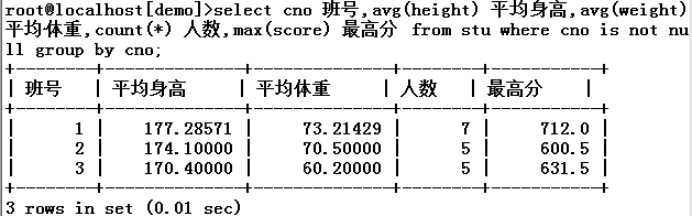
3.按照班号分组,列出学生表中的班号,统计每个班的平均身高,平均体重,人数,最高分,不包括未分班的那些同学
select cno 班号,avg(height) 平均身高,avg(weight) 平均体重,count(*) 人数,max(score) 最高分 from stu where cno is not null group by cno;
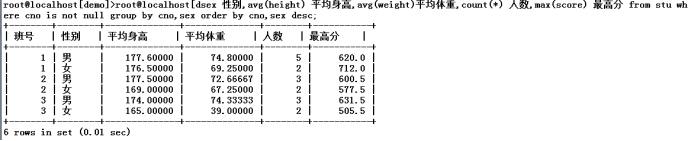
4.先按照班号分组,再按照性别分组,列出学生表中的班号和性别,统计出每个班男女生的平均身高,平均体重,人数,最高分,不包括未分班的那些同学,结果先按班号,再按照男女s的顺序排序
select cno 班号,sex 性别,avg(height) 平均身高,avg(weight) 平均体重,count(*) 人数,max(score) 最高分 from stuwhere cno is not nullgroup bycno,sex order by cno,sex desc;
5.按照学生出生年份分组,统计出所有学生每个年份的人数,最高分,最低分,按照年份排序
select year(birth) 出生年份,count(sno) 人数,max(score) 最高分, min(score) 最低分 from stu group by year(birth) order by 1;+分组特性列和函数

2.SELECT - HAVING子句

HAVING子句是对group by产生的结果集的过滤
HAVING子句可以对分组特性列column_name进行过滤,也可以对聚合函数(aggregate_function(列))的值进行过滤
1.按照学生出生年份分组,统计出所有学生每个出生年份的人数,最高分,最低分,按照年份排序,并从结果中找出人数超过2个,并且最高分有超过700分的年份分组
select year(birth) 出生年份,count(sno) 人数,max(score) 最高分, min(score) 最低分 from stu group by year(birth) having count(*)>2 and max(score)>700 order by 1;
分组特性列+分组函数having有 where没有
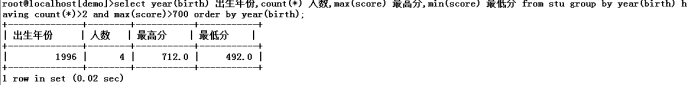
2.已分班的学生中,哪些班学生的平均身高超过175,列出其班号和人数
select cno 班号,count(*) 人数 from stu where cno is not null group by cno having avg(height)>175 order by 1;

已分班的学生中,哪些班的学生每个人的体重都超过50公斤,列出其班号和人数
select cno 班号,count(*) 人数 from stu where cno is not null group by cno having min(weight)>50 order by 1;

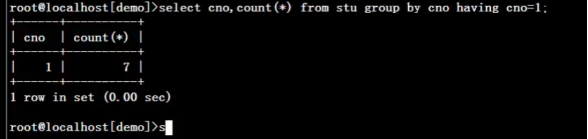
统计1班的学生人数,列出班号和人数
select cno 班号,count(*) 人数 from stu group by cno having cno=1;
或者
select 1 班号,count(*) 人数 from stu where cno=1;
第一种方法先使用group by统计,再用having过滤统计结果,统计了和1班不相干的其他班级的人数,浪费了系统CPU资源,效率低;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3088
3088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









