







流程分析
抓取内容(百度贴吧:网络爬虫吧)
页面: http://tieba.baidu.com/f?kw=%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB&ie=utf-8
数据:1.帖子标题;2.帖子作者;3.帖子回复数
通过观察页面html代码来帮助我们获得所需的数据内容。
一、工程建立
在控制台模式下进入你要建立工程的文件夹执行如下命令创建工程:
scrapy startproject hellospider
这里的scrapytest是工程名,框架会自动在当前目录下创建一个同名的文件夹,工程文件就在里边。
(如果你用过django就会发现这一幕何其相似)。
我的创建过程:

我们先看一下目录结构:
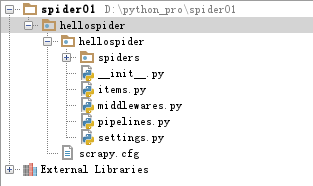
scrapy.cfg: 项目的配置文件
hellospider/: 该项目的python模块。之后您将在此加入代码。
hellospider/items.py:需要提取的数据结构定义文件。
hellospider/middle
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 523
523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









