






1. 导语
大家好,我是光城,欢迎大家订阅我的 Chat,本文将会以理论与实践结合的方式,进行 Chat 讲解。
本文 Chat 源码全部存放在本人 GitHub 仓库,地址:
欢迎大家提 issue 与 star!接下来进入本节 Chat 内容。
本节亿级数据从 MySQL 到 HBase 的三种同步方案与实践,将主要围绕下面架构图中的三种方法进行实践与讲解。
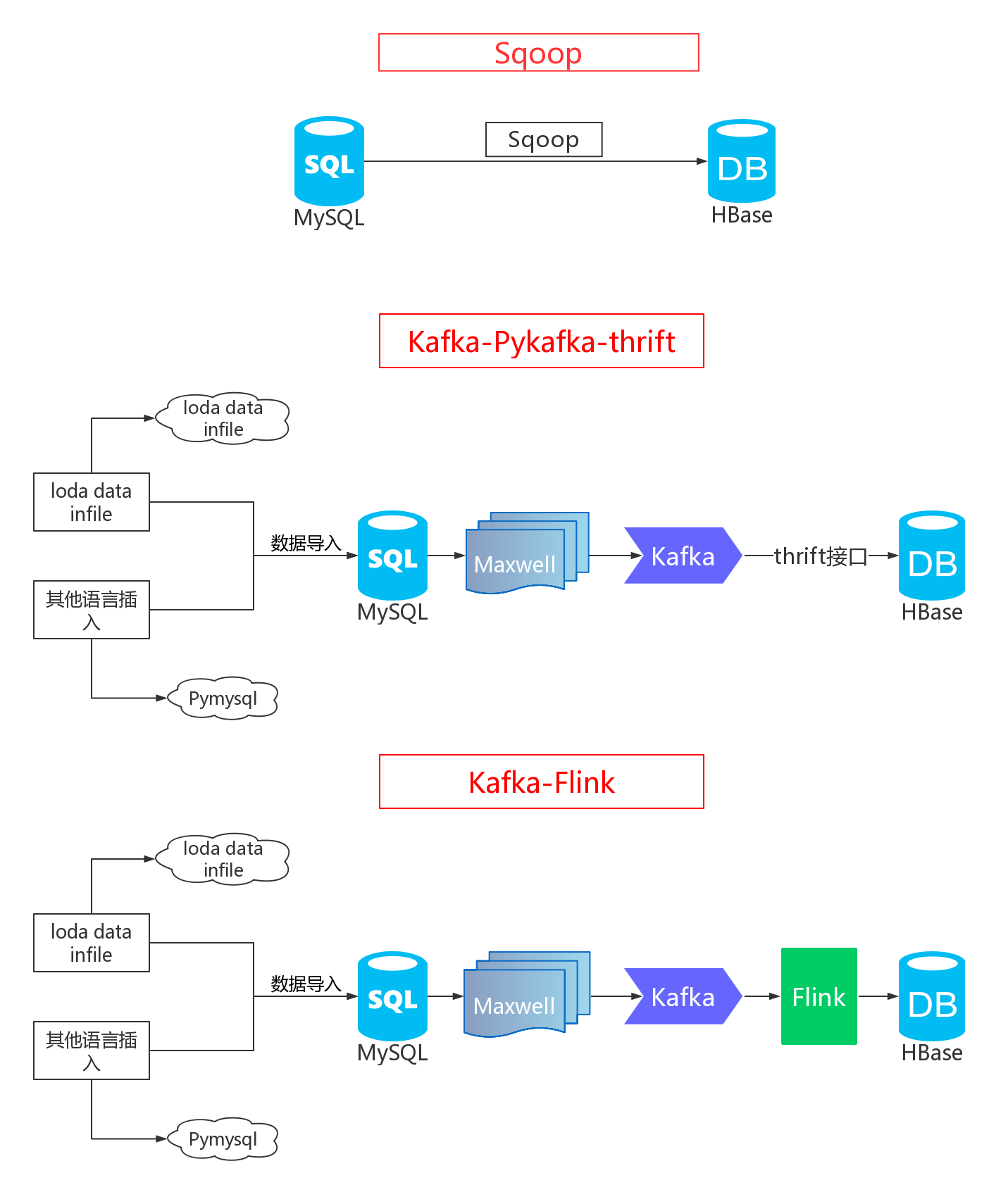
2. 工欲善其事,必先利其器
2.1 环境需知
我的实验环境为:Ubuntu 16.04 + Hadoop 伪分布式(所以重点会介绍伪分布式环境部署),本文实验可以适用于大部分 Linux。
实验的环境有:
MySQL
Hadoop 伪分布式/完全分布式
HBase
Phoenix
ZooKeeper
Kafka
Maxwell
Flink
所以,本文内容先从以上环境部署讲起,再来逐步分析亿级数据从 MySQL 到 HBase 的三种同步方案与实践。
注意:本文不会非常深入地去讲解 HBase、Phoenix、Kafka、Maxwell、Flink 等内容,因为涉及的面非常多,光一个就可以讲很多天了,所以本文将具体的某一块与我们的场景相结合进行阐述,谈谈它们的具体应用与使用,相信大家看完后,对这些会有更加深入的理解!
2.2 伪分布式环境部署
2.2.1.准备工作
Java
Hadoop 环境需要 Java 环境,所以首先得安装 Java,而 Ubuntu 默认 Java 为 OpenJDK,需要先卸载,再安装 Oracle。除此之外,也可以不用卸载 OpenJDK,将 Oracle Java 设为默认的即可。

关于 Java 配置只要输入 java 或者 javac 看到输出,配置成功。
用户
在 Ubuntu 或者类 Unix 系统中,用户可以通过下列命令添加创建用户:
sudo useradd -s /bin/bash -g hadoop -d /home/hadoop -m hadoop
如果提示 Hadoop 不在 sudoers 文件中,执行下列命令:
vi /etc/sudoers
编辑上述文件:
# User privilege specification
root ALL=(ALL:ALL) ALL
hadoop ALL=(ALL:ALL) ALL # 添加此行
再执行上述命令:















 2989
2989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









