






前面一篇开始学习solr的时候,做了个入门的示例http://blog.csdn.net/zjc/article/details/24414271。虽然可以检索出内容,但总和想象的结果有差异——比如,检索“天龙”两个字,按常规理解,就应该只出来《天龙八部》才对,可是竟然也会把《倚天屠龙记》检出来。后来研究了一下,发现系统是这样处理的:无论是抽索引时还是分析检索词时,都把所有文字按单字拆开。这样,刚好《倚天屠龙记》里包含“天”和“龙”。于是对照solr的配置文件schema.xml做了一些分析和验证。下面来看一下:
在schema.xml里,对检索结果有最直接影响的有这么几项:
这一行在文件较靠后的位置,但我最先拿出来说。这表示,对拆分后的检索词是按照“且”还是“或”的关系选定结果。默认是OR,可以改成AND。象前面例子,如果再有一本《天天向上》,也一样会被检索出来。因为包含了“天”字。那就差的更远了。所以如果采用这个默认的单字拆分法,那最好是用AND,否则结果就太乱了。
好了,假定我们改成了AND,那么结果是《天天向上》没有了,但《倚天屠龙记》还在的。因为既有“天”又有“龙”,说明单字拆分法有不足之处。
决定这个单字拆分法的是谁呢?仔细检查文件,我们发现这一行:
表示name这个字段是text_general类型的。这就靠谱了,多半text_general类型的处理方式就是单字拆分。
有没有更好的分词方法呢,当然有,而且肯定不止一种。我按照网上的例子采用了mmseg4j。使用方法很简单,把解压后的几个jar文件放到classpath目录下。然后在schema.xml里增加下面几行:
这里定义了三种fieldType,分别是textComplex、textMaxWord、textSimple。名称无所谓,重要的是子元素定义了分词器和过滤器使用的类:com.chenlb.mmseg4j.solr.MMSegTokenizerFactory、solr.LowerCaseFilterFactory。其实三种用的类是相同的,只是后面有个mode不同。
这里只是定义了分词类型,我们要把这个分词类型应用到我们的数据里才行。所以,要把 ——我这里改成了textSimple 。在fieldType和fieldname的共同作用下,我们终于可以完成中文习惯上的分词了。当然要重新运行代码,重新抽索引才行,而且字段name里得有东西(参考上一篇的代码)。
搜索“name:天龙”,结果为空。这又是怎么回事呢?难道又错了?其实如果想看分词效果,solr的管理端有个分析工具很好用。
进到分析页面,上面输入字段名称name,下面输入文本,看一下它倒底是怎么分的
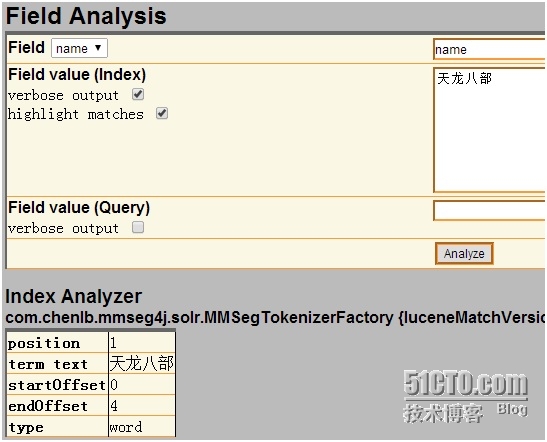
原来textSimple方式把“天龙八部”作为一个整词了,难怪我们搜“天龙”没结果,再搜“天龙八部”,有结果了。晕,这也太不符合习惯了。少字没结果,多字反倒有结果。接着,我们再换一种试试:
name字段用textMaxWord类型,这表示采用最大化分词的方式。再来分析一下:

这回差不多了,“天龙八部”被分成“天龙”“八”“部”三个词。搜索这三个词都有结果了,而且是唯一结果。
换个搜索写法:
不写name:天龙,直接写天龙。晕死,倚天屠龙记又出来了。接着看schema.xml:
text
这表示默认搜索字段,如果前面什么都不写,就到text里去查找。而text怎么定义的呢?再找:
果然,又回到text_general来了,还是单字拆分法。
等等,回忆一下,我们并没有text这个字段啊(参考上一篇代码),我们只录入了三个字段id、name、price,这个text是谁?继续找,在这里——
这几行表示,把cat、name、manu、features、includes都作为text看待(一般是为提供通用检索或简单检索功能用的),text是text_general类型的,还是默认的。所以不写条件时当然又回到单字查找法了。
总结一下:
这5个元素交互作用,最终共同影响着搜索结果。
fieldType:定义了可选的类型,当然定义了未必就用
field:定义了某个字段具体是什么fieldType的
copyField:提供了一个同时查找多个字段的简便方法
defaultSearchField:定义了不写字段条件时的查找范围
solrQueryParser defaultOperator:定义了各分词之间采用什么逻辑组合
原文:http://blog.csdn.net/xiebaochun/article/details/26588113















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









