







引言
我们使用简单的测试用例来对各种高级编程语言进行比较。我们是从新手程序员的角度来实现测试用例,假设这个新手程序员不熟悉语言中可用的优化技术。我们的目的是突出每一种语言的优缺点,而不是宣称一种语言比其他语言更优越。计时结果以秒为单位,精确到四位数,任何小于 0.0001 的值将被视为 0 秒。
本文提供的测试是在 Intel Xeon Haswell 处理器节点上进行的,每个节点有 28 核(每核 2.6GHz)和 128GB 的可用内存。Python、Java 和 Scala 测试运行在一台 Mac 计算上,该计算机配备了 Intel i7-7700HQ(4 核,每核 2.8GHz),16GB 可用内存,以便与 Xeon 节点进行比较。我们考虑这些语言使用如下版本:
| 语言 | 版本号 | 是否开源 |
|---|---|---|
| Python | 3.7 | 是 |
| Julia | 0.6.2 | 是 |
| Java | 10.0.2 | 是 |
| Scala | 2.13.0 | 是 |
| IDL | 8.5 | 否 |
| R | 3.6.1 | 是 |
| Matlab | R2017b | 否 |
| GNU Compilers | 9.1 | 是 |
| Intel Compilers | 18.0.5.274 | 否 |
GNU 和 Intel 编译器用于 C 和 Fortran。包含这些语言是为了作为基准,这就是为什么它们的测试也带有优化版本(-O3、-Ofast)的原因。
测试用例分为四类:
循环和向量化
字符串操作
数值计算
输入 / 输出
每个测试都足够“简单”,可以用任何一种语言快速编写,旨在解决以下问题:
非连续内存位置的访问
递归函数的使用
循环或向量化的利用
海量文件的打开
任意长度的字符串的操作
矩阵的乘积
迭代求解的使用
等等
源文件包含在以下目录中:
复制代码
C\ Fortran\ IDL\ Java\ Julia\ Matlab\ Python\ R\ Scala\
还有一个目录:
复制代码
Data\
它包含一个 Python 脚本,该脚本在读取大量文件时生成测试用例所需的 NetCDF4 文件。它还有用于“计算文件中唯一单词”测试用例的示例文本文件。
备注:在下面显示的结果中,我们使用了较旧版本的 Julia,因为在 Xeon Haswell 节点上安装最新版本的 Julia(1.1.1) 时我们遇到了困难。此外,Python 实验并不包括 Numba,因为我们有权访问的 Haswell 节点使用的是较旧版本的操作系统,妨碍了 Numba 的正确安装。
循环与向量化
复制多维数组
给定任意 n x n x 3 矩阵 A,我们将执行以下操作:
复制代码
A(i, j, 1) = A(i, j, 2)
A(i, j, 3) = A(i, j, 1)
A(i, j, 2) = A(i, j, 3)
循环和向量化的使用。该测试用例旨在测量语言访问连续内存位置的速度,并查看每种语言如何处理循环和向量化。
表 CPA-1.0:在 Xeon 节点上使用循环复制矩阵元素所用的时间。
| 语言 | 选项 | n=5000 | n=7000 | n=9000 |
|---|---|---|---|---|
| Python | 16.2164 | 31.7867 | 52.5485 | |
| Julia | 0.0722 | 0.1445 | 0.2359 | |
| Java | 0.1810 | 0.3230 | 0.5390 | |
| Scala | 0.2750 | 0.4810 | 0.7320 | |
| IDL | 6.4661 | 11.9068 | 19.4499 | |
| R | 22.9510 | 44.9760 | 74.3480 | |
| Matlab | 0.2849 | 0.5203 | 0.8461 | |
| Fortran | gfortran | 0.1760 | 0.3480 | 0.5720 |
| gfortran -O3 | 0.0680 | 0.1720 | 0.2240 | |
| ifort | 0.0680 | 0.1360 | 0.2240 | |
| ifort -O3 | 0.0680 | 0.1360 | 0.2800 | |
| C | gcc | 0.1700 | 0.3400 | 0.5600 |
| gcc -Ofast | 0.0900 | 0.1800 | 0.3100 | |
| icc | 0.1000 | 0.1800 | 0.3000 | |
| icc -Ofast | 0.1000 | 0.1800 | 0.3000 |
表 CPA-1.1:在 i7 Mac 上使用循环复制矩阵元素所用的时间。
| 语言 | n=5000 | n=7000 | n=9000 |
|---|---|---|---|
| Python | 18.6675 | 36.4046 | 60.2338 |
| Python (Numba) | 0.3398 | 0.3060 | 0.3693 |
| Java | 0.1260 | 0.2420 | 0.4190 |
| Scala | 0.2040 | 0.3450 | 0.5150 |
表 CPA-2.0:在 Xeon 节点上使用向量化复制矩阵元素所用的时间。
| 语言 | 选项 | n=5000 | n=7000 | n=9000 |
|---|---|---|---|---|
| Python | 0.4956 | 0.9739 | 1.6078 | |
| Julia | 0.3173 | 0.5575 | 0.9191 | |
| IDL | 0.3900 | 0.7641 | 1.2643 | |
| R | 3.5290 | 6.9350 | 11.4400 | |
| Matlab | 0.2862 | 0.5591 | 0.9188 | |
| Fortran | gfortran | 0.0960 | 0.2520 | 0.3240 |
| gfortran -O3 | 0.0960 | 0.2440 | 0.3120 | |
| ifort | 0.1400 | 0.2280 | 0.3840 | |
| ifort -O3 | 0.1200 | 0.2360 | 0.4560 |
表 CPA-2.1:在 i7 Mac 上使用向量化复制矩阵元素所用的时间。
| 语言 | n=5000 | n=7000 | n=9000 |
|---|---|---|---|
| Python | 0.5602 | 1.0832 | 1.8077 |
| Python (Numba) | 0.8507 | 1.3650 | 2.0739 |
字符串操作
外观数列
外观数列(Look and Say Sequence)读取一个整数。在后续的每个项中,前一个项中每个整数出现的次数连接到该整数的前面。如,一个项 1223,接下来将会是 112213 ,或“一个 1,两个 2,一个 3”。这里,我们从数字开始:1223334444 ,并确定 n 项(随 n 不同)的外观数列,这个测试用例突出显示了语言如何操作操纵任意长度的字符串。
表 LKS-1.0:在 Xeon 节点上查找 n 项的外观数列所用的时间。
| 语言 | 选项 | n=40 | n=45 | n=48 |
|---|---|---|---|---|
| Python | 2.0890 | 44.4155 | 251.1905 | |
| Java | 0.0694 | 0.0899 | 0.1211 | |
| Scala | 0.0470 | 0.1270 | 0.2170 | |
| IDL | 20.2926 | 304.5049 | 1612.4277 | |
| Matlab | 423.2241 | 6292.7255 | exceeded time limit | |
| Fortran | gfortran | 0.0080 | 0.0120 | 0.0120 |
| gfortran -O3 | 0.0080 | 0.0120 | 0.0120 | |
| ifort | 0.0040 | 0.0160 | 0.0120 | |
| ifort -O3 | 0.0080 | 0.0040 | 0.0080 | |
| C | gcc | 0.0600 | 0.1900 | 0.4300 |
| gcc -Ofast | 0.0400 | 0.1800 | 0.4000 | |
| icc | 0.0600 | 0.1900 | 0.4100 | |
| icc -Ofast | 0.0500 | 0.1900 | 0.4100 |
表 LKS-1.1:在 i7 Mac 上查找 n 项的外观数列所用的时间。
| 语言 | n=40 | n=45 | n=48 |
|---|---|---|---|
| Python | 1.7331 | 22.3870 | 126.0252 |
| Java | 0.0665 | 0.0912 | 0.1543 |
| Scala | 0.0490 | 0.0970 | 0.2040 |
文件中的唯一单词
我们打开一个任意文件,并计算其中唯一单词的数量,假设单词如下:
复制代码
ab Ab aB a&*(-b: 17;A#~!b
数量是相同的(在这样的情况下,大小写、特殊字符和数字将被忽略)。在我们的测试中,使用了四个文件:
复制代码
world192.txt、plrabn12.txt、bible.txt、book1.txt
这些文件取自 Canterbury 语料库。
表 UQW-1.0:在 Xeon 节点上计算文件中的唯一单词所用的时间。
| 语言 | world192.txt(19626 个单词) | plrabn12.txt(9408 个单词) | bible.txt(12605 个单词) | book1.txt(12427 个单词) |
|---|---|---|---|---|
| Python (dictionary method) | 0.5002 | 0.1090 | 0.8869 | 0.1850 |
| Python (set method) | 0.3814 | 0.0873 | 0.7548 | 0.1458 |
| Julia | 0.2190 | 0.0354 | 0.3239 | 0.0615 |
| Java | 0.5624 | 0.2299 | 1.0135 | 0.2901 |
| Scala | 0.4600 | 0.2150 | 0.6930 | 0.2190 |
| R | 104.5820 | 8.6440 | 33.8210 | 17.6720 |
| Matlab | 3.0270 | 0.9657 | 6.0348 | 1.0390 |
表 UQW-1.1:在 i7 Mac 上计算文件中唯一单词所用的时间。
| 语言 | world192.txt(19626 个单词) | plrabn12.txt(9408 个单词) | bible.txt(12605 个单词) | book1.txt(12427 个单词) |
|---|---|---|---|---|
| Python (dictionary method) | 0.3541 | 0.0866 | 0.7346 | 0.1448 |
| Python (set method) | 0.3685 | 0.0820 | 0.7197 | 0.1417 |
| Java | 0.5129 | 0.2530 | 0.9183 | 0.3220 |
| Scala | 0.5810 | 0.1540 | 0.6650 | 0.2330 |
数值计算
斐波那契数列
斐波那契数列是一个数字序列,其中每个连续的数字是它前面两个数字的和:
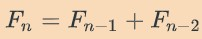
它的第一项是:
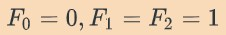
斐波那契数列在经济学、计算机科学、生物学、组合学等领域都有广泛的应用。我们在计算第 n 个斐波那契数列时测量所用的时间。迭代计算和递归计算都需要计算时间。
表 FBC-1.0:在 Xeon 节点上迭代查找斐波那契数列所用的时间。
| 语言 | 选项 | n=25 | n=35 | n=45 |
|---|---|---|---|---|
| Python | 0 | 0 | 0 | |
| Julia | 0 | 0 | 0 | |
| Java | 0 | 0 | 0 | |
| Scala | 0 | 0 | 0 | |
| IDL | 0 | 0 | 0 | |
| R | 0.0330 | 0.0320 | 0.0320 | |
| Matlab | 0.0026 | 0.0034 | 0.0038 | |
| Fortran | gfortran | 0 | 0 | 0 |
| gfortran -O3 | 0 | 0 | 0 | |
| ifort | 0 | 0 | 0 | |
| ifort -O3 | 0 | 0 | 0 | |
| C | gcc | 0 | 0 | 0 |
| gcc -Ofast | 0 | 0 | 0 | |
| icc | 0 | 0 | 0 | |
| icc -Ofast | 0 | 0 | 0 |
表 FBC-1.1:在 i7 Mac 上迭代查找斐波那契数列所用的时间。
| 语言 | n=25 | n=35 | n=45 |
|---|---|---|---|
| Python | 0 | 0 | 0 |
| Python (Numba) | 0.1100 | 0.1095 | 0.1099 |
| Java | 0 | 0 | 0 |
| Scala | 0 | 0 | 0 |
表 FBC-2.0:在 Xeon 节点上递归查找斐波那契数列所用的时间。
| 语言 | 选项 | n=25 | n=35 | n=45 |
|---|---|---|---|---|
| Python | 0.0593 | 7.0291 | 847.9716 | |
| Julia | 0.0003 | 0.0308 | 3.787 | |
| Java | 0.0011 | 0.0410 | 4.8192 | |
| Scala | 0.0010 | 0.0560 | 5.1400 | |
| IDL | 0.0238 | 2.5692 | 304.2198 | |
| R | 0.0090 | 0.0100 | 0.0100 | |
| Matlab | 0.0142 | 1.2631 | 149.9634 | |
| Fortran | gfortran | 0 | 0.0840 | 10.4327 |
| gfortran -O3 | 0 | 0 | 0 | |
| ifort | 0 | 0 | 0 | |
| ifort -O3 | 0 | 0 | 0 | |
| C | gcc | 0 | 0.0400 | 5.0600 |
| gcc -Ofast | 0 | 0.0200 | 2.2000 | |
| icc | 0 | 0.0300 | 3.1400 | |
| icc -Ofast | 0 | 0.0200 | 3.2800 |
表 FBC-2.1:在 i7 Mac 上递归查找斐波那契数列所用的时间。
| 语言 | n=25 | n=35 | n=45 |
|---|---|---|---|
| Python | 0.0519 | 6.4022 | 800.0381 |
| Python (Numba) | 0.4172 | 43.7604 | 5951.6544 |
| Java | 0.0030 | 0.0442 | 5.0130 |
| Scala | 0.0010 | 0.0470 | 5.7720 |
矩阵乘法
将两个随机生成的 n x n 矩阵 A 和 B 相乘。测量执行乘法的时间。这个问题说明了利用每种语言中可用的内置库的重要性。
表 MXM-1.0:在 Xeon 节点上进行矩阵相乘所用的时间。
| 语言 | 选项 | n=1500 | n=1750 | n=2000 |
|---|---|---|---|---|
| Python | intrinsic | 0.1560 | 0.2430 | 0.3457 |
| Julia | intrinsic | 0.1497 | 0.2398 | 0.3507 |
| Java | loop | 13.8610 | 17.8600 | 32.3370 |
| Scala | loop | 9.8380 | 19.1450 | 32.1310 |
| R | intrinsic | 0.1600 | 0.2460 | 0.3620 |
| Matlab | intrinsic | 1.3672 | 1.3951 | 0.4917 |
| IDL | intrinsic | 0.1894 | 0.2309 | 0.3258 |
| Fortran | gfortran (loop) | 17.4371 | 31.4660 | 62.1079 |
| gfortran -O3 (loop) | 3.3282 | 5.3003 | 12.1648 | |
| gfortran (matmul) | 0.3840 | 0.6160 | 0.9241 | |
| gfortran -O3 (matmul) | 0.3880 | 0.6160 | 0.9161 | |
| ifort (loop) | 1.1401 | 1.8161 | 2.9282 | |
| ifort -O3 (loop) | 1.1481 | 1.8081 | 2.9802 | |
| ifort (matmul) | 1.1441 | 1.8121 | 2.9242 | |
| ifort -O3 (matmul) | 0.5160 | 0.8281 | 1.2441 | |
| ifort (DGEMM) | 0.2160 | 0.2360 | 0.3320 | |
| C | gcc (loop) | 13.2000 | 20.9800 | 31.4400 |
| gcc -Ofast (loop) | 1.4500 | 2.3600 | 4.0400 | |
| icc (loop) | 1.2300 | 2.1500 | 4.0500 | |
| icc -Ofast (loop) | 1.1500 | 1.7500 | 2.5900 |
表 MXM-1.1:在 i7 Mac 上进行矩阵相乘所用的时间。
| 语言 | 选项 | n=1500 | n=1750 | n=2000 |
|---|---|---|---|---|
| Python | intrinsic | 0.0906 | 0.1104 | 0.1611 |
| Numba (loop) | 9.2595 | 20.2012 | 35.3174 | |
| Java | loop | 32.5080 | 47.7680 | 82.2810 |
| Scala | loop | 23.0540 | 38.9110 | 60.3180 |
置信传播算法
置信传播是一种用于推理的算法,通常用于人工智能、语音识别、计算机视觉、图像处理、医学诊断、奇偶校验码等领域。我们用 5000x5000 元素矩阵来测量算法进行 n 次迭代所用的时间。在 Justin Domke 的博客( Domke 2012 )中展示了 MATLAB、C 和 Julia 的代码,该博客指出,这个算法是“矩阵乘法的重复序列,然后进行归一化”。
表 BFP-1.0:在 Xeon 节点上执行置信传播算法所用的时间。
| 语言 | 选项 | n=250 | n=500 | n=1000 |
|---|---|---|---|---|
| Python | 3.7076 | 7.0824 | 13.8950 | |
| Julia | 4.0280 | 7.8220 | 15.1210 | |
| Java | 63.9240 | 123.3840 | 246.5820 | |
| Scala | 53.5170 | 106.4950 | 212.3550 | |
| IDL | 16.9609 | 33.2086 | 65.7071 | |
| R | 23.4150 | 45.4160 | 89.7680 | |
| Matlab | 1.9760 | 3.8087 | 7.4036 | |
| Fortran | gfortran | 21.0013 | 41.0106 | 87.6815 |
| gfortran -O3 | 4.4923 | 8.2565 | 17.5731 | |
| ifort | 4.7363 | 9.1086 | 17.8651 | |
| ifort -O3 | 4.7363 | 9.1086 | 21.1973 | |
| C | gcc | 2.6400 | 5.2900 | 10.5800 |
| gcc -Ofast | 2.4200 | 4.8500 | 9.7100 | |
| icc | 2.1600 | 4.3200 | 8.6500 | |
| icc -Ofast | 2.1800 | 4.3400 | 8.7100 |
表 BFP-1.1:在 i7 Mac 上执行置信传播算法所用的时间。
| 语言 | n=250 | n=500 | n=1000 |
|---|---|---|---|
| Python | 2.4121 | 4.5422 | 8.7730 |
| Java | 55.3400 | 107.7890 | 214.7900 |
| Scala | 47.9560 | 95.3040 | 189.8340 |
梅特罗波利斯 - 黑斯廷斯(Metropolis-Hastings)算法
梅特罗波利斯 - 黑斯廷斯算法是一种用于从概率分布中提取随机样本的算法。该实现使用二维分布(Domke 2012 ),并测量迭代 n 次所用的时间。
表 MTH-1.0:在 Xeon 节点上执行梅特罗波利斯 - 黑斯廷斯算法所用的时间。
| 语言 | 选项 | n=5000 | n=10000 | n=15000 |
|---|---|---|---|---|
| Python | 0.0404 | 0.0805 | 0.1195 | |
| Julia | 0.0002 | 0.0004 | 0.0006 | |
| Java | 0.0040 | 0.0050 | 0.0060 | |
| Scala | 0.0080 | 0.0090 | 0.0100 | |
| IDL | 0.0134 | 0.0105 | 0.0157 | |
| R | 0.0760 | 0.1500 | 0.2230 | |
| Matlab | 0.0183 | 0.0211 | 0.0263 | |
| Fortran | gfortran | 0 | 0 | 0 |
| gfortran -O3 | 0 | 0 | 0 | |
| ifort | 0.0040 | 0 | 0 | |
| ifort -O3 | 0.0040 | 0.0040 | 0 | |
| C | gcc | 0 | 0 | 0 |
| gcc -Ofast | 0 | 0 | 0 | |
| icc | 0 | 0 | 0 | |
| icc -Ofast | 0 | 0 | 0 |
表 MTH-1.1:在 i7 Mac 上执行梅特罗波利斯 - 黑斯廷斯算法所用的时间。
| 语言 | n=5000 | n=10000 | n=15000 |
|---|---|---|---|
| Python | 0.0346 | 0.0638 | 0.0989 |
| Java | 0.0060 | 0.0040 | 0.0060 |
| Scala | 0.0090 | 0.0100 | 0.0130 |
快速傅里叶变换
我们创建一个 n x n 矩阵 M ,其中包含随机复值。我们计算了 M 的快速傅里叶变换和结果的绝对值。快速傅里叶变换算法广泛用于各种科学和工程领域的信号处理和图像处理。
表 FFT-1.0:在 Xeon 节点上计算快速傅里叶变换所用的时间。
| 语言 | 选项 | n=10000 | n=15000 | n=20000 |
|---|---|---|---|---|
| Python | intrinsic | 8.0797 | 19.6357 | 34.7400 |
| Julia | intrinsic | 3.979 | 11.490 | 20.751 |
| IDL | intrinsic | 16.6699 | 38.9857 | 70.8142 |
| R | intrinsic | 58.2550 | 150.1260 | 261.5460 |
| Matlab | intrinsic | 2.6243 | 6.0010 | 10.66232 |
表 FFT-1.1:在 i7 Mac 上计算快速傅里叶变换所用的时间。
| 语言 | 选项 | n=10000 | n=15000 | n=20000 |
|---|---|---|---|---|
| Python | intrinsic | 7.9538 | 21.5355 | 55.9375 |
迭代求解器
我们使用雅克比法迭代求解器(Jacobi iterative solver)数值逼近二维拉布拉斯方程(Laplace equation)的解,该解用四阶紧致格式离散(Gupta,1984)。随着网络点数量的变化,我们记录所用的时间。
表 ITS-1.0:在 Xeon 节点上迭代计算近似解所用的时间。
| 语言 | 选项 | n=100 | n=150 | n=200 |
|---|---|---|---|---|
| Python | 158.2056 | 786.3425 | 2437.8560 | |
| Julia | 1.0308 | 5.1870 | 16.1651 | |
| Java | 0.4130 | 1.8950 | 5.2220 | |
| Scala | 0.540 | 2.1030 | 5.7380 | |
| IDL | 73.2353 | 364.1329 | 1127.1094 | |
| R | 157.1490 | 774.7080 | 2414.1030 | |
| Matlab | 2.8163 | 5.0543 | 8.6276 | |
| Fortran | gfortran | 0.8240 | 3.7320 | 10.7290 |
| gfortran -O3 | 0.6680 | 3.0720 | 8.8930 | |
| ifort | 0.5400 | 2.4720 | 7.1560 | |
| ifort -O3 | 0.5400 | 2.4680 | 7.1560 | |
| C | gcc | 0.5000 | 2.4200 | 7.7200 |
| gcc -Ofast | 0.2200 | 1.0500 | 3.1900 | |
| icc | 0.4600 | 2.2300 | 6.7800 | |
| icc -Ofast | 0.3300 | 1.6000 | 4.8700 |
表 ITS-1.2:在 i7 Mac 上迭代计算近似解所用的时间。
| 语言 | n=100 | n=150 | n=200 |
|---|---|---|---|
| Python | 174.7663 | 865.1203 | 2666.3496 |
| Python (Numba) | 1.3226 | 5.0324 | 15.1793 |
| Java | 0.4600 | 1.7690 | 4.7530 |
| Scala | 0.5970 | 2.0950 | 5.2830 |
表 ITS-2.0:在 Xeon 节点上使用向量化计算近似解所用的时间。
| 语言 | 选项 | n=100 | n=150 | n=200 |
|---|---|---|---|---|
| Python | 2.6272 | 14.6505 | 40.2124 | |
| Julia | 2.4583 | 13.1918 | 41.0302 | |
| IDL | 1.71192 | 8.6841 | 28.0683 | |
| R | 25.2150 | 121.9870 | 340.4990 | |
| Matlab | 3.3291 | 7.6486 | 15.9766 | |
| Fortran | gfortran | 0.8680 | 4.2040 | 11.5410 |
| gfortran -O3 | 0.3600 | 1.8040 | 5.0880 | |
| ifort | 0.2800 | 1.5360 | 4.4560 | |
| ifort -O3 | 0.2800 | 1.5600 | 4.4160 |
表 ITS-2.1:在 i7 Mac 上使用向量化计算近似解所用的时间。
| 语言 | n=100 | n=150 | n=200 |
|---|---|---|---|
| Python | 1.7051 | 7.4572 | 22.0945 |
| Python (Numba) | 2.4451 | 8.5094 | 21.7833 |
矩阵的平方根
给定 n x n 矩阵 A,我们寻找这样的矩阵 B,使得:
B * B = A
B 就是平方根。在我们的计算中,我们考虑对角线上为 6,别处为 1 的矩阵 A。
表 SQM-1.0:在 Xeon 节点上计算矩阵的平方根所用的时间。
| 语言 | n=1000 | n=2000 | n=4000 |
|---|---|---|---|
| Python | 1.0101 | 5.2376 | 44.4574 |
| Julia | 0.4207 | 2.5080 | 19.0140 |
| R | 0.5650 | 3.0660 | 19.2660 |
| Matlab | 0.3571 | 1.6552 | 2.6250 |
表 SQM-1.1:在 i7 Mac 上计算矩阵的平方根所用的时间。
| 语言 | n=1000 | n=2000 | n=4000 |
|---|---|---|---|
| Python | 0.5653 | 3.3963 | 25.9180 |
高斯求积
高斯求积(Gauss-Legendre Quadrature)是逼近定积分的一种数值方法。它使用被积函数的 n 个值的加权和。如果被积函数是 0 到 2 n - 1 次多项式,则结果是精确的。这里我们考虑区间 [-3, 3] 上的指数函数,并记录当 n 变化时执行积分所用的时间。
表 GLQ-1.0:在 Xeon 节点上计算积分近似值所用的时间。
| 语言 | 选项 | n=50 | n=75 | n=100 |
|---|---|---|---|---|
| Python | 0.0079 | 0.0095 | 0.0098 | |
| Julia | 0.0002 | 0.0004 | 0.0007 | |
| IDL | 0.0043 | 0.0009 | 0.0014 | |
| R | 0.0260 | 0.0240 | 0.0250 | |
| Matlab | 0.7476 | 0.0731 | 0.4982 | |
| Fortran | gfortran | 0 | 0.0040 | 0.0080 |
| gfortran -O3 | 0 | 0.0120 | 0.0120 | |
| ifort | 0.0080 | 0.0080 | 0.0080 | |
| ifort -O3 | 0.0080 | 0.0040 | 0.0080 |
表 GLQ-1.1:在 i7 Mac 上计算积分近似值所用的时间。
| 语言 | n=50 | n=75 | n=100 |
|---|---|---|---|
| Python | 0.0140 | 0.0035 | 0.0077 |
三角函数
我们在 n 元素值列表上迭代计算三角函数,然后在同一列表上计算反三角函数。当 n 发生变化时,测量完整全部操作所用的时间。
表 TRG-1.0:在 Xeon 节点上计算三角函数所用的时间。
| 语言 | 选项 | n=80000 | n=90000 | n=100000 |
|---|---|---|---|---|
| Python | 14.6891 | 16.5084 | 23.6273 | |
| Julia | 55.3920 | 62.9490 | 69.2560 | |
| IDL | 37.4413 | 41.9695 | 35.2387 | |
| R | 91.5250 | 102.8720 | 113.8600 | |
| Matlab | 5.2794 | 5.8649 | 6.3699 | |
| Scala | 357.3730 | 401.8960 | 446.7080 | |
| Java | 689.6560 | 774.9110 | 865.057 | |
| Fortran | gfortran | 53.4833 | 60.0317 | 66.6921 |
| gfortran -O3 | 49.9271 | 56.0235 | 62.1678 | |
| ifort | 18.6411 | 20.9573 | 23.2654 | |
| ifort -O3 | 18.6451 | 20.9573 | 23.2694 | |
| C | gcc | 107.4400 | 120.7300 | 134.0900 |
| gcc -Ofast | 93.0400 | 104.5700 | 116.0600 | |
| icc | 76.2600 | 85.7900 | 95.3100 | |
| icc -Ofast | 48.8400 | 54.9600 | 61.0600 |
表 TRG-1.1:在 i7 Mac 上计算三角函数所用的时间。
| 语言 | n=80000 | n=90000 | n=100000 |
|---|---|---|---|
| Python | 3.5399 | 6.1984 | 6.9207 |
Munchausen 数
Munchausen 数 是一个自然数,等于其自身幂次的位数之和。在以 10 为基数的情况下,有 4 个这样的数字:0、1、3435 和 438579088。我们来确定找到这些数字需要多久。
表 MCH-1.0:在 Xeon 节点上查找 Munchausen 数所用的时间。
| 语言 | 选项 | 所用时间 |
|---|---|---|
| Python | 1130.6220 | |
| Julia | 102.7760 | |
| Java | 4.9008 | |
| Scala | 72.9170 | |
| R | exceeded time limit | |
| IDL | exceeded time limit | |
| Matlab | 373.9109 | |
| Fortran | gfortran | 39.7545 |
| gfortran -O3 | 21.3933 | |
| ifort | 29.6458 | |
| ifort -O3 | 29.52184 | |
| C | gcc | 157.3500 |
| gcc -Ofast | 126.7900 | |
| icc | 228.2300 | |
| icc -Ofast | 228.1900 |
表 MCH-1.1:在 i7 Mac 上查找 Munchausen 数所用的时间。
| 语言 | 所用时间 |
|---|---|
| Python | 1013.5649 |
| Java | 4.7434 |
| Scala | 64.1800 |
输入 / 输出
读取大量文件
我们有一套涵盖 20 年的每日 NetCDF 文件(7305)。给定年份的文件位于一个标记为 YYYY 的子目录中(例如,Y1990、Y1991、Y1992 等)。我们希望编写一个脚本,打开每个文件,读取一个三维变量(经度 / 维度 / 级别)并对其进行操作。脚本的伪代码如下:
复制代码
Loop over the years
Obtain the list of NetCDF files
Loop over the files
Read the variable (longitude/latitude/level)
Compute the zonal mean average (new array of latitude/level)
Extract the column array at latitude 86 degree South
Append the column array to a "master" array (or matrix)
目标是能够生成三维数组(年份 / 级别 / 值)并执行等高线图。这是我们支持的典型用户面临的问题类型:需要对数千个文件进行操作以提取所需信息的集合。拥有能够从文件中快速读取数据(如 NetCDF、HDF4、HDF5、grib 等格式)的工具对我们的工作至关重要。
表 RCF-1.0:在 Xeon 节点上处理 NetCDF 文件所用的时间。
| 语言 | 所用时间 |
|---|---|
| Python | 660.8084 |
| Julia | 787.4500 |
| IDL | 711.2615 |
| R | 1220.222 |
| Matlab | 848.5086 |
表 RCF-1.1:在 i7 Mac 上处理 NetCDF 文件所用的时间。
| 语言 | 所用时间 |
|---|---|
| Python | 89.1922 |
表 RCF-2.0:在 Xeon 节点上利用多核处理器使用 Python 处理 NetCDF 文件所用的时间。
| 核 | 所用时间 |
|---|---|
| 1 | 570.9791 |
| 2 | 317.6108 |
| 4 | 225.4647 |
| 8 | 147.4527 |
| 16 | 84.0102 |
| 24 | 59.7646 |
| 28 | 51.2191 |
表 RCF-2.1:在 i7 Mac 上利用多核处理器使用 Python 处理 NetCDF 文件所用的时间。
| 核 | 所用时间 |
|---|---|
| 1 | 84.1032 |
| 2 | 63.5322 |
| 4 | 56.6156 |
图表总结
在下面的图中,我们通过使用 GCC 获得的计时数字(仅在最后一列,即最大问题的大小)作为参考,总结上述计时结果。
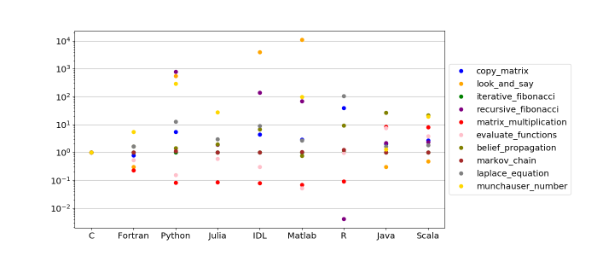
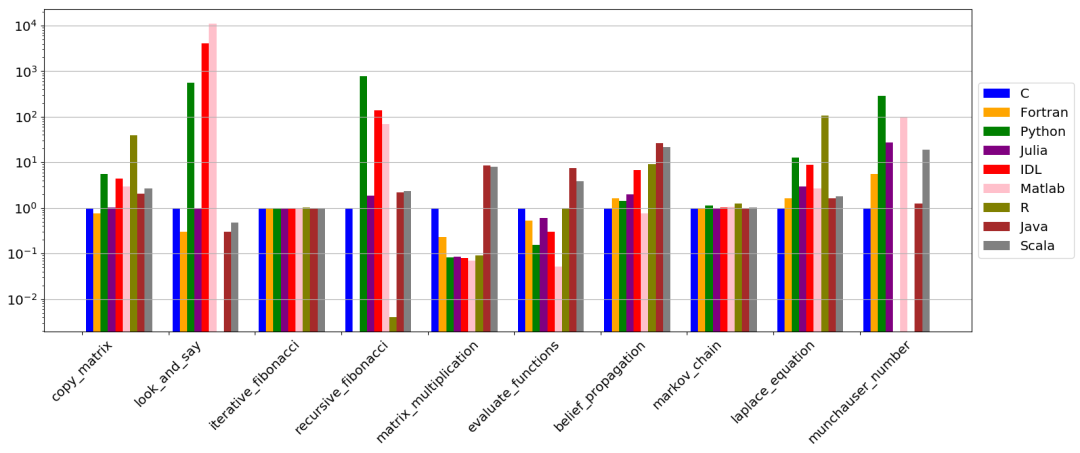
研究结果
概述:
没有任何一种语言在所有测试中都优于其他语言。
通过仅在必要时创建变量以及“清空”不再使用的变量来减少内存占用非常重要。
对于相同的任务,使用内置函数会比内联代码带来更高的性能。
Julia 和 R 提供了简单的基准测试工具。我们编写了一个简单的 Python 工具,允许我们随心所欲地多次运行 Python 测试用例。
循环和向量化:
与使用循环相比,Python(和 NumPy)、IDL 和 R 在向量化时运行速度更快。
在使用 Numba 时,只要使用 NumPy 数组,Python 就可以更快地处理循环。
对于 Julia,循环比向量化代码运行得更快。
在不涉及计算的情况下,使用循环与向量化相比,MATLAB 在性能上似乎没有显著变化。当进行计算时,向量化 MATLAB 代码要比迭代代码更快。
字符串操作:
与其他语言相比,Java 和 Scala 在操作大型字符串时,似乎具有显著的性能。
数值计算:
与其他语言相比,R 在使用递归时似乎具有显著的性能。
语言在数值计算中相对于其他语言的性能表现取决于具体的任务。
MATLAB 的内置快速傅里叶变换函数似乎运行速度最快。
输入 / 输出:
虽然有些语言运行测试的速度比其他语言快,但在本地 Mac 上而不是处理器节点上运行测试的话,可以获得最大的性能提升。因为处理器节点使用机械硬盘,而 Mac 用的是固态硬盘。这表明硬件对 I/O 性能的影响比所使用的语言更大。
参考资料
Julia, Matlab and C ,Justin Domke 著,2012 年 9 月 17 日
四阶泊松求解器,《计算物理学杂志》,55(1):166-172,Murli M. Gupta 著,1984 年
原文链接:
Basic Comparison of Python, Julia, Matlab, IDL and Java (2019 Edition)



















 475
475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









