






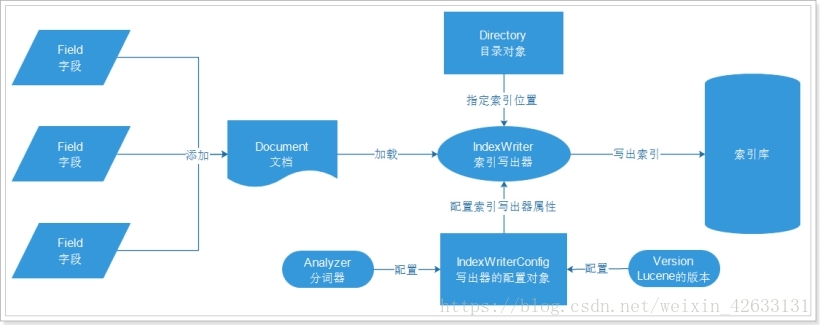
一:建立索引和读取索引的过程如下图:
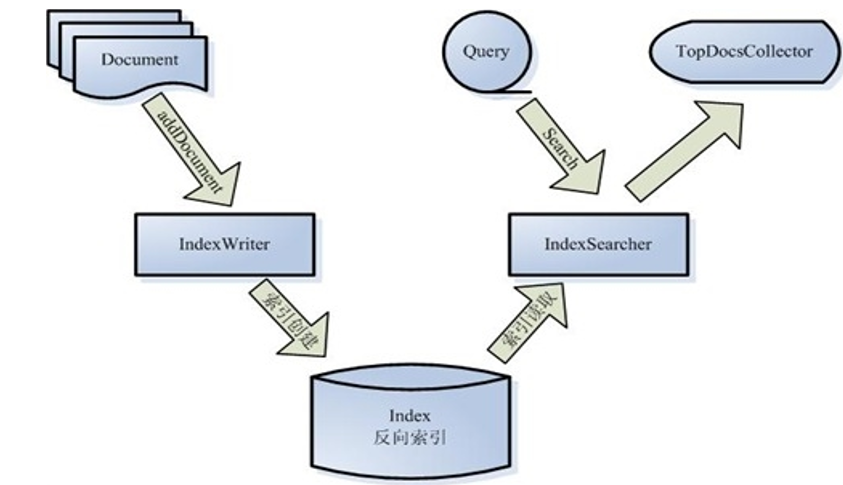
二:索引在索引库中的存放形式如下图:
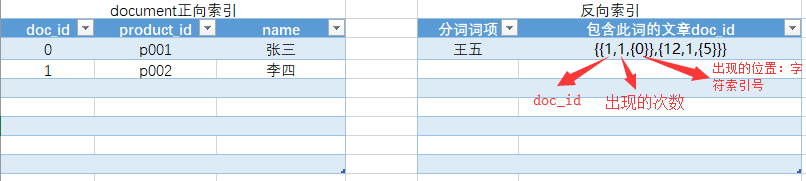
这是内容库 这是目录库
IndexWriter按加入的顺序为Document指定一个递增的id(从0开始),称为文档id。反向索引中存储的是这个id,文档存储中正向索引也是这个id。 业务数据的主键id只是文档的一个字段。
为从原数据中拿完整数据去展示,一个Document应该包含一个或多个存储字段来唯一标识一条原数据。
三:创建索引以及存储文档的域时的规则如下:
创建好Document后,需要给Document添加Field,不同的Field有不同索引、分词和存储规则。
1:什么样的域需要被存储?
查询时,需要从Document中获取的内容对应的域都应该被存储。
2:什么样的域需要被索引?
要被搜索的域需要被索引。
3:什么样的域需要被分词?
在被搜索时,可能只会输入内容的一部分来查询的域需要被分词,例如:商品名称,商品介绍,文章内容等;相反,在查询时必须输入内容的全部来查询的域不能分词,例如:订单号,电话号码等。
四:使用lucene提高数据库中数据的查询实时度的示意图
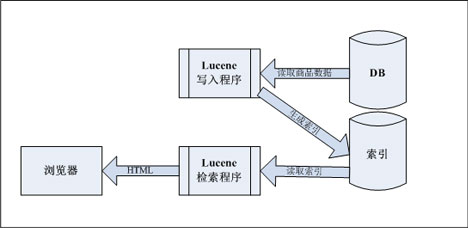
需要注意DB中的哪些数据需要用来创建索引、哪些数据需要存到索引库中的Document中,最终使用Document中能唯一标识DB中一条记录的字段来查询DB,获取记录的详情。
好文章参考链接:
疑问:
1:有关索引的选项中,还有更详细的设置:词频,位置,偏移量等,短语查询、临近查询,高亮显示等功能,和位置、偏移量的关系是什么?
2:IndexableFieldType 中的 docValuesType方法 就是让你来为需要排序、分组、聚合的字段指定如何为该字段创建文档->字段值的正向索引的。那么排序、分组、聚合、分类查询(面查询)的字段到底怎么使用??
3:默认情况下,查询结果的排序是按得分的大小从大到小排序的吗?得分到底是怎么计算的?
4:如果加上排序字段后,得分的排序是不是就不用了,直接用排序字段的排序?
5:lucene的分词器详解?















 427
427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









