







1.简介
Kafka是一个分布式消息系统,使用Scala语言进行编写,具有高水平扩展以及高吞吐量特性。
目前流行的消息队列主要有三种:ActiveMQ、RabbitMQ、Kafka
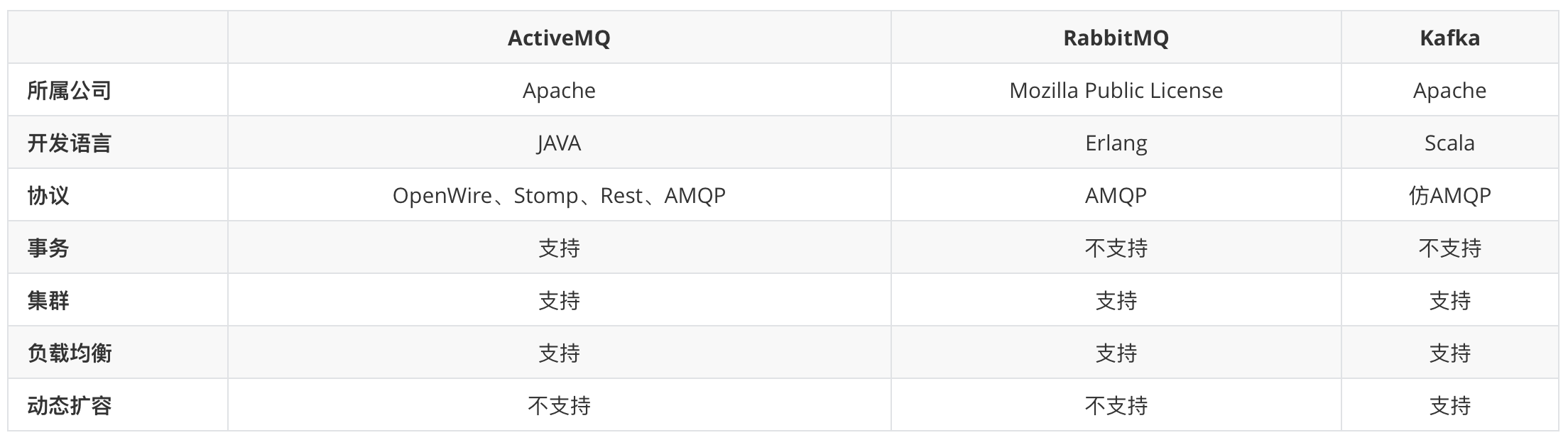
ActiveMQ、RabbitMQ均支持AMQP协议,Kafka使用仿AMQP协议,目前Flume、Storm、Spark、Elasticsearch都支持与Kafka进行集成。
动态扩容:在不需停止服务的前提下动态的增加或减少节点,Kafka的动态扩容是通过zookeeper实现的,zookeeper上保存着kafka的相关状态信息(topic、partition等)
2.关于AMQP
AMQP全称 高级消息队列协议,是一个统一消息服务的应用层协议,为面向消息的中间件所设计,基于此协议的客户端与消息中间件可相互传递消息,并不受客户端和中间件的产品以及开发语言不同所限制。
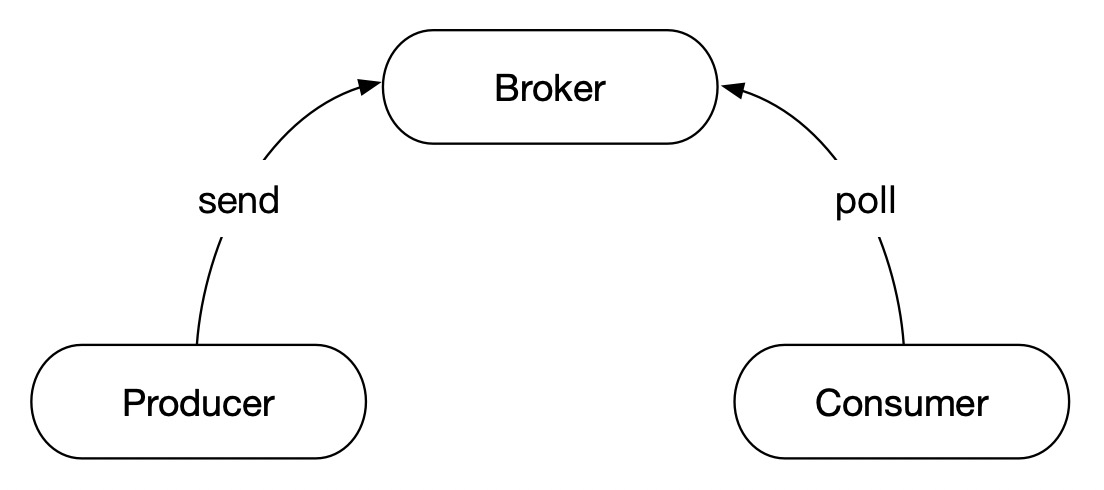
Producer负责把消息发送给Broker。
Broker负责接收并存储Producer发送的消息。
Consumer负责从Broker中消费消息。
*Broker是消息队列中最小的运行单元,一个Broker的运行就代表着一个Kafka实例。
3.Kafka的模型
1.Broker
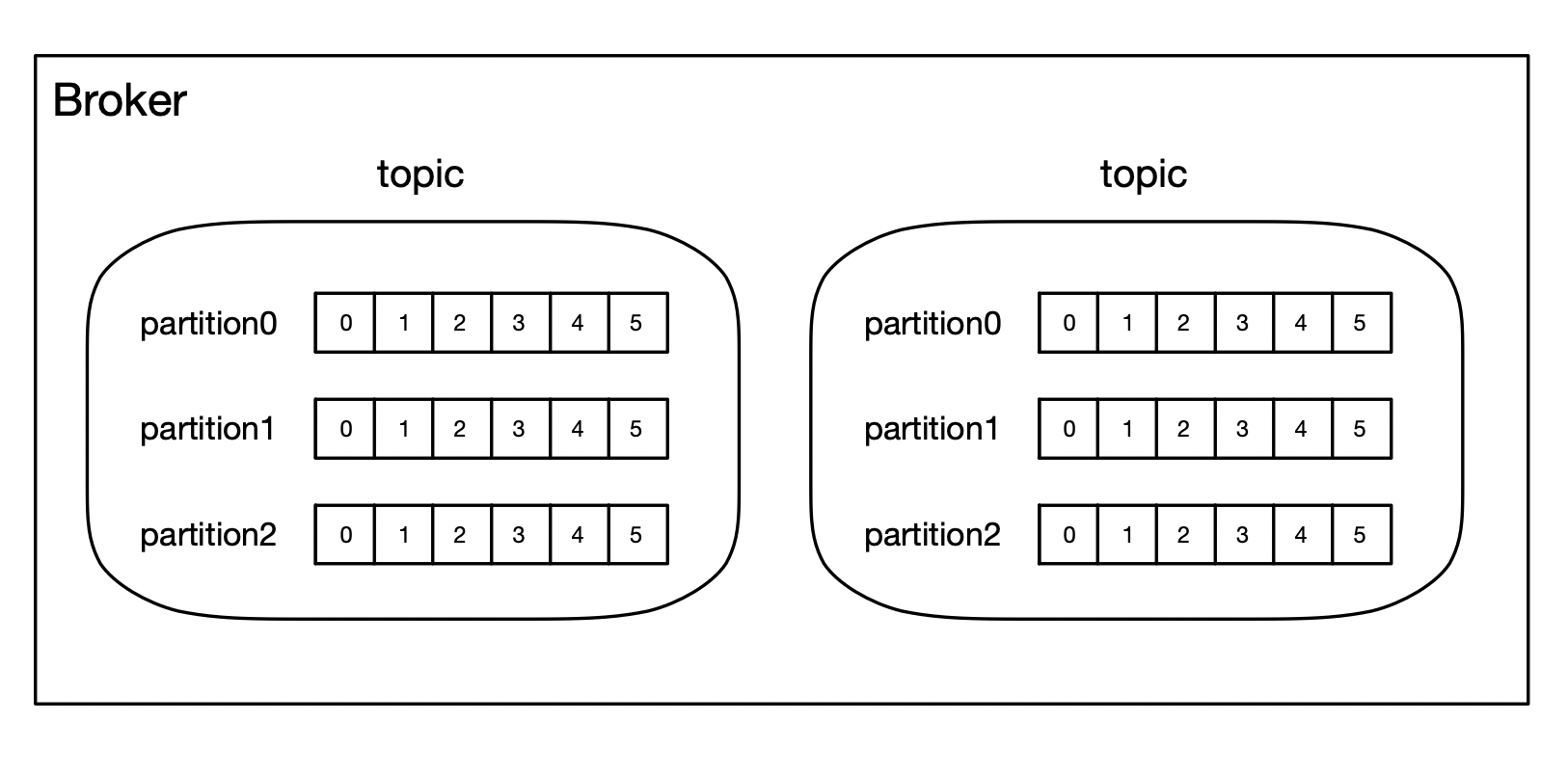
Broker中可以包含多个Topic,每个Topic下又包含多个Partition。
一个Topic(主题)类似于新闻中的体育、娱乐、等分类概念,在实际开发中通常一个业务对应一个Topic。
一个Topic下由多个Partition组成,每个Partition都是一个First In First Out的队列,用于存放Topic中的消息。
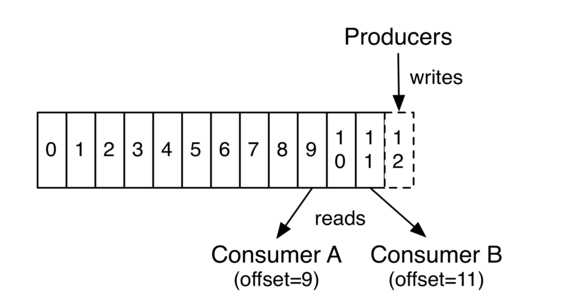
每个消息在Partition中都有一个offset(偏移量),是消息在分区中的唯一标识。
每个Consumer都需要维护一份自己的offset,用于记录当前消费的进度,然后保存到Kafka当中(Consumer可以以任意的位置开始进行读取,只需要设置offset即可)
在一个可配置的时间段内,Kafka集群将保留所有发送的消息,不管这些消息是否被被消费。
Kafka的分区是提高Kafka性能的关键手段,当Kafka集群的性能不高时,可以试着往topic中添加分区。
Kafka的分区备份
Topic下的每个Partition在Kafka集群中都有备份,在逻辑相关的一组Partition中,都有一个作为Leader,其余作为Follower,Leader和Follwer的选举都是随机的,当Follower接收到请求时首先会发送给Leader,由Leader负责消息的读和写并把消息同步给各个Follower,如果Leader所在的节点宕机,Follower中的一台则会自动成为Leader。
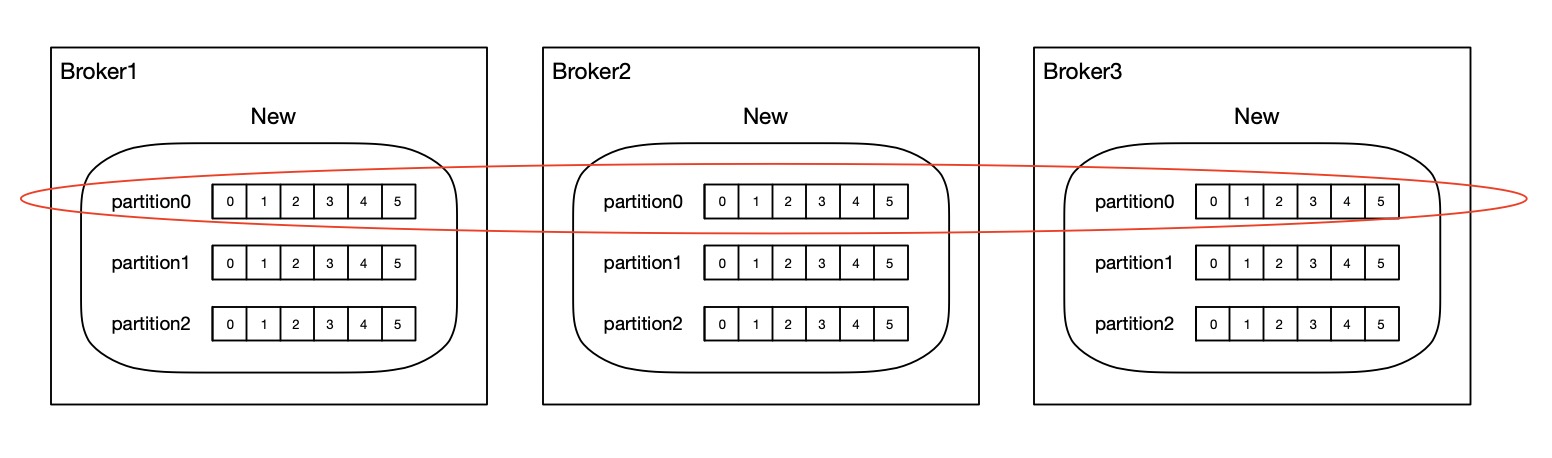
比如搭建一个Kafka集群,存在3个节点,同时设置Topic的分区数以及分区的备份数是3,现往Broker1中创建一个New Topic,那么在每个Broker实例中都会存在一个New Topic,同时每个New Topic下都会包含3个Partition,在逻辑相关的一组Partition中,都有一个作为Leader,其余作为Follower。
2.Producer
Producer向Broker中指定的Topic发送消息,消息将会根据负载均衡策略进入相应的Partition。
*Producer向Broker发送消息时,除了指定Topic以及Message以外,还可以指定一个Key,用于Partition的散列,Key相同的消息将会保存到同一个Partition当中。
3.Consumer组
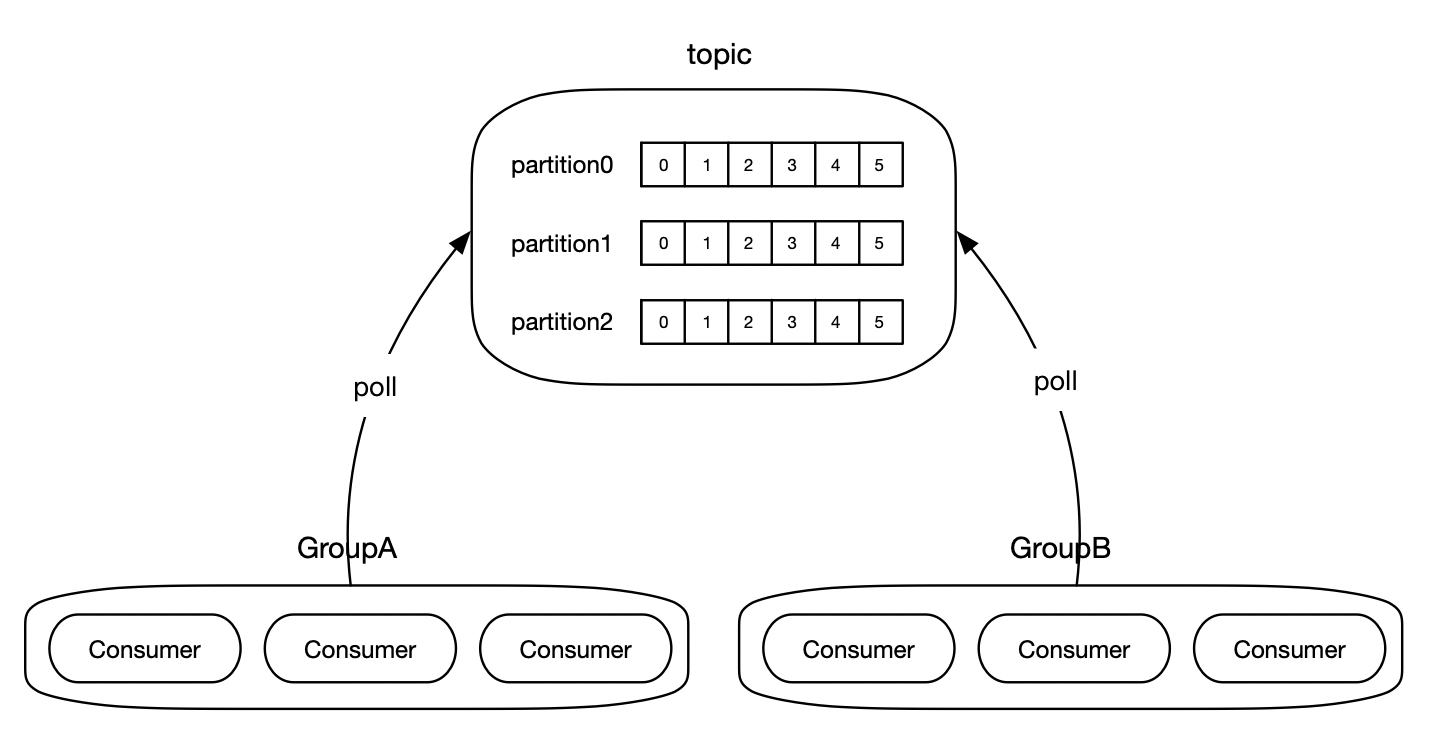
Kafka提供了Consumer组的概念,一个Consumer组下可以包含多个Consumer。
Kafka规定,Topic下的每一个Partition都只能被Consumer组下的唯一一个Consumer进行消费,以确保消费的顺序性,因此Consumer组下的Consumer数量不能超过Partition的数量,否则将会处于空闲状态。
队列模式
若所有的Consumer都在同一个Consumer组中下则成为队列模式,Topic中的各个Partition都只能被组中的唯一一个Consumer进行消费,组下的Consumer共同竞争Topic中的Partition。
广播模式
若所有的Consumer都不在同一个Consumer组中则成为广播模式,Topic中各个P
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









