






 这篇博客详细介绍了Python字符串的基础知识,包括字符串的定义、驻留区概念、下标和切片操作。此外,还讲解了字符串的常用方法,如len、find、index、replace、split等,并强调了字符串在Python中的不可变特性。
这篇博客详细介绍了Python字符串的基础知识,包括字符串的定义、驻留区概念、下标和切片操作。此外,还讲解了字符串的常用方法,如len、find、index、replace、split等,并强调了字符串在Python中的不可变特性。

一、字符串介绍:
- 双引号或者单引号中的数据,就是字符串
- 如果使用一对引号来定义字符串,当出现符号冲突时可以使用转义字符
- 使用三个单引号、双引号定义的字符串可以包裹任意文本
a = "I'm Tom" # 一对双引号
b = 'Tom said:"I am Tom"' # 一对单引号
c = 'Tom said:"I'm Tom"' # 转义字符
d = '''Tom said:"I'm Tom"''' # 三个单引号
e = """Tom said:"I'm Tom" """ # 三个双引号字符串输入
之前在学习input的时候,通过它能够完成从键盘获取数据,然后保存到指定的变量中;
注意:input获取的数据,都以字符串的方式进行保存,即使输入的是数字,那么也是以字符串方式保存
def input(*args, **kwargs): # real signature unknown
"""
Read a string from standard input. The trailing newline is stripped.
The prompt string, if given, is printed to standard output without a
trailing newline before reading input.
If the user hits EOF (*nix: Ctrl-D, Windows: Ctrl-Z+Return), raise EOFError.
On *nix systems, readline is used if available.
"""
passdemo:
userName = input('请输入用户名:')
print("用户名为:%s" % userName)
password = input('请输入密码:')
print("密码为:%s" % password)结果:
请输入用户名:admin
用户名为: admin
请输入密码:123456
密码为: 123456字符串输出:
主要是通过print(),print的源码如下:
def print(self, *args, sep=' ', end='n', file=None): # known special case of print
"""
print(value, ..., sep=' ', end='n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
"""
passdemo:
name = 'running'
job = '讲师'
address = '北京市'
print('--------------------------------------------------')
print("姓名:%s" % name)
print("职位:%s" % job)
print("公司地址:%s" % address)
print('--------------------------------------------------')结果:
--------------------------------------------------
姓名: running
职位: 讲师
公司地址: 北京市
--------------------------------------------------二、字符串驻留区和下标,切片
字符串驻留区:字符串驻留是一种仅保存一份相同且不可变字符串的方法。
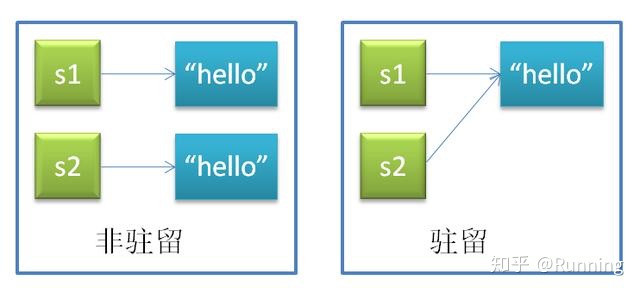
基本原理:
系统维护interned字典,记录已被驻留的字符串对象。
当字符串对象a需要驻留时,先在interned检测是否存在,若存在则指向存在的字符串对象,a的引用计数减1;
若不存在,则记录a到interned中。
为什么要字符串驻留?显而易见,节省大量内存在字符串比较时,非驻留比较效率o(n),驻留时比较效率o(1)。
s1 = 'hello'
s2 = "hello"
s3 = s
print(s1,s2,s3)
print(id(s1),id(s2),id(s3))
s1 = 'hello1'
print(s1,s2,s3)
print(id(s1),id(s2),id(s3))
s2 ='abc'
s3 ='''hello'''
print(s1,s3)
print(id(s1),id(s3))结果展示:

下标/索引
所谓“下标”又叫“索引”,就是编号,就好比超市中的存储柜的编号,通过这个编号就能找到相应的存储空间
- 生活中的 "下标"
超市储物柜

字符串中"下标"的使用
如果有字符串:name = 'abcdef',在内存中的实际存储如下:
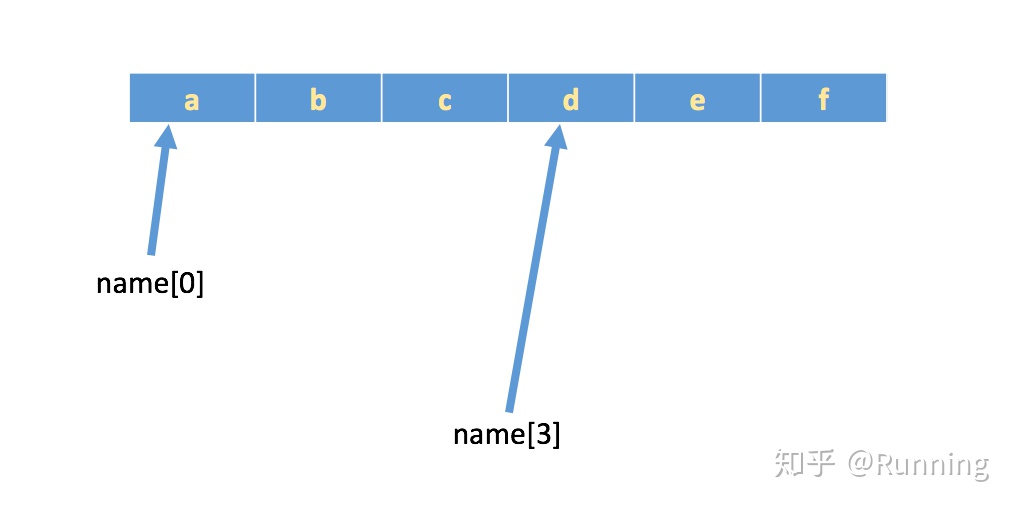
如果想取出部分字符,那么可以通过下标的方法,(注意在计算机中,下标从 0 开始)
name = 'abcdef'
print(name[0])
print(name[1])
print(name[2])运行结果:
a
b
c切片:
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
切片的语法:[起始:结束:步长],也可以简化使用 [起始:结束]
注意:选取的区间从"起始"位开始,到"结束"位的前一位结束(不包含结束位本身),步长表示选取间隔。
# 索引是通过下标取某一个元素
# 切片是通过下标去某一段元素
s = 'Hello World!'
print(s)
print(s[4]) # o 字符串里的第4个元素
print(s[3:7]) # lo W 包含下标 3,不含下标 7
print(s[:]) # Hello World! 取出所有元素(没有起始位和结束位之分),默认步长为1
print(s[1:]) # ello World! 从下标为1开始,取出 后面所有的元素(没有结束位)
print(s[:4]) # Hell 从起始位置开始,取到 下标为4的前一个元素(不包括结束位本身)
print(s[:-1]) # Hello World 从起始位置开始,取到 倒数第一个元素(不包括结束位本身)
print(s[-4:-1]) # rld 从倒数第4个元素开始,取到 倒数第1个元素(不包括结束位本身)
print(s[1:5:2]) # el 从下标为1开始,取到下标为5的前一个元素,步长为2(不包括结束位本身)
print(s[7:2:-1]) # ow ol 从下标为7的元素开始(包含下标为7的元素),倒着取到下标为2的元素(不包括下标为2的元素)
# python 字符串快速逆置
print(s[::-1]) # !dlroW olleH 从后向前,按步长为1进行取值三、字符串常见操作
字符串的常见操作包括:
- 获取长度:len
- 查找内容:find,index,rfind,rindex
- 判断:startswith,endswith,isalpha,isdigit,isalnum,isspace
- 计算出现次数:count
- 替换内容:replace
- 切割字符串:split,rsplit,splitlines,partition,rpartition
- 修改大小写:capitalize,title,upper,lower
- 空格处理:ljust,rjust,center,lstrip,rstrip,strip
- 字符串拼接:join
注意:在Python中,字符串是不可变的!所有的字符串相关方法,都不会改变原有的字符串,都是返回一个结果,在这个新的返回值里,保留了执行后的结果!
len
len函数可以获取字符串的长度。
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(len(mystr)) # 17 获取字符串的长度查找
查找相关的方法,使用方式大致相同,但是略有区别。
1. find
查找指定内容在字符串中是否存在,如果存在就返回该内容在字符串中第一次出现的开始位置索引值,如果不存在,则返回-1.
语法格式:
s.find(sub[, start[, end]]) -> int示例:
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.find('好风光')) # 10 '好风光'第一次出现时,'好'所在的位置
print(mystr.find('你好')) # -1 '你好'不存在,返回 -1
print(mystr.find('风', 12)) # 15 从下标12开始查找'风',找到风所在的位置试15
print(mystr.find('风光',1,10)) # -1 从下标1开始到12查找"风光",未找到,返回 -12. rfind
类似于 find()函数,不过是从右边开始查找。
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.rfind('好')) # 143.index
跟find()方法一样,只不过,find方法未找到时,返回-1,而str未找到时,会报一个异常。
语法格式:
s.index(sub[, start[, end]]) -> int4.rindex
类似于 index(),不过是从右边开始。
练习:
path = 'http://www.baidu.com/imag.e/logo.jpg'
result = path.find(':')
print(result)
result = path.find('/',10)
print(result)
result = path.find('.',20)
print(result)
path= 'http://www.baidu.com/image/logo.html'
result = path.rfind('.')
# print(result)
print(path[result+1:])
print(path[path.rfind('.')+1:])
print(path.rfind('#'))
print(path.find('#'))
print('*'*30)
# print(path[path.rindex('#'):])
print(path[path.rfind('/')+1:])判断
python提供了非常丰富的方法,可以用来对一个字符串进行判断。
1. startswith
判断字符串是否以指定内容开始。 语法格式:
s.startswith(prefix[, start[, end]]) -> bool示例:
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.startswith('今')) # True
print(mystr.startswith('今日')) # False2. endswith
判断字符串是否以指定内容结束。
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.endswith('好风光')) #True
print(mystr.endswith('好日子')) #False3. isalpha
判断字符串是否是纯字母。
mystr = 'hello'
print(mystr.isalpha()) # True
mystr = 'hello world'
print(mystr.isalpha()) # False 因为中间有空格4. isdigit
判断一个字符串是否是纯数字,只要出现非0~9的数字,结果就是False.
mystr = '1234'
print(mystr.isdigit()) # True
mystr = '123.4'
print(mystr.isdigit()) # False
mystr = '-1234'
print(mystr.isdigit()) # False5. isalnum
判断是否由数字和字母组成。只要出现了非数字和字母,就返回False.
mystr = 'abcd'
print(mystr.isalnum()) # True
mystr = '1234'
print(mystr.isalnum()) # True
mystr = 'abcd1234'
print(mystr.isalnum()) # True
mystr = 'abcd1234_'
print(mystr.isalnum()) # False6. isspace
如果 mystr 中只包含空格,则返回 True,否则返回 False.
mystr = ''
print(mystr.isspace()) # False mystr是一个空字符串
mystr = ' '
print(mystr.isspace()) # True 只有空格
mystr = ' d'
print(mystr.isspace()) # False 除了空格外还有其他内容count
返回 str在start和end之间 在 mystr里面出现的次数。
语法格式:
s.count(sub[, start[, end]]) -> int示例:
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.count('好')) # 3. '好'字出现三次替换
替换字符串中指定的内容,如果指定次数count,则替换不会超过count次。
mystr = '今天天气好晴朗,处处好风光呀好风光'
newstr = mystr.replace('好', '坏')
print(mystr) # 今天天气好晴朗,处处好风光呀好风光 原字符串未改变!
print(newstr) # 今天天气坏晴朗,处处坏风光呀坏风光 得到的新字符串里,'好'被修改成了'坏'
newstr = mystr.replace('好','坏',2) # 指定了替换的次数
print(newstr) # 今天天气坏晴朗,处处坏风光呀好风光 只有两处的'好'被替换成了'坏'内容分隔
内容分隔主要涉及到split,splitlines,partition和rpartition四个方法。
split
以指定字符串为分隔符切片,如果 maxsplit有指定值,则仅分隔 maxsplit+1 个子字符串。返回的结果是一个列表。
mystr = '今天天气好晴朗,处处好风光呀好风光'
result = mystr.split() # 没有指定分隔符,默认使用空格,换行等空白字符进行分隔
print(result) #['今天天气好晴朗,处处好风光呀好风光'] 没有空白字符,所以,字符串未被分隔
result = mystr.split('好') # 以 '好' 为分隔符
print(result) # ['今天天气', '晴朗,处处','风光呀,'风光']
result = mystr.split("好",2) # 以 '好' 为分隔符,最多切割成3份
print(result) # ['今天天气', '晴朗,处处', '风光呀好风光']rsplit
用法和split基本一致,只不过是从右往左分隔。
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.rsplit('好',1)) #['今天天气好晴朗,处处好风光呀', '风光']splitlines
按照行分隔,返回一个包含各行作为元素的列表。
mystr = 'hello nworld'
print(mystr.splitlines())partition
把mystr以str分割成三部分,str前,str和str后,三部分组成一个元组
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.partition('好')) # ('今天天气', '好', '晴朗,处处好风光呀好风光')rpartition
类似于 partition()函数,不过是从右边开始.
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.rpartition('好')) # ('今天天气好晴朗,处处好风光呀', '好', '风光')修改大小写
修改大小写的功能只对英文有效,主要包括,首字母大写capitalize,每个单词的首字母大写title,全小写lower,全大写upper.
capitalize
第一个单词的首字母大写。
mystr = 'hello world'
print(mystr.capitalize()) # Hello worldtitle
每个单词的首字母大写。
mystr = 'hello world'
print(mystr.title()) # Hello Worldlower
所有都变成小写。
mystr = 'hElLo WorLD'
print(mystr.lower()) # hello worldupper
所有都变成大写。
mystr = 'hello world'
print(mystr.upper()) #HELLO WORLD八、空格处理
Python为我们提供了各种操作字符串里表格的方法。
1. ljust
返回指定长度的字符串,并在右侧使用空白字符补全(左对齐)。
str = 'hello'
print(str.ljust(10)) # hello 在右边补了五个空格2. rjust
返回指定长度的字符串,并在左侧使用空白字符补全(右对齐)。
str = 'hello'
print(str.rjust(10)) # hello在左边补了五个空格3. center
返回指定长度的字符串,并在两端使用空白字符补全(居中对齐)
str = 'hello'
print(str.center(10)) # hello 两端加空格,让内容居中4. lstrip
删除 mystr 左边的空白字符。
mystr = ' he llo '
print(str.lstrip()) #he llo 只去掉了左边的空格,中间和右边的空格被保留5. rstrip
删除 mystr 右边的空白字符。
mystr = ' he llo '
print(str.rstrip()) # he llo右边的空格被删除6. strip
删除两断的空白字符。
str = ' he llo '
print(str.strip()) #he llo字符串拼接
把参数进行遍历,取出参数里的每一项,然后再在后面加上mystr
语法格式:
S.join(iterable)示例:
mystr = 'a'
print(mystr.join('hxmdq')) #haxamadaq 把hxmd一个个取出,并在后面添加字符a. 最后的 q 保留,没有加 a
print(mystr.join(['hi','hello','good'])) #hiahelloagood作用:可以把列表或者元组快速的转变成为字符串,并且以指定的字符分隔。
txt = '_'
print(txt.join(['hi','hello','good'])) #hi_hello_good
print(txt.join(('good','hi','hello'))) #good_hi_hello字符串内容的配套视频:
宋宋 宁姐 python视频 字符串操作_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
宋宋 宁姐 python视频 字符串操作_哔哩哔哩 (゜-゜)つロ 干杯~-bilibiliwww.bilibili.com
有任何问题关注沟通哦!















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









