








最早接触多模态是一个抖音推荐项目,有一些视频,标题,用户点赞收藏等信息,给用户推荐作品,我当时在这个项目里负责用NLP部分上分,虽然最后用xDeepFM 整个团队效果还可以,但是从a/b test 看文本部分在其中起到的作用为0... ( )
现在看来还是xDeepFM 这种方式太粗暴了(对于复杂信息的融合),本文写写多模态扫盲基础和最近大家精巧的一些图像文本融合的模型设计,主要是在VQA(视觉问答)领域,也有一个多模态QA,因为在推荐领域,你也看到了,即使NLP的贡献为零,用户特征足够,效果也能做到很好了。
一. 概念扫盲
多模态(MultiModal )
- 多种不同的信息源(不同的信息形式)中获取信息表达
五个挑战
- 表示(Multimodal Representation)的意思,比如shift旋转尺寸不变形,图像中研究出的一种表示
- 表示的冗余问题
- 不同的信号,有的象征性信号,有波信号,什么样的表示方式方便多模态模型提取信息
表示的方法
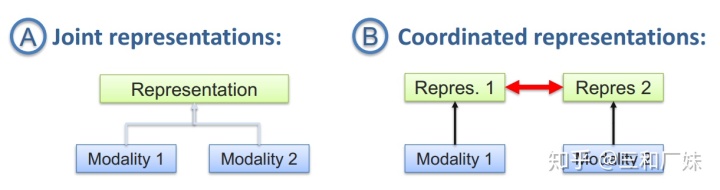
- 联合表示将多个模态的信息一起映射到一个统一的多模态向量空间
- 协同表示负责将多模态中的每个模态分别映射到各自的表示空间,但映射后的向量之间满足一定的相关性约束。
2. 翻译/转化/映射
- 信号的映射,比如给一个图像,将图像翻译成文字,文字翻译成图像,信息转化成统一形式后来应用
- 方式,这里就跟专门研究翻译的领域是重叠,基于实例的翻译,涉及到检索,字典(规则)等,基于生成方法如生成翻译的内容
3. 对齐
- 多模态对齐定义为从两个或多个模态中查找实例子组件之间的关系和对应ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









