




【硬核】肝了一个月,Cisco网络工程师知识点总结
高能预警,本文是我一个月前就开始写的,所以内容会非常长,当然也非常硬核,有实验,有命令,所以才写到了现在。
我相信90%的读者都不会一口气看完的,因为实在太长了,长到我现在15寸的mbp打字编辑框都是卡的,但是我希望大家日后想看Cisco网络工程师或者在面试前需要了解的朋友回头翻一下就够了,那我写这个文章的意义也就有了。
也不多BB,直接开整。
一、OSI模型
中下层是为上层服务的
7# 应用层:用于端到端的通讯(比如两人之间 QQ 通讯,两人之间的系统不一样,因此对数据的加解密方式也不一样,因此需要标准来定义加解密的方式,使得不同系统的应用程序之间能够相互通讯)。
6# 表示层:定义数据的表示,对数据进行加密等处理(要建立会话首先需要连接关系,因此用会话层建立这种连接关系)。
5# 会话层:保证不同应用间数据的区分,建立、管理和终止会话(message 建立连接的时候首先建立虚拟的信道,保证不同的会话能够相互独立,然后结束之后将信道解除,传输的数据较大,将数据切片,然后发送)。
4# 传输层:提供可靠或不可靠的端到端报文的传输和差错控制(TCP,UDP)
(segment 那么发送的报文被切片了,怎么知道我原来传输的内容是怎样的,比如我发送的是:hi,晚上我们一起去吃饭。对端收到之后需要信息对我原来的回话还原,需要一种协议定义,因此对数据进行封装, 找到相对应的应用层的程序,封装之后我们成为 PDU(protocol data unite 协议数据单元):我们把这种在对等层之间交互的信息称为 PDU)。
3# 网络层:将分组从源传送到目的端,提供路由用来决定逻辑寻址 (IP 地址)
( A 怎么知道我要将数据传递到哪里,也就是我怎么知道 B 在哪里,因此我们在原来的包头上封装 IP 地址(源,目 IP
地址),但是网络中有可能有重复的 IP 地址(在局域网中有相同的网段))。
如何查看电脑的 MAC 地址:ipconfig /all
2# 数据链路层:将数据封装成帧,提供节点到节点的传输(Frame 增加一个 2 层的帧头,包括了源目的 MAC 地址,这样就能节约带宽提高网络的可用性,MAC 地址:地址是 48 位的,十六进制表示,前24 位是OUI 分配给不同的tf商,后 24 位tf商自己定义
比如 A-----Router-----Router---- B, A 找不到 B 的具体位置,那么需要更精确的地址来帮助 A 找到 B, 也就是称为 MAC 地址,也就相当于你的名字并不是唯一,但是身份证号码是唯一的 ,A 首先将源,目的IP 地址封装,然后再将源,目的 MAC 地址封装,A 向路由器发送 ARP 查询后,路由器查看自己的路由表, 然后发现这个网段我知道怎么去, 然后告诉 A 可以把数据交给我,我可以帮助你去往目标 IP,于是 A 将在路由器的路由表中查看的下一跳地址的 MAC 地址封装成目标 MAC 地址,然后继续向下发送路由器 2 继续查看自己的路由表,然后再查看自己的路由表,解封装到二层之后发现这个 MAC 地址还不是自己的 MAC 地址,继续解封装,然后这个 IP 地址所在的网段是自己直连的网段,然后查看路由表之后将自己下一跳 IP 地址的 MAC 地址封装,然后向下发送,B 收到之后会解封装,然后匹配自己 MAC 地址,这样完成传输。
1# 物理层:设备间发送和接收比特流(bit)我们在物理设备之间的的传输一般都是脉冲信号, 因此将数据帧转换成 bit( 1byte=8bit), 也就是 010101 的脉冲信号再通过介质传输比特。
v.35 定义的是广域网
网线的接法:
T568A 标准:白绿,绿,白橙,蓝,白蓝,橙,白棕,棕
T568B 标准:白橙,橙,白绿,蓝,白蓝,绿,白棕,棕
二、R&S 主要的是了解OSI 二,三层
具体每层对应的数据类型封装和解封装
还有两台 PC 之间数据的传递过程
一、物理层
设备:集线器、中继器(放大信号)、编码-解码器、传输介质连接器(不同介质之间相互通信)所有的设备在同一个冲突域(冲突和冲突域的概念)
广播域:广播帧传输的网络范围。交换机是属于同一个广播域的,需要用路由器来隔离广播 域,交换机的一个接口是一个冲突域,接到 hub 上,传输到交换机,引入冲突域的概念CSMA/CD(载波侦听多路访问)技术,全双工,半双工,单工通信。
介质参数
| 10base2 | 10M 带宽 | 基带传输 | 传输距离为 185M | 细的同轴电缆 |
|---|---|---|---|---|
| 10base5 | 10M 带宽 | 基带传输 | 传输距离为 500M | 粗的同轴电缆 |
| 10baseT | 10M 带宽 | 基带传输 | 传输距离为 100M | 非屏蔽双绞线 |
| 10baseTX | 10M 带宽 | 基带传输 | 传输距离为 100M | 增强型的双绞线 (可支持超 5 类和 6 类) |
| 10base-F | 10M 带宽 | 基带传输 | 传输距离为 2000M | 光纤 |
二、数据链路层
封装源目的 MAC 地址,比如 A B C 三个都连在一台交换机上,A 如何去往 C 呢,通过 MAC 寻址查询 MAC 地址表,存活时间 300S。
以太网帧格式两种定义:
| 802.3 : | 前导码 | 目标 MAC 地址 | 源 MAC 地址 | 长度 | 数据 | FCS |
|---|---|---|---|---|---|---|
| Byte | 8 | 6 | 6 | 2 | 可变长(46-1500) | 4 |
| EthernetII: | 前导码 | 目标 MAC 地址 | 源 MAC 地址 | 类型 | 数据 | FCS |
| Byte | 8 | 6 | 6 | 2 | 可变长(46-1500) | 4 |
前导码:决定应该收发那个帧,不包含控制信息。
长度:三层数据包的长度是不是满足 MTU(Maximum Transmission Unit 最大传输单元)的标准
MTU:描述三层数据包的长度(最大传输单元不超过 1500byte)。
FCS: 校验和(校验帧头的完整性,md5 算法计算出的帧头是不是跟现在接收的的匹配)
类型:描述三层封装的协议 IPv4 0x0800 类型字段 IPv6 0x86dd 类型字段
以太网丢帧的原因:(帧的大小范围:64~~1518 字节,在trunk 中帧大于 1518 字节不会被丢弃。)
1# 帧小于 64 字节。
2# 帧大于 1518 字节。
3# 校验错误。
交换机的作用:(交换机的每个接口是一个冲突域,本身是一个广播域)
1# 学习 MAC 地址。
2# 转发,过滤数据帧。
3# 防止环路。
三、网络层
IPv4 地址:32 位点分十进制表示,分四段,由网络号和主机号组成。在同一个局域网要在同一个网段,查看自己电脑的 IP 地址
使用掩码界定网络位和主机位
1 代表匹配网络位,0 代表匹配主机位。
PS:IP 地址的主机位配置为全 0 或者全 1 是不可用的(当是全 0 代表网络号,全 1 代表该网段的广播地址)
192.168.1.0 192.168.1.255 可用 IP 地址为 254 个
两个不同的网段之间相互通信 PC1----router----PC2 pc1 和PC2 相互通信,首先找到网关。
路由器上存放的是路由表。(路由表:存放到达目标网段的最佳路由。)
四、传输层:(TCP UDP 两种协议)
TCP_传输控制协议:(可靠的传输协议)
TCP 是面向连接的传输协议,通过三次握手建立连接,通讯完成时要拆除连接,由于 TCP 是面向连接的所以只能用于端到端的通讯,TCP 提供的是一种可靠的数据流服务,采用“带重传的肯定确认”技术来实现传输的可靠性。TCP 还采用一种称为“滑动窗口”的方式进行流量控制,所谓窗口实际表示接收能力,用以限制发送方的发送速度。
UDP_用户数据报协议:(不可靠的传输协议)
UDP 是面向无连接尽力而为的传输协议,UDP 数据包括目的端口号和源端口号信息,由于通讯不需要连接, 所以可以实现广播发送,UDP 通讯时不需要接收方确认,属于不可靠的传输,可能会出现丢包现象,实际应用中要求程序员编程验证。
IP_网际协议:
IP 层接收由更低层发来的数据包,并把该数据包发送到更高层(TCP,UDP),相反同理。IP 数据包是不可靠的,因为 IP 并没有做任何事情来确认数据包是否按顺序发送的或者有没有被破坏,IP 数据包中含有发送它的主机的地址(源地址)和接收它的主机的地址(目的地址)。
TCP/IP:
优点:模块化的结构便于同时开发、升级换代,维护管理。
缺点:各层功能分配不均,功能和服务定义复杂,很难产品化。
1# OSI 是种参考模型,一般用来教学和科研使用,是种国际化的网络标准。
2# 使用较多的是 TCP/IP 模型,是由美国军方开发的。
介绍 TCP/IP 的四层模型:
| application | 应用层: | 包含的是上三层的协议功能,包括可上网的应用程序和协议。 |
|---|---|---|
| transport | 传输层: | 主机到主机。 |
| network | 网络层 | |
| database link physical | 网络接口层 |
TCP/IP 的三次握手过程:
1# A 向 B 发 SYN(同步请求)
2# B 回复 SYN+ACK(同步请求应答,并确认)
3# A 回复 ACK 确认消息,TCP 建立连接
五、应用层的协议:
| HTTP(超文本传输协议) | 基于 TCP 80 | 用来浏览网页 |
|---|---|---|
| HTTPS(安全超文本传输协议) | 基于 TCP 443 | 也是用来浏览网页只是加密了,比较安全 |
| TFTP (简单文件传输协议) | 基于 UDP 69 | 传输小批量的文件一般用于管理设备的 |
| IOS 操作系统以及配置文件 | ||
| DHCP(动态主机配置协议) | 基于 UDP 68 | 让 PC、服务器以及网络设备自动获得地址子网掩码和网关 |
| FTP (文件传输协议) | 基于 TCP 20 21 | 上传和下载大批量的文件“一般 20 用来开通一个虚拟的逻辑信道,连接完成之后,通过 21 端口发送数据流” |
| SMTP(简单邮件传输协议) | 基于 TCP 25 | 用于收邮件 |
| POP3 | 基于 TCP 110 | 用于发邮件 |
| DNS (域名解析服务) | 基于 UDP 53 | 如果一台主机访问 WWW.baidu.com 一般会对应一个 IP 地址,首先向 DNS 服务器询问www.baidu.com 的地址是什么,然后通过解析地址,获得 WWW 的地址。 |
| Telnet (远程登录) | 基于 TCP 23 | 远程管理网络设备 |
| SNMP(简单网络管理协议) | 基于 UDP 161 | 同时管理多台设备 |
| SSH (安全外壳) | 基于 TCP 22 | 加密的远程管理 |
主机到主机层:
添加 TCP 或者 UDP 包头,TCP(最小 20byte)和 UDP(最小 8byte)的数据包长度,窗口机制(TCP 中窗口的大小只能是 2 的 N 次方),到网络层之后会加上 IP 包头。
IP 数据包的格式:
1# 版本(4 bit):0100 标识 IPv4 0110 标识 IPv6
2# 头部长度(4 bit):描述 IP 包头的长度,这个字段可描述 32 字节的最大长度。
3# 服务类型(TOS)实现 QOS 服务质量(8 bit):描述流量的优先级(FIFO 默认)。
4# 标识位(16 bit):表示不同的流量,下载大数据超过 MTU(1500byte)需要分段传输。
5# 标记字段(3 bit)(Flag):第二位为 1 时,表示路由器不能对数据包进行分段。也可用于检测 MTU 值。
6# 分段偏移(13 bit):代表是第几个包偏移量,也就说重组的时候的偏移量,然后逐步还原(根据不同数据包的按着原来的顺序还原)。
7# 生存时间(TTL)(8 bit):初值为 255,每经过一个路由器 TTL 值减 1,直到为 0,就丢弃,防止数据在网络中无休止的传输。
8# 协议(8 bit):表示封装的是协议。协议号:ICMP:1 IGMP:2 TCP:6 PIM: 13 TCP:6 UDP:17 EIGRP:88 OSPF:89
9# 包头校验和:(16 bit)16 位全为 1,表示数据包在传输中没有发生错误。
10# 源地址:32 bit
11# 目标地址:32 bit
11# 目标地址:32 bit
ICMP(网络控制信息协议): echo request(反射请求)和 echo replay (反射回复)
PING(通过 ICMP 协议): 有去有回,用于检测网络的可达性。
ARP 地址解析: MAC 和 IP 的解析根据 IP 地址解析成 MAC 地址
RARP 反向地址解析 从缓存上找到 MAC 地址对应的 IP 地址
VLSM 可变长子网掩码
ARP 表的老化时间是 4 小时
修改老化时间为 1800s
int f0/0
arp timeout 1800
clear arp cache //清理 arp 表所有动态表象
IP 地址分类:IP 地址采用点分十进制表,分成 4 段,每段 8 位。
IP 地址 = 网络号 + 主机号
全 1 表示网络号,全 0 表示主机号
8.8.8.8 谷歌对外开放的域名解析服务器
218.2.131.5 南京 DNS 服务器的 IP 地址掩码:连续的全 1 和连续的全 0。
IP 地址和子网掩码中 1 匹配的网络位,0 匹配的为主机位。
网络号=IP 地址和掩码做与运算
192.168.1.2 255.255.255.0
| 192 | 168 | 1 | 2 |
|---|---|---|---|
| 11000000 | 10101000 | 00000001 | 00000010 |
| 11111111 | 11111111 | 11111111 | 00000000 |
做与运算得出
192.168.1.0 网络号
网段的表示 192.168.1.0/24
PS:IP 地址的主机位配置为全 0 或者全 1 是不可用的
当是全 0 代表网络本身,全 1 代表该网段的广播地址,可用IP 地址为 254 个 。
IP 地址的分类:
| A: 首位固定为 0 | 1-126 | 掩码为 8 位 |
|---|---|---|
| B: 前两位固定为 10 | 128-191 | 掩码为 16 位 |
| C: 首两位固定为110 | 172-223 | 掩码为 24 位 |
| D: 组播,前四位 1110 | 224-239 | |
| E: 科研用(保留) |
特殊的 IP 地址:
1、127 保留,用于本地测试 127.0.0.1
在自己电脑上测试 127.0.0.1 用于本地回环测试
2、全网广播地址,255.255.255.255
3、代表网络本身:0.0.0.0
4、RFC 1918 定义的私有 IP 地址:解决 IP 地址不够用的问题(存在局域网中)
| A 类: | 10.0.0.0 | 10.255.255.255 | 10.0.0.0/8 |
|---|---|---|---|
| B 类: | 172.16.0.0 | 172.31.255.255 | 172.16.0.0/12 |
| C 类: | 192.168.0.0 | 192.168.255.255 | 192.168.0.0/16 |
RFC (一系列以编号排定的文件)用来存放互联网的标准。
合理使用 IP 地址,引入子网划分的概念:
大型网络、中型网络、小型网络每种网络对主机号和网络号需求量不一样,因此需要划分不 同的网络号和主机号来合理利用 ip 地址。
tracert www.cae.com 追踪去往目标 IP 的站点。
172.16.0.0/16 可划分成 4 个子网:
172.16.0.0/18 172.16.64.0/18 172.16.128.0/18 172.16.192.0/18 这个 4 个子网。
VLSM(可变长子网掩码):网络位向主机位借位
CIDR (无类域间路由):主机位向网络位借位,忽略 A B C 类的界定,前缀相同则为同一网段称为超网
不规则子网划分
172.16.0.0/16 划分为两个子网,一个可以容纳 60 台主机,一个可以容纳 280 台主机,如何划分(先划分大的范围,再划分小的范围):
280<512=2^9 那 么 他 的 主 机 位 9 网 络 位 23 也 就 是 网 段 的 范 围 : 172.16.0000000
0.0—172.16.0000000 1.255
172.16.0.0/23 可以为 510 个 IP 地址,加 1 之后也就是下个网段的第一个地址为 172.16.2.0 。
60<64=2^6 那么他的主机位 6 网络位 26 也就是网段范围:172.16.00000010.00 000000------
172.16.00000010.00 111111 172.16.2.0/26 可以为 62 个 IP 地址。
练习:
202.101.12.98/26 的网络号,地址空间和可用 IP 地址范围,如果将其划分成可用容纳相同主机数的 2 子网,如何划分
202.101.12.64 202.101.12.64/26 202.101.12.64--------202.101.12.127
因为划分成 2 个子网,也就是需要向主机位借 1,确定掩码为/27 的
010 00000 64 202.101.12.64/27 的最后一个地址就是 202.101.12.96 010 111111
011 00000 95 202.101.12.96/27 的最后一个地址就是 202.101.12.127 011 111111
子网:202.101.12.64/27 202.101 12.96/27
CISCO 设备的操作
常见的提示符
( > 用户模式对设备简单的查看
进入特权模式 enable
( # 特权模式对设备进行详细的查看
返回用户模式 disable
可缩写,可问号,按 tab 补全
配置:进入配置模式
查看:进入特权模式
Router> //用户模式
Router# //特权模式
先进入导航模式,然后会提示一系列的东西
Continue with configuration dialog? [yes/no]: no
//然后再进入自己配置模式,然后配置密码。
Router#configure terminal // 进入配置模式
Router(configure)# // 配置模式
Router(config)#enable password CISCO 密码明文显示Router(config)#enable secret CCIE 密码密文显示
PS:两种配置密码同时存在的时候加密的优先级较高
RAM:断电之后不在
ROM:断电之后还的
路由器采用了以下几种不同类型的内存,每种内存以不同方式协助路由器工作。
1.只读存储器(ROM)
只读内存(ROM)在 Cisco 路由器中的功能与计算机中的 ROM 相似,主要用于系统初始化等功能。
ROM 中主要包含:
(1)系统加电自检代码(POST),用于检测路由器中各硬件部分是否完好;
(2)系统引导区代码(BootStrap),用于启动路由器并载入 IOS 操作系统;
(3)备份的 IOS 操作系统,以便在原有 IOS 操作系统被删除或破坏时使用。
通常,这个 IOS 比现运行 IOS 的版本低一些,但却足以使路由器启动和工作,ROM 是只读存储器,不能修改其中存放的代码。如要进行升级,则要替换 ROM 芯片。
2.闪存(Flash)
闪存(Flash)是可读可写的存储器,在系统重新启动或关机之后仍能保存数据。Flash 中存放着当前使用中的 IOS。事实上,如果 Flash 容量足够大,甚至可以存放多个操作系统, 这在进行 IOS 升级时十分有用。当不知道新版 IOS 是否稳定时,可在升级后仍保留旧版 IOS, 当出现问题时可迅速退回到旧版操作系统,从而避免长时间的网路故障。
3.非易失性 RAM(NVRAM)
非易失性 RAM(Nonvolatile RAM)是可读可写的存储器,在系统重新启动或关机之后仍能保存数据。由于 NVRAM 仅用于保存启动配置文件(Startup-Config),故其容量较小,通常在路由器上只配置 32KB~128KB 大小的 NVRAM。
同时,NVRAM 的速度较快,成本也比较高。
4.随机存储器(RAM)
RAM 也是可读可写的存储器,但它存储的内容在系统重启或关机后将被清除。和计算机中的RAM 一样,Cisco 路由器中的 RAM 也是运行期间暂时存放操作系统和数据的存储器,让路由器能迅速访问这些信息。RAM 的存取速度优于前面所提到的 3 种内存的存取速度。运行期间, RAM 中包含路由表项目、ARP 缓冲项目、日志项目和队列中排队等待发送的分组。除此之外, 还包括运行配置文件(Running-config)、正在执行的代码、IOS 操作系统程序和一些临时数据信息。
running-config 运行内存里面
startup-config 路由器 nvram 里面
write=copy running-config startup-config //将当前的配置保存在 NVRAM
Router> // 用户模式 由用户模式进入特权模式 Router>enable
Router# //特权模式 由用户特权进入配置模式 Router#conf terminal 先进入导航模式,然后会提示一系列的东西
Continue with configuration dialog? [yes/no]: no //然后再进入配置模式 ,然后配置密码
Router#configure terminal // 进入配置模式
Router(configure)# // 配置模式
Router(config)#enable password CISCO // 密码明文显示
Router(config)#enable secret CCIE // 密码密文显示PS:两种配置密码同时存在的时候加密的优先级较高
实验:
一:路由器的密码配置和恢复
第一步:配置密码
Router(config)#enable secret
第二步:断电重启
ctrl+break 打断正常重启进入 romon 模式或者 ctrl+C 键
第三步:修改寄存器值
rommon 1 > confreg 0x2142
0x2102 开机读配置 (默认寄存器的值)
0x2142 开机不读配置
第四步:重启
rommon 2 > boot 以空配置启动
第五步:进入特权模式
查看当前的配置
show running 之后发现是空的,然后复制原来的配置
Router#copy startup-config
running-config 然后查看当前的配置,查到密码。
第六步:然后删除原来的密码
Router(config)#no enable password 或者 no enable secret
第七步:修改回原来的寄存器值
Router(config)#config-register 0X2102
PS: 可以查看当前寄存器的值(show version) 提 示 :Configuration register is 0x2142 (will be 0x2102 at next reload)
reload 重启动
show version 查看当前的版本Configuration register is 0x2102
三、IOS 灾难恢复
第一步:模拟环境
Router#delete flash:c2600-ipbasek9-mz.124-8.bin //将本地系统文件删除
第二步:重启路由器
Router#reload 进入 ROMMON 模式
第三步: 给服务器配置地址,tftpdnld
rommon 3 > tftpdnld
第四步:从 TFPF 服务器下载 IOS 文件,设置本路由器相关参数
rommon 4 > IP_ADDRESS=192.168.1.1 //设置本路由器 F0/0 接口的 IP 地址
rommon 5 > IP_SUBNET_MASK=255.255.255.0 // 设置子网掩码
rommon 6 > DEFAULT_GATEWAY=192.168.1.200 //服务器的网关(缺省网关随便配置)
rommon 7 > TFTP_SERVER=192.168.1.2 //设置 TFTP 服务器的 IP 地址
rommon 8 > TFTP_FILE=c2600-ipbasek9-mz.124-8.bin//想要从 TFTP 服务器上下载的 IOS 文件名
第四步:再次输入 tftpdnld 开始下载所请求的 IOS 文件 (可打问号查看)
rommon 8 > SET ///////////检查刚才的配置命令
第五步: 重启
rommon 20 > boot / reset
第六步:查看当前的 VERSION(版本) Router>show version
影响局域网性能的两个常见问题是过高的冲突和过多的广播,“分段”将网络分割成较小的段。
交换机:
功能:1、地址的学习 2、帧的转发/过滤 3、防止环路
1# 地址的学习:查看 ARP 表象(ARP -a)
最初开机时 MAC 地址表是空的
最大 mac 地址表可存 1024 个,一旦地址表满, 就会洪泛所有到新 MAC 地址的帧,直到现存地址条目老化为止。
Mac 地址表条目默认老化时间是 300 秒,以下命令可改变老化时间:
switch(config)#mac-address-table aging-time ? <10-1000000>
2# 帧的转发/过滤,交换机形成 MAC 地址表
交换机 A 发送数据帧给主机。
在地址表中有目标主机,数据帧不会泛洪而直接转发。
3# 环 路 的 防 止 , 生 成 树 协 议 STP
VLAN:(虚拟的局域网 virtual LAN)
一个 VLAN = 一个广播域 = 逻辑网段 (子网)
VLAN 实现了网络的有效分段,划分增强了网络的安全性和灵活性。每个逻辑的 VLAN 就象一个独立的物理桥。
交换机上的每一个端口都可以分配给不同的 VLAN。
默认的情况下,所有的端口都属于 VLAN1(Cisco 独有)。
划分不同的 VLAN,使得不同的 VLAN 间不能通信。
Switch#show vlan brief //查看 VLAN 信息
实验1: VLAN的创建于划分
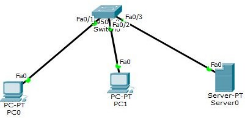
创 建 VLAN :
方法一:
Switch(config)#vlan 10 //创建 VLAN
Switch(config-vlan)#name CCNP //命名为 CCNP
Switch(config)#exit
方法二:
Switch#vlan database //进入 VLAN database 模式
Switch(vlan)#vlan 30 name CCIE //创建 VLAN 并命名为 CCIE Switch(vlan)#exit //退出保存
将接口划入相应的 VLAN :
Switch(config)#int f0/1
Switch(config-if)#switchport mode access //将接口模式改为接入模式Switch(config-if)#switchport access vlan 10 //将接口划入 VLAN 10
一、每个逻辑的VLAN 就像一个独立的物理桥
1# 同一个 VLAN 可以跨越多个交换机
2# 不同的大楼之间相同的 VLAN 想要实现通讯,使用 TRUNK
3# 主干功能支持多个 VLAN 的数据
4# 主干使用了特殊的封装格式支持不同的 VLAN
5# 只有快速以太网端口可以配置为主干端口
二、TRUNK :可以承载多个VLAN 信息的链路
交换机对帧进行 VLAN 标记有两种协议:ISL(Cisco 私有)和 802.1Q(公有)
ISL:在原始以太网帧的头部加了 26 字节的 ISL 头部,尾部加入了 4 字节的 CRC 码,没有破坏原始帧.最大支持 1024 个 vlan。
802.1Q:在原始帧源 MAC 后面(中间还有类型)加 4 个字节 TAG 标记位,对 VLAN 进行标记,破坏了原始帧.最大支持 4094 个 VLAN。
TAG 字段格式:4 字节=32 比特
| 以太类型 | 优先级(priority) | flag(令牌环标识) | VLAN ID |
|---|---|---|---|
| 16bit | 3 比特 | 1 比特 | 12 比特(标记了VLAN ) |
实验2:VLAN创建于划分2
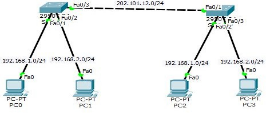
第一步:配置 PC 的 IP 地址(如图)
第二步:交换机上创建 VLAN
Vlan 10
Vlan 20
第三步:将接口划入相应的 VLAN Interface f0/1
SW MO ac
Sw ac Vlan 10 Interface f0/2
SW mo ac
Sw ac vlan 20
第四步:将交换机相连的接口模式改为 TRUNK Int f0/3
sw mo tr
show interface trunk //查看封装形式
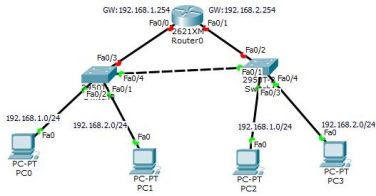
三、实现不同 VLAN 间通信
路由器实现不同 VLAN 间的通信,隔离广播域。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1844
1844


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








