






rows:根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数,,即每张表有多少行被查询。
从意思上看,rows的值越小就越好。
现在有两张表,t_jar、t_jar2,里面是我从maven中央仓库爬的一些jar包的信息。
现在看两张表的索引情况:
show index from t_jar;show index from t_jar2;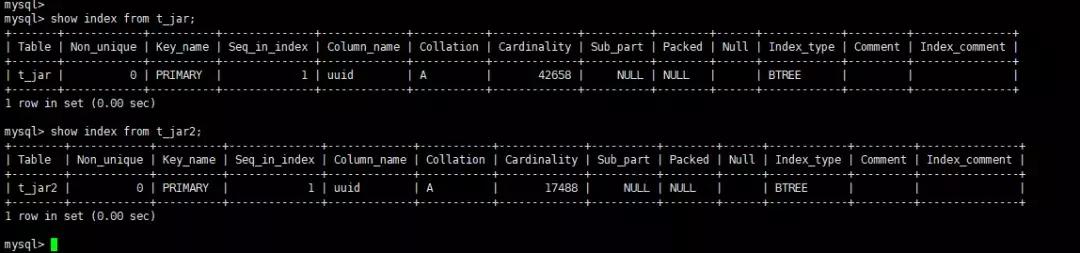
两张表目前都只有主键,没有其他索引。
看以下这条SQL:
select * from t_jar t1,t_jar2 t2
where t1.uuid = t2.uuid
and t2.name = 'java-sheaf-0.2.4-sources.jar';

两个id相等,从上往下执行。t2表先查询,它是全表查询,没有使用到索引,而估算读取行数,即rows的值是17488行。
现在给t_jar2表name字段建索引
create index index_name on t_jar2(name);再看一下上面SQL的执行计划:

t2表查询达到ref级别,这个查询理论上用到了主键和index_name索引,实际使用了index_name索引,大致读取行数rows的值现在是1。那么我们可以确定其查询速度明显有了提高,这个可以自行测试验证。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









