







字典对象的核心是散列表。散列表是一个稀疏数组(老是有空白元素的数组),数组的每一个单元叫作 bucket。每一个 bucket 有两部分:一个是键对象的引用,一个是值对象的引用。全部 bucket 结构和大小一致,咱们能够经过偏移量来读取指定 bucket。下面经过存储与获取数据的过程介绍字典的底层原理。
python
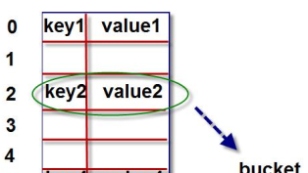
存储数据的过程
例如,咱们将‘name’ = ‘张三’ 这个键值对存储到字典map中,假设数组长度为8,能够用3位二进制表示。shell
>>> map = {}
>>> map
{}
>>> map['name'] = '张三'
一、计算name的散列值。数组
>>> bin(hash('name'))
'0b101011100000110111101000101010100010011010110010100101001000110'
二、用散列值的最右边 3 位数字做为偏移量,即“110”,十进制是数字 6。咱们查看偏移量 6,对应的 bucket 是否为空。若是为空,则将键值对放进去。若是不为空,则依次取右移 3 位做为偏移量,即“000”,十进制是数字0,循环此过程,直到找到为空的 buck
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2806
2806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









