






众所周知Redis是一款内存数据库,所有的数据都被存储在内存之中,然而如果数据仅仅被存储在内存中的话,那么一旦服务器进程出现停机,那么所有的数据都将丢失,因此Redis需要支持数据的持久化,将内存之中的数据存储在磁盘之中。当Redis进程启动时,会从磁盘之中将数据恢复到内存之中。
RDB概述
RDB持久化是Redis支持的一种持久化策略,Redis会将服务器的状态信息以及所有数据库中的数据序列化到磁盘的文件之中,相当于保存了服务器数据的一个快照。在Redis启动时,会从文件中反序列化恢复数据到内存之中。
Redis可以通过主动或者被动的方式来创建RDB文件:
主动方式,通过客户端数据的命令SAVE以及BGSAVE,来启动RDB持久化。
如果客户端执行SAVE,那么Redis会同步地生成RDB文件,此时Redis的主线程会被阻塞起来,直到RDB文件生成完成,Redis都不会响应客户端的命令请求。
如果客户端执行BGSAVE,那么Redis会异步地生成RDB文件,此时Redis会主动创建一个子进程用于生成RDB文件,而Redis此时依然可以处理客户端的其他命令请求。
被动方式,Redis检测一段时间内修改次数累积到一定的阈值时,会启动异步生成RDB文件的逻辑。
对于RDB文件的自动备份,这里需要专门介绍一下,Redis会通过下面这个结构体来描述这个自动备份的阈值:
struct saveparam {time_t seconds;int changes;
};这表示,如果Redis在saveparam.seconds秒数内累积了saveparam.changes次变化的化,便会启动备份。Redis可以保有多个这样的阈值,存储在服务器全局数据之中:
struct redisServer {
...struct saveparam *saveparams;int saveparamslen;
};同时Redis也存储了自上次备份以来被修改的数据数量以及上次备份的时间,同样保存在服务器全局数据之中:
struct redisServer {
...long long dirty;time_t lastsave;
};Redis会在服务器的心跳serverCron中,对累积的变化数据进行检测,多个阈值只要有一个满足,那么便会触发生成RDB文件的逻辑。需要注意的时,这种情况下,Redis是采用异步的方式来生成RDB文件的。
Redis在生成RDB文件时,则是使用前面我们介绍的rio对象,通过操作FILE类型的rio对象,我们可以实现内存数据到文件的序列化过程以及文件数据到内存的反序列化过程。
RDB基础数据的读写
为了实现序列化,出了需要将内存中的数据转化为一段连续数据之外,还需要附加上一个类型标记,通过这个类型标记,我们可以知道被序列化的连续数据将被反序列化为何种类型的数据。另外还需要在序列化数据之中附加上长度信息,通过这个信息,我们可以在反序列化时,确定一段完整的数据应该截止于何处。
Redis在src/rdb.h头文件之中,通过define定义了RDB序列化数据的类型:
RDB_TYPE_STRING,这个类型表示序列化的是字符串对象类型RDB_TYPE_LIST,这个类型已经不再使用RDB_TYPE_SET,这个类型表示序列化的是使用OBJ_ENCODING_HT编码方式的集合对象RDB_TYPE_ZSET,这个类型已经不再使用RDB_TYPE_HASH,这个类型表示序列化的是使用OBJ_ENCODING_HT编码方式的散列对象RDB_TYPE_ZSET_2,这个类型表示序列化的是使用OBJ_ENCODING_SKIPLIST编码方式的有序集合对象RDB_TYPE_MODULE,这个类型已经不再使用RDB_TYPE_MODULE_2,这个类型表示序列化的是Module对象数据
上述这几个类型都是用于标记对象数据类型的序列化,并且上述类型的数据都是对应底层使用哈希表或者跳跃表这类离散数据的序列化。通过前面的介绍我们知道在一些特殊的情况下,Redis会使用连续分配的内存段来事项对象数据类型,下面这几个类型的定义便是对应于这种情况:
RDB_TYPE_HASH_ZIPMAP,这个类型已经不在使用RDB_TYPE_LIST_ZIPLIST,这个类型已经不在使用RDB_TYPE_SET_INTSET,这个类型表示序列化的是使用OBJ_ENCODING_INTSET编码方式的集合对象RDB_TYPE_ZSET_ZIPLIST,这个类型表示序列化的是使用OBJ_ENCODING_ZIPLIST编码方式的有序集合对象RDB_TYPE_HASH_ZIPLIST,这个类型表示序列化的是使用OBJ_ENCODING_ZIPLIST编码方式的散列对象RDB_TYPE_LIST_QUICKLIST,这个类型表示序列化的是使用OBJ_ENCODING_QUICKLIST编码方式的列表对象RDB_TYPE_STREAM_LISTPACKS,这个类型表示序列化的是Streamdui对象数据
上述的这些对应数据对象类型的序列化类型,可以通过下面的两个函数进行读写:
int rdbSaveObjectType(rio *rdb, robj *o);int rdbLoadObjectType(rio *rdb);除了标记数据对象的序列化类型,Redis还定义了几个辅助数据序列化的类型:
RDB_OPCODE_MODULE_AUX,这个类型表示后序列化的是Module辅助数据。RDB_OPCODE_IDLE,这个类型表示后面序列化的是一个key的LRU空闲时间。RDB_OPCODE_FREQ,这个类型表示后面序列化的是一个key的LFU频率数据。RDB_OPCODE_AUX,这个类型表示后面序列化的是一个RDB的辅助数据。RDB_OPCODE_RESIZEDB,这个类型表示后面序列化的是数据库键空间的长度以及过期哈希表的长度。RDB_OPCODE_EXPIRETIME_MS,这个类型表示后面序列化的是一个key的毫秒级有效期时间戳。RDB_OPCODE_EXPIRETIME,这个类型表示后面序列化的是一个key的秒级有效时间时间戳,但是现在已经不在继续使用。RDB_OPCODE_SELECTDB,这个类型表示后面序列化的是数据库对应的编号数据。RDB_OPCODE_EOF,这个类型用于标记RDB文件的结束符。
上述这些辅助序列化的类型,可以通过下面这两个函数进行读写:
int rdbSaveType(rio *rdb, unsigned char type);int rdbLoadType(rio *rdb);上面两个rdbSaveObjectType以及rdbLoadObjectType函数也是通过rdbSaveType以及rdbLoadType来实现的。
接下来Redis定义了一些基础层数据的序列化与反序列化的操作函数,这些函数的实现细节较为简单,也较为相似,因此只简要介绍一下各个函数的含义与用途,具体的实现可以参考src/rdb.c源文件:
int rdbSaveTime(rio *rdb, time_t t);time_t rdbLoadTime(rio *rdb);int rdbSaveMillisecondTime(rio *rdb, long long t);long long rdbLoadMillisecondTime(rio *rdb, int rdbver);上述这四个函数用于实现秒数级时间戳与毫秒时间戳的读写。
int rdbSaveLen(rio *rdb, uint64_t len);uint64_t rdbLoadLen(rio *rdb, int *isencoded);int rdbLoadLenByRef(rio *rdb, int *isencoded, uint64_t *lenptr);这三个函数则是用于以压缩的方式实现长度数据的序列化与反序列化,也可以用于一个整数的序列化与反序列化。
RDB对象数据的读写
对于Redis中数据对象类型的序列化与反序列化,是通过下面这两个函数来实现的:
ssize_t rdbSaveObject(rio *rdb, robj *o, robj *key);
robj *rdbLoadObject(int rdbtype, rio *rdb, robj *key);对象序列化的过程会根据对象的底层编码类型,如果是使用快速列表、哈希表、或跳跃表这类离散型数据结构的话,那么遍历对象中的子数据,将其依次序列化到文件之中;如果是使用压缩链表、整数集合这类的连续内存数据结构,那么直接将这段连续的内存序列化到文件之中。需要注意的是,调用rdbSaveObject函数只会将数据对象序列化到文件中,而不会写入对象的类型,因此需要显式调用rdbSaveObjectType将对象的类型进行序列化。
而数据对象的反序列化,则是通过rdbLoadObject函数进行的,与序列化函数rdbSaveObject对应,调用这个函数前,需要首先反序列化出对象的类型rdbtype,然后rdbLoadObject这个函数会通过rdbtype参数,选择对应的反序列化方式,从文件之中读出数据。
对于存储在数据库之中的数据,是以key-value的形式存储在键空间之中;如果设置了有效期,则会在redisDb.expires中保存一份key-timestamp记录,对于这样一组数据,Redis通过下面这个函数进行序列化:
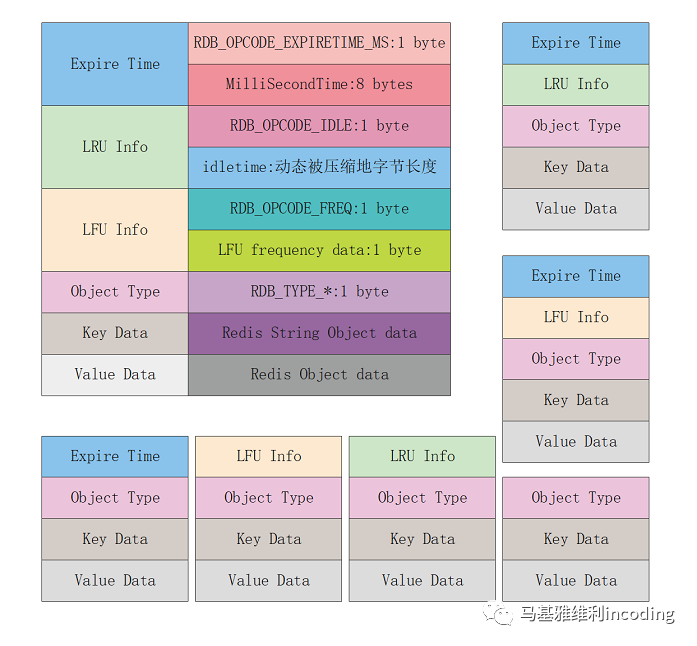
int rdbSaveKeyValuePair(rio *rdb, robj *key, robj *val, long long expiretime);这个函数会按照如下的策略对数据进行序列化:
如果设置了有效期,那么通过
RDB_OPCODE_EXPIRETIME_MS类型,将key的有效期序列化到文件之中;如果服务器开启了LRU或者LFU策略,那么通过
RDB_OPCODE_IDLE或者RDB_OPCODE_FREQ将相关数据序列化到文件之中;调用
rdbSaveObjectType接口,将val的对象类型序列化到文件之中;由于key一定都是字符串对象类型,调用
rdbSaveStringObject接口,将key序列化到文件之中;调用
rdbSaveObject接口,将val序列化到文件之中。
这也就意味着,Redis键空间之中的每一条数据都将以下面的几种存储格式之一序列化到文件之中:















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









